




 本文讲述了如何利用Python爬取今日头条的文章标签。由于新闻分词需求,作者发现今日头条的标签打得最好,因此决定编写一个爬虫,重点解析了获取数据所需的category、max_behot_time和_signature三个参数,并提供了部分代码示例。
本文讲述了如何利用Python爬取今日头条的文章标签。由于新闻分词需求,作者发现今日头条的标签打得最好,因此决定编写一个爬虫,重点解析了获取数据所需的category、max_behot_time和_signature三个参数,并提供了部分代码示例。
最近在做给新闻分词。为了保证给文章贴的标签的准确度高,决定做一个标签库。但发现给新闻打标签网站就只有今日头条打的比较好,网易一般,其他根本不能看,决定写一个爬取今日头条文章标签的爬虫。
一:解析参数
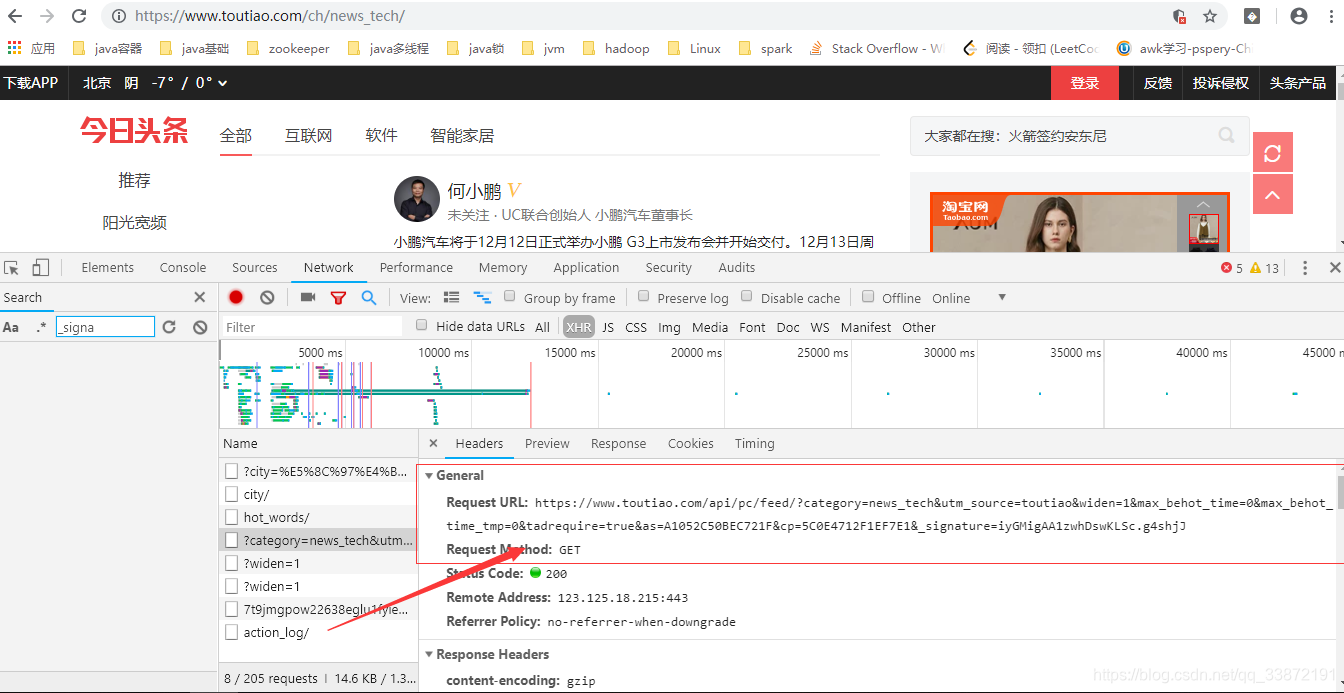 今日头条的数据全部都是ajax异步加载的。谷歌浏览器按f12选择network点击XHR会得到如上图所示,上图请求的url中有如下几个参数会变化:
今日头条的数据全部都是ajax异步加载的。谷歌浏览器按f12选择network点击XHR会得到如上图所示,上图请求的url中有如下几个参数会变化:
① category
② max_behot_time
③ max_behot_time_tmp
④ as
⑤ cp
⑥ _signature
其中只需要category,max_behot_time,_signature这个三个参数就可以获取到数据。这是我自己亲自试验过的。
category根据你请求不同的栏目会变化,比如你请求科技栏目category为news_tech:

