




一、os
os模块是用来与系统交互的,功能十分强大,需要了解的很多,需要熟练运用的也有不少,希望文章能给你们带来帮助
# os模块需要了解的部分
os.getcwd() # 用来获取当前执行脚本工作目录。注意:不一定是脚本所在目录!!
os.chdir('dirname') # 将执行脚本的工作目录更改到传入的参数(目录)下。
# 所以上面说脚本工作目录不一定是脚本所在目录
os.curdir # 返回一个相对目录('.'),点进去看源码可以看到是一个变量,无论在什么地方调用都是返回'.'
os.pardir # 返回一个相对目录('..'),点进去看源码可以看到是一个变量,无论在什么地方调用都是返回'..'
os.makedirs('dirname') # 递归的创建多级目录(也可以创建单级目录)
os.removedirs('dirname') # 从最深层递归的删除多级目录,如遇到目录不为空,停止删除。
os.mkdir('dirname') # 创建一个单级目录
os.rmdir('dirname') # 删除一个单级目录,若目录不为空,则无法删除并报错
os.listdir('dirname') # 列出指定目录下的所有文件与子目录,包括隐藏文件。不传参数默认当前目录。
os.remove('path') # 按照指定路径删除一个文件
os.rename('oldname', 'newname') # 给一个文件重命名,第一个参数是文件原名称,第二个参数是要修改的名称
os.stat('path') # 按照传入的路径获取一个文件或文件夹的信息
os.sep # 获取当前平台的路径分隔符(注意:这里是分隔,是单个路径里面分隔文件夹名称用的)
os.linesep # 获取当前平台的换行符
os.pathsep # 获取当前平台的路径分割符(注意:这里是分割。是分割开两个路径)
os.name # 获取当前操作平台名称 windows为'win', linux与Mac为'posix'
os.system('shell command') # 将传入的命令在终端执行,具有返回值,返回值为0表示正常执行,不为0表示执行出错
os.environ # 获取当前操作系统环境变量
上面是一些需要会用,但是不需要死记的,有需要的时候查一下如何使用就可以,接下来是一个需要熟练掌握运用的
path是os下的一个子模块,功能非常强大,需要我们熟练理解运用。
os.path.dirname('path') # 获取传入路径的上级目录路径
# 举例:如果传入路径为 C:\a\b\c\d.txt,则得到 C:\a\b\c
# 如果传入路径为 C:\a\b\c,则得到 C:\a\b
# 一般使用方式不是传入一个标准路径
# python文件有一个叫做__file__的属性
# 我们将__file__当做参数传入可以获取执行文件所在的路径
# 跨平台性高:我们在windows和linux、Mac的路径是不一样的,但是使用__file__可以准备获取执行文件所在的路径
os.path.basename('path') # 上面的os.path.dirname与这个联用的话就可以得到传入的路径
# 举例:如果传入路径为 C:\a\b\c\d.txt,则得到 d.txt
# 如果传入路径为 C:\a\b\c 则得到 c
# 这个的用处一般是传入一个文件路径直接获取文件名,不常用
os.path.abspath('path') # 可以将传入的路径与当前执行文件的路径拼接成为一个绝对路径
# 例:执行文件路径为:C:\\a\b\c\test.py 传入路径为d\e\g.txt
# 则得到一个绝对路径 C:\\a\b\c\d\e\g.txt
os.path.split('path') # 将传入的路径分为两部分,以元组形式返回
# 例:如果传入C:\\a\b\c\d.txt 得到:(C:\\a\b\c, d.txt)
os.path.join('path1, path2, ...') # 将传入的多个路径组合到一起然后返回
# 注意:第一个绝对路径之前的参数将被忽略
# 注意:如果传入两个绝对路径(盘符),按照第一个为准
os.path.exist('path') # 判断传入的路径是否存在,以布尔值形式返回
os.path.isabs('path') # 判断传入的路径是否为绝对路径,以布尔值形式返回
os.path.isfile('path') # 判断传入的路径是否为一个存在的文件,以布尔值形式返回
os.path.isdir('path') # 判断传入的路径是否是一个存在的路径,以布尔值形式返回
os.path.getatime('path') # 获取传入路径所指向的文件或文件夹的最后存取时间
os.path.getmtime('path') # 获取传入路径所指向的文件或文件夹的最后修改时间
os.path.getsize('path') # 获取传入路径所指向的文件或文件夹的大小
二、sys
sys模块是用来与python解释器交互的
# 获取解释器环境变量
sys.path # 返回一个列表,列表内存储解释器环境变量
# 控制程序退出
sys.exit()
# 可以传入参数
"""
exit([status])
Exit the interpreter by raising SystemExit(status).
通过触发系统退出异常来退出程序
If the status is omitted or None, it defaults to zero (i.e., success).
