




 本文深入探讨了Zookeeper作为分布式应用的协作服务,详细解释了其运行模式、ZAB协议、虚拟文件系统及关键特性。阐述了Zookeeper如何通过复制模式确保高可用性和一致性,以及如何利用znode进行数据管理和协调。
本文深入探讨了Zookeeper作为分布式应用的协作服务,详细解释了其运行模式、ZAB协议、虚拟文件系统及关键特性。阐述了Zookeeper如何通过复制模式确保高可用性和一致性,以及如何利用znode进行数据管理和协调。
Zookeeper可以运行在两种模式下,一种是单机模式,单机模式就是只有一个zookeeper service ,这对与测试来讲非常方便,但不能保证服务的高性能和高可靠性;另一种就是复制模式(集群模式),在这种模式下,只要集群中的大多数正常工作,就可以提供稳定的高性能服务,如五个节点的ensemble,任意两个节点失败,服务器仍然可以正常工作,实现原理很简单:确保znode树的每一次修改都被复制到ensemble的大多数机器中。
Zookeeper使用zab协议,运行在两个阶段(状态)[phase]:
Phase1:leader elction
选举一个杰出的组员(一个zookeeper service),称之为leader,其他的机器称之为followers.
Phase2:Atomic broadcast
所有的写请求传递到leader,leader通过广播更新followers。当大多数更改后,leader提交更新,同时client得到响应:更新成功。
如果leader失败,剩下的机器进行另一个leader的选举,如果以前的leader恢复,它将变成一个follower,leader elction非常快,大约200ms,因此,在选举过程中不会是行你呢个显著降低。
除了request processor, 组成zookeeper服务的每个server都会在本地备份其它组件的拷贝. replicated database是一个包含整个数据树的内存数据库.更新被logged到磁盘以提供可恢复性,写操作先持久化到磁盘,然后再对内存数据库作变更.
每个zookeeper server都对client提供服务.client连接到具体的某一个server以提交请求.读操作依赖与每个server的本地数据库.改变服务状态的请求,写操作,由一致性协议来处理.
作为一致性协议的一部分,所有的client写请求被提交到专门的一个leader server. 其余的server,被称为followers,从leader接收消息,并对消息的传递达成一致.
消息层负责替换失效leader并同步followers.zookeeper使用自定义的原子消息传递协议.因为消息传递层是原子性的,zookeeper能够确保本地备份不会出现分歧.When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state.
在使用上,zookeeper的编程接口特意做的非常简单.在此之上,你可以实现更高层次的操作, 如同步原语, 组管理, 所有权等等.
++++++++++++++++++++++++++
2.1 Katta和zookeeper的关系
2.4.1 什么是zookeeper?
zookeeper是针对分布式应用的分布式协作服务,它的目的就是为了减轻分布式应用从头开发协作服务的负担。
它的基本功能是命名服务(naming),配置管理(configuration management),同步(synchronization)和组服务 (group services)。在此基础上可以实现分布式系统的一致性,组管理,Leader选举等功能。
一个zookeeper机群包含多个zookeeper服务器,这些Server彼此都知道对方的存在。 Zookeeper系统结构图如图2所示:
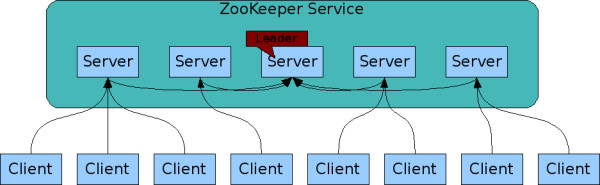
图2 zookeeper系统结构图
l.所有的Server都保存有一份目前zookeeper系统状态的备份;
2.在zookeeper启动的时候,会自动选取一个Server作为Leader,其余的Server都是Follower;
3.作为Follower的Server服务于Client,接受Client的请求,并把Client的请求转交给Leader,由Leader提交请求。
4.Client只与单个的zookeeper服务器连接。Client维护一个持久TCP连接,通过其发送请求, 获取响应和事件,并发送心跳信息。如果Client到Server的TCP连接中断, Client将会连接到另外一个Server。
5.zookeeper机群的鲁棒性是我们使用它的原因,只要不超过半数的服务器当机(如果正常服务的服务器数目不足一半,那么原有的机群将可能被划分成两个信息无法一致的zookeeper服务),该服务就能正常运行。
2.4.2 zookeeper的虚拟文件系统
Zookeeper允许多个分布在不同服务器上的进程基于一个共享的、类似标准文件系统的树状虚拟文件系统来进行协作。虚拟文件系统中的每个数据节点都称作一个znode。每个znode都可以把数据关联到它本身或者它的子节点.如图3所示:
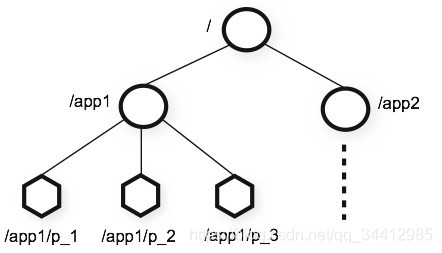
图3 zookeeper的虚拟文件系统目录结构
1.每个znode的名称都是绝对路径名来组成的,如“/katta/index/index_name”等。
2.读取或写入znode中的数据都是原子操作,read会获取znode中的所有字节, write会整个替换znode中的信息.每个znode都包含一个访问控制列表(ACL)以约束该节点的访问者和权限.
3.有些znode是临时节点.临时节点在创建它的session的生命周期内存活, 当其session终止时,此类节点将会被删除.
4.zookeeper提供znode监听器的概念. Client可以在某个znode上设置监听器以监听该znode的变更. 当znode有变更时, 这些Client将会收到通知,并执行预先敲定好的函数。

















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









