ElasticSearch最佳入门实践(十二)Elasticsearch容错机制:master选举,replica容错,数据恢复
 Elasticsearch故障恢复机制
Elasticsearch故障恢复机制
最新推荐文章于 2023-05-21 15:56:47 发布





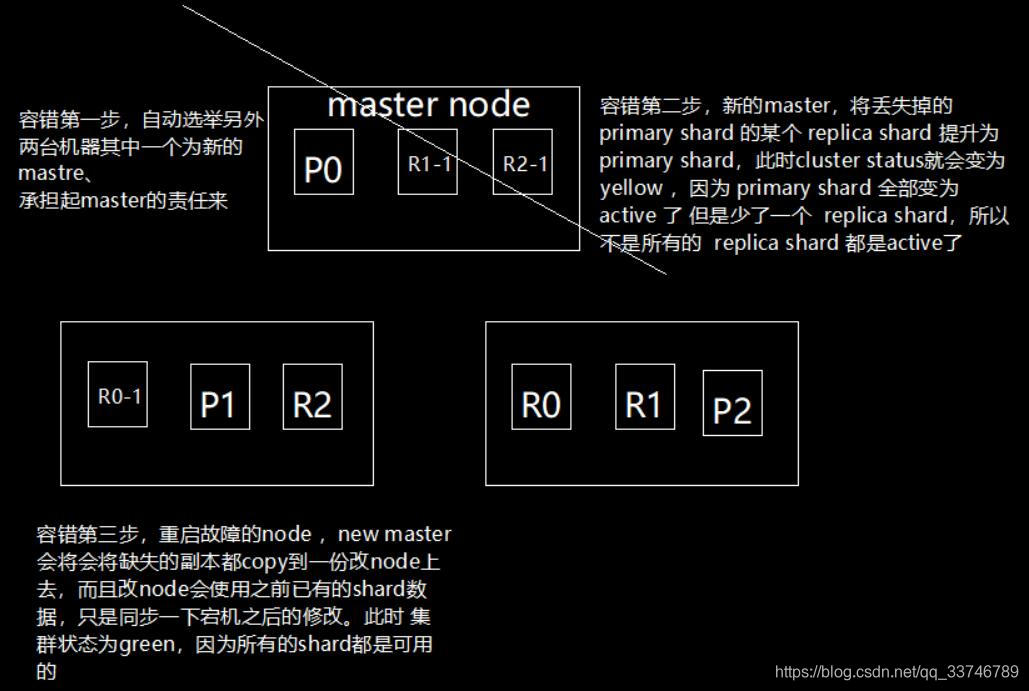
 本文探讨了Elasticsearch在面对节点故障时的自我恢复机制,包括master节点宕机后的自动选举过程,以及如何通过提升副本分片(replica shard)为初级分片(primary shard)来实现容错,最后详细描述了当故障节点重启后,如何从新master节点复制数据并同步更新,确保集群状态恢复正常。
本文探讨了Elasticsearch在面对节点故障时的自我恢复机制,包括master节点宕机后的自动选举过程,以及如何通过提升副本分片(replica shard)为初级分片(primary shard)来实现容错,最后详细描述了当故障节点重启后,如何从新master节点复制数据并同步更新,确保集群状态恢复正常。

















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









