




 本文深入解析了Globally and Locally Consistent Image Completion论文,介绍了其利用global和local discriminator改进image inpainting,提升修复图像的清晰度和对比度。该方法包括completion network、context discriminator,以及训练过程和后处理步骤。虽然能精细复原图像,但若修复大块结构物体,效果不佳。提供了作者的github链接供参考。
本文深入解析了Globally and Locally Consistent Image Completion论文,介绍了其利用global和local discriminator改进image inpainting,提升修复图像的清晰度和对比度。该方法包括completion network、context discriminator,以及训练过程和后处理步骤。虽然能精细复原图像,但若修复大块结构物体,效果不佳。提供了作者的github链接供参考。
一、论文
1、论文思想
上一篇文章提到的Context encode 利用decoder 和encoder 来进行image inpainting,可以修复较大的图像缺失并使得恢复好的图像符合整幅图像的语义,但是修复好的图像存在局部模糊的问题,因此真实图像和利用inpainting 得到的图像肉眼清晰可辨。针对这个问题,SATOSHI IIZUKA 等提出了一个新的想法,即利用global discriminator 和local discriminator 两种判别器保证生成的图像即符合全局语义,又尽量提高局部区域的清晰度和对比度。论文中的网络结构如下:
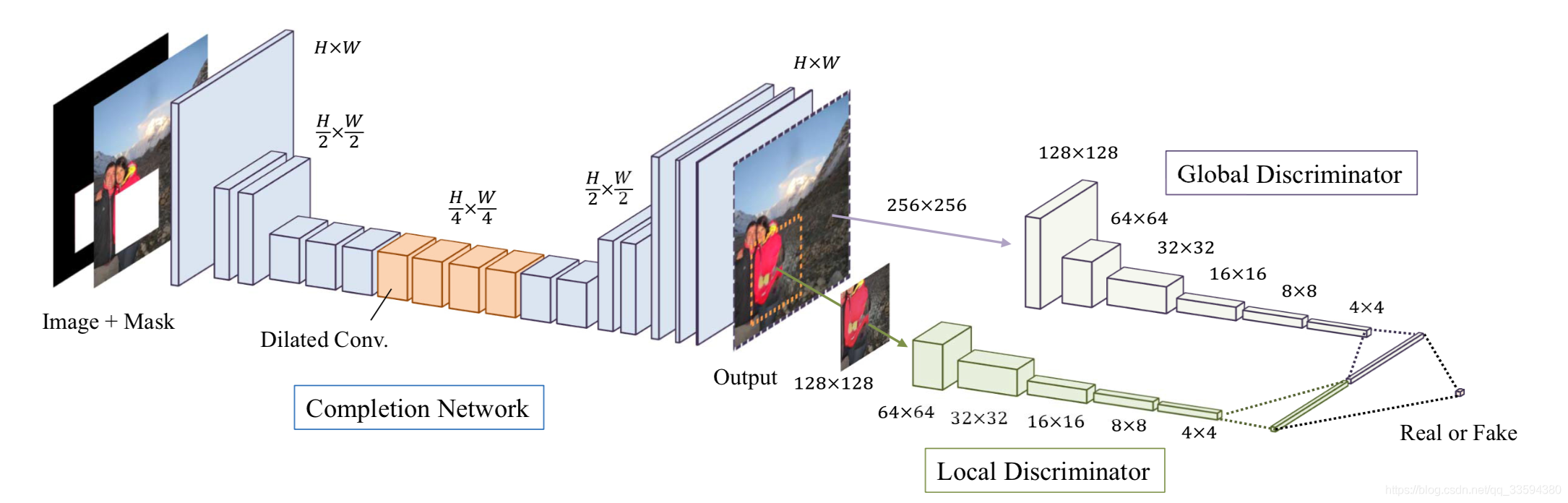
(1)completion network
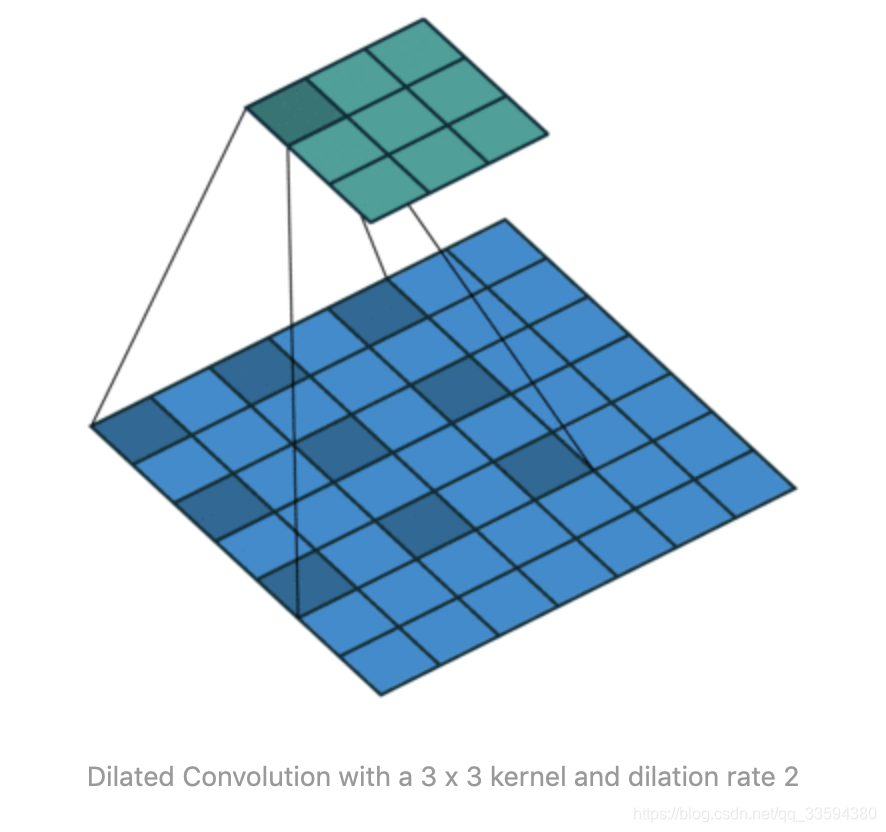
completion network 的主体机构与context encoder 相同,先利用卷积降低图片的分辨率然后利用去卷积增大图片的分辨率得到修复结果。为了保证生成区域尽量不模糊,文中降低分辨率的操作是使用strided convolution 的方式进行的,而且只用了两次,将图片的size 变为原来的四分之一。同时在中间层还使用了dilated convolutional layers 来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
By using dilated convolutions at lower resolutions, the model can effectively “see” a larger area of the input image when computing each output pixel than with standard convolutional layers.
Dilated convolution 的操作一张图就能看明白:
想看动图可以参考:如何理解空洞卷积(dilated convolution)?
(2)Context discriminator
Context discriminator 包含global 和local 两种,global discriminator 把修复好的完整图片作为输入,如果图片较大,会将其resize 成256 × 256,通过多次convolution 和全连接层输出一个1024 维的向量,local discriminator 输入为修复的区域,resize 其大小为128
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 879
879






 到【灌水乐园】发言
到【灌水乐园】发言