如果状态值是空,默认为0(退出状态码,类似打开网页时的404)
If the status is an integer, it will be used as the system exit status.
如果状态值是一个整型,该整型将会被用作程序退出的状态码
If it is another kind of object, it will be printed and the system
如果是一个其他类型的对象,将会把传入的参数作为退出状态打印到屏幕
exit status will be one (i.e., failure).
"""
sys.modules
# 获取内存中已加载的模块,返回值为一个字典
sys.version
# 获取解释器版本信息
sys.platform
# 获取操作系统平台名称
# Windows ————> win32
# Linux ————> Linux
# Mac OS X ————> darwin
sys.argv
# 当我们的脚本在命令行(终端)下运行时,sys.argv可以接收一些参数,将参数直接传入到脚本中。
三、random
生产随机数的模块
# 有以下几种用法需要记
random.random() # 无需参数,产生一个大于0小于1的随机浮点数
random.randint(a,b) # 传入两个参数,产生一个大于等于a,小于等于b的随机整数
random.randrange(a,b) # 传入两个参数,产生一个大于等于a,小于b的随机整数
random.choice(['a', 1, [1,2,3], 20]) # 传入一个列表,随机选取列表中的一个元素
random.sample([], a) # 传入一个列表,随机选取列表中的a个元素组成一个元组
random.uniform(a,b) # 传入两个参数,随机产生一个大于等于a,小于等于b的浮点数
以上就是random的常用方法。
四、time与datetime
1. time
从名字我们也可以看出来,time模块是与时间有关的模块。
主要分为三大类:a. 时间戳;b. 结构化时间;c. 格式化字符串时间
# 1. 时间戳
time.time() # 获取时间戳,就是从UNIX元年(1970年1月1日 0:00:00)到现在这一刻所经过的秒数。
# 2. 结构化时间
time.localtime(secs) # 需要一个参数(一个时间戳),该参数有默认值,
#默认获取当前当地时间的一个结构化时间元组
# 该元组包括(年,月,日,时,分,秒,一年的第几天,一周的第几天,夏令时)
time.gmtime(secs) # 与localtime一样,区别在于:gmtime获取的是UTC时区的结构化时间
# 3. 格式化字符串时间
time.strftime('%Y - %m - %d %X') # 按照传入的格式输入当前时间
# 常用占位符
# %Y 年
# %m 月
# %d 日
# %H 小时
# %M 分钟
# %S 秒
# %X 时:分:秒
这三种时间之间存在着转换关系,我们可以通过一定的方式将其转换
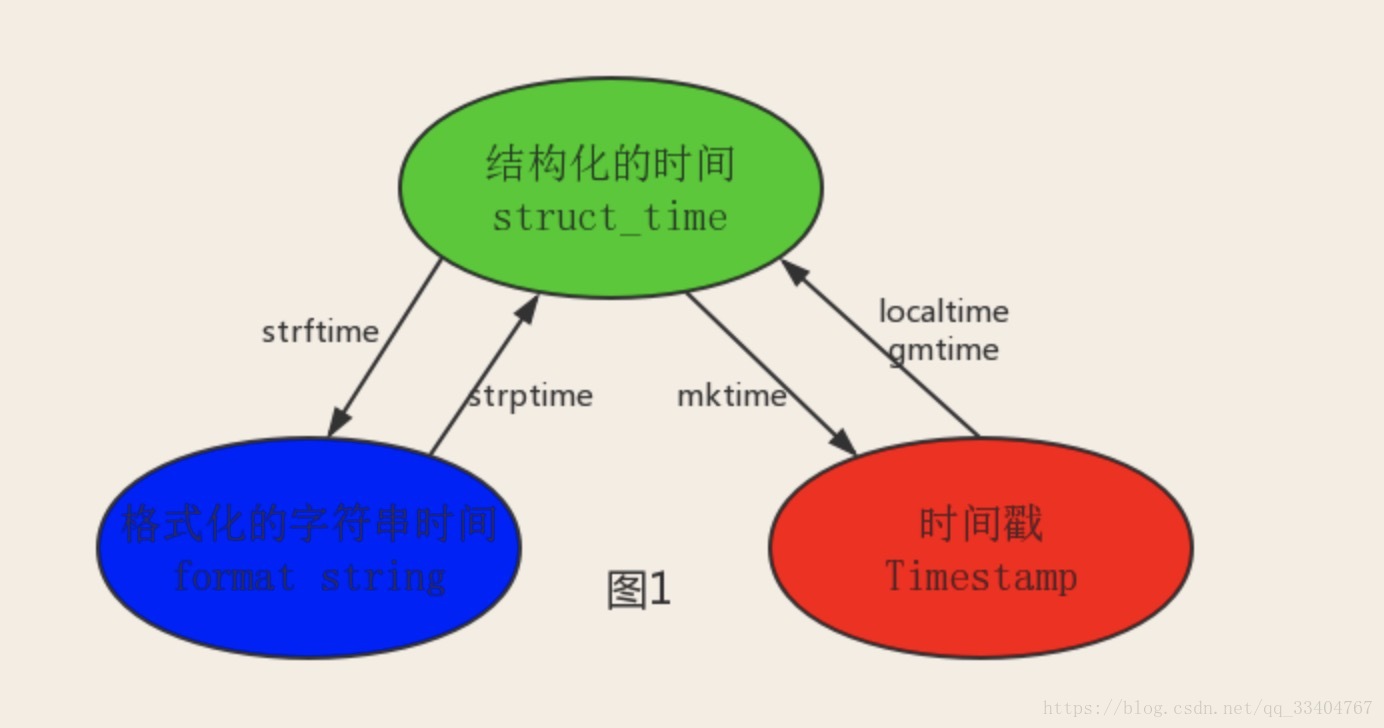
通过上图的方式就可以实现三种时间格式之间的转换。
# 格林威治时间
time.asctime()
time.ctime()
# 两者都是输出格林威治时间,在linux中很常见
# 两者区别: 参数不同
# asctime接收的是一个结构化的时间格式
# ctime接收的是一个时间戳的时间格式
2. datetime
# 获取一个格式化的当前时间
datetime.datetime.now()
# 不需要我们传入格式,会自动帮我们输出一个格式化的时间
# 时间的加减
datetime.datetime.now() + datetime.timedelta()
# 可以实现对时间的加减,timedelta接收关键字参数,按照传入的参数去做相应的加减
# 替换
res = datetime.datetime.now()
