



昨天学习了mysql索引的一些浅显的理论, 然后自我分析一下在一张表中, 主键索引的情况下最好存储多少条数据不会影响性能
mysql表存储常见两种存储引擎
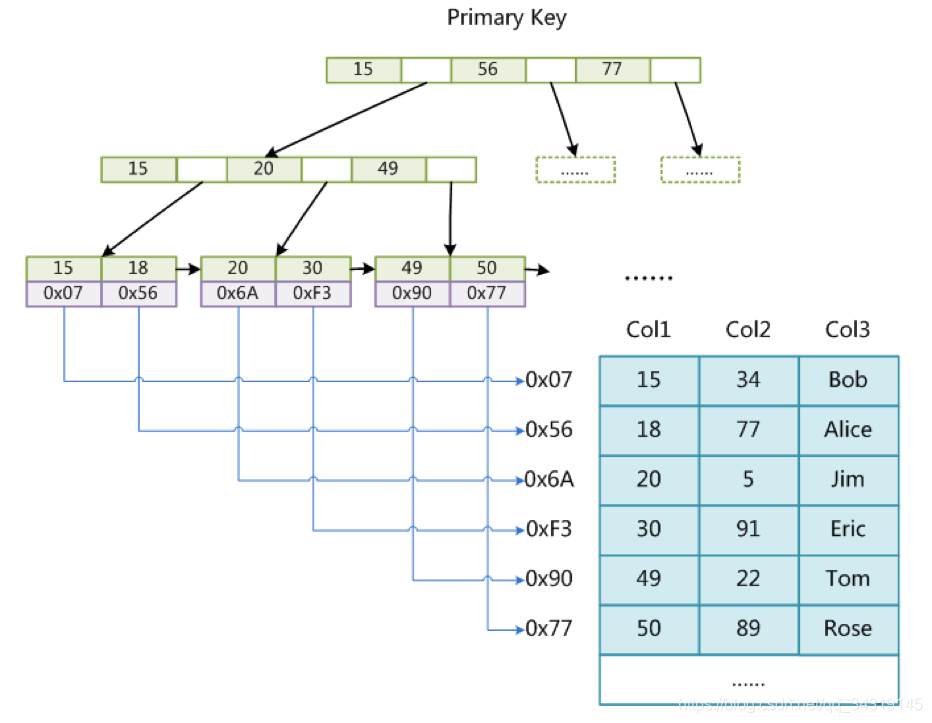
一种是MyISAM引擎(非聚集引擎, 索引和数据分开存, 先找到索引下的数据指针, 再通过指针找到所有的数据)
另一种是InnoDB索引(聚集引擎, 找到索引就找到所有的文件)
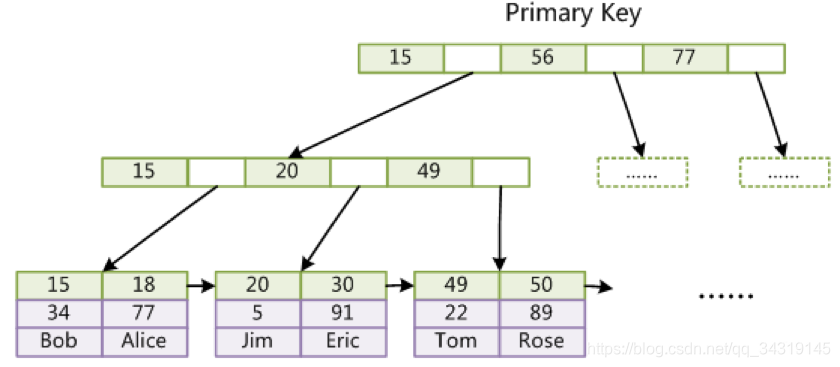
两者的主键索引都是用的B+ tree索引类型,(不知道可不可以修改类型, 非叶子节点值只存储索引, 不存储数据)
二叉树(不自平衡二叉树, 只满足左边叶子节点小于根节点,右边叶子节点大于等于根节点这样插入)
红黑树(自平衡的二叉树, 会自动根据二叉树的基本条件来改变树的结构来保持平衡)
Btree基于红黑树的条件使每个节点能存更多的元素,都是以key-value的形式存储
B+ tree基于Btree的条件 使非叶子节点不存value
基于这个索引 每插入一条数据, 会通过数据的ASCII编码去比较大小, 然后插入到里面, 从左往右依次递增
mysql设定了每个节点16k的大小(原因不是很了解,大概是性能和空间最佳大小)
然后一个索引指针占6B, 现在我们公司用的uuid作为主键id 32个字符也就是64b, 所以说一个节点可以存储 (16*1024)/(6+64)=234个id.
然后一般B+ tree性能最优的是3以下层, 第三层存取索引+数据,
假设一个数据一共1Kb, 所以这样算起来 一共存234*234*16=876096个索引不会影响 select性能的
如果超过了这么多, 节点就会变为4层, 变为4层后就能存储 234*234*234*16=205,006,464 条数据是 查询性能就差不多
一般情况下建议B- tree层数是2-4层, 这样足够查询很多的数据了.
如果超过这个数据就需要考虑分表分库了.
其实B+ tree的用于范围搜索的性能很好, 如果主键用uuid的话基本上范围搜索出来的数据人都无法判断.


















 1014
1014



 到【灌水乐园】发言
到【灌水乐园】发言