请求热点栏目category为news_hot:

max_behot_time会动态变化最开始为0,下一次变化为这次请求到的json数据中max_behot_time的值:
当前max_behot_time请求的json数据中的max_behot_time的值为1544445969
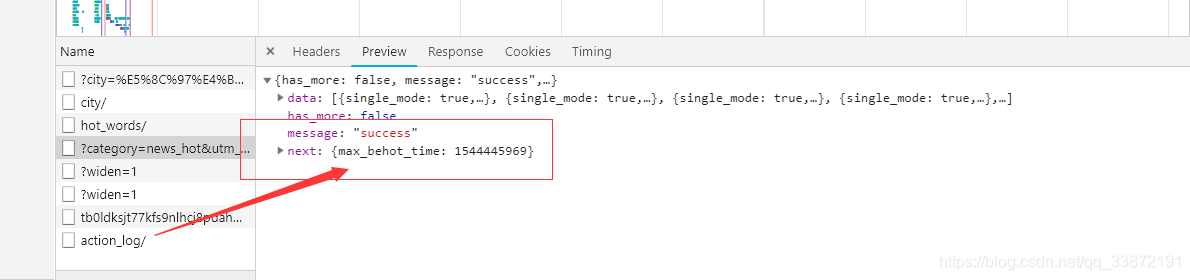
第二次请求的max_behot_time为1544445969。 
第三个参数为_signature,它是由一个很复杂的js代码生成的,这个js代码通过TAC.sign(max_behot_time)来生成,就是上面的那个参数max_behot_time的值:
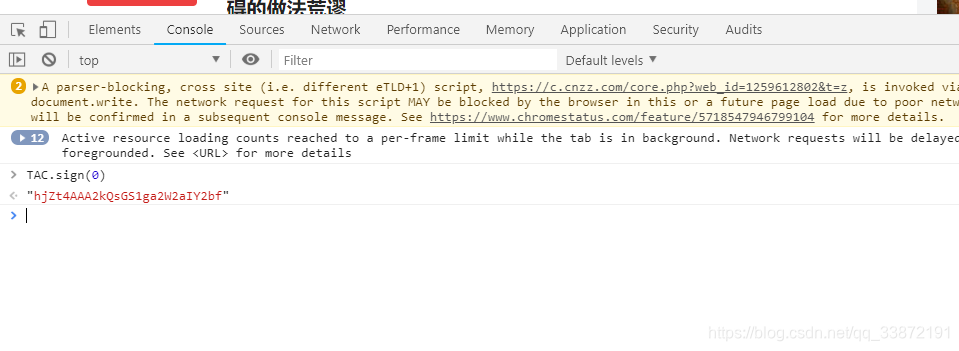

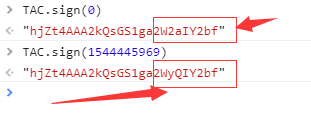
仔细看哦,他们可不是一样的哦。

三个参数到此解析完毕:
接下来就是撸代码,只需复制粘贴,改动一点即可使用。
pacong.py
#coding:utf-8
from selenium import webdriver
from time import ctime,sleep
import threading
import requests
import time
import json
import sys
import random
import Two
reload(sys)
sys.setdefaultencoding('utf-8')
# 进入浏览器设置
def run(ajax):
name = "word-{a}-".format(a=ajax) + time.strftime("%Y-%m-%d") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