res.replace()
# replace接收关键字参数,关键字有day、year等,可以根据传入的参数相应的替换格式化时间的内容
# 格式化时间与时间戳的转换(相对重点)
datetime.date.fromtimestamp(secs)
# 接收一个时间戳,将传入的时间戳转换为一个格式化时间。
五、shutil
shutil模块是一个对文件或文件夹操作的模块,是一种更高级的操作文件,文件夹的方式。
shutil.copyfileobj(fsrc, fdst[, length])
# 将文件内容拷贝到另外一个文件中。
# 就是将fsrc文件中的内容拷贝到fdst中,可以指定拷贝长度
shutil.copyfile(src, dst)
# 拷贝文件,传入的src与dst都必须是文件,不能是文件夹,否则会抛出异常
shutil.copymode(src, dst)
# 仅拷贝权限。内容、组、用户均不变
# Linux同学一定对权限很了解
# 权限码:755 分别是 4:可读 2:可写 1:可执行
# 755代表所属用户可读可写可执行;所属组可读可执行;所有人可读可执行
shutil.copy(src, dst)
# 拷贝文件或文件夹。也就是说传入的路径可以是文件也可以是文件夹
shutil.rmtree(path[, ignore_errors[, onerror]])
# 递归的删除文件,该操作具有一定危险性,慎用
接下来我们讲一下shutil的常用知识:压缩包与解压缩(shutil的重点知识)
压缩:
shutil.make_archive(base_name, format,...)
# 创建压缩包并返回文件路径,例如:zip、tar
# 通常我们只需要指定一个压缩包路径,一个压缩包种类还有一个要压缩的文件路径,下面三个参数一般不传
# 例:
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
# base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
# 如 data_bak =>保存至当前路径
# 如:/tmp/data_bak =>保存至/tmp/
# format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
# root_dir: 要压缩的文件夹路径(默认当前目录)
# owner: 用户,默认当前用户
# group: 组,默认当前组
# logger: 用于记录日志,通常是logging.Logger对象
解压缩:
# 解压缩有三种方式:
# 1.直接用shutil解压缩
shutil.unpack_archive(path)
# 将传入的压缩包文件路径解压缩
# 传入的路径必须是一个压缩包路径
# 2.使用zipfile模块解压缩
import zipfile
z = zipfile.ZipFile('a.zip', 'r')
# 3.使用tarfile模块解压缩
import tarfile
t=tarfile.open('/tmp/a.tar','r')
# 使用下面两种模块必须对应相应的压缩包格式
# 也就是说zip压缩包必须使用zipfile,tar压缩包必须使用tarfile模块
六、json与pickle
为什么要把这两个模块放到一起去将呢,因为这两个模块的功能是很像的,可以说是一模一样的,只有一点点的区别,我们来看一下他们具有什么样的功能,区别在哪儿。
json模块与pickle模块都是用来将数据序列化与反序列化的,那么什么是序列化,又为什么要有序列化呢?
序列化:将内存中的数据永久转换为一种中间格式并持久存储到硬盘或可以用来传输的过程叫做序列化。
反序列化:将硬盘中或者接受到的中间格式的数据加载并用一定方式解析到内存中的过程叫做反序列化。
为什么要有序列化:
(1) 在通信中:当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象序列化为中间格式以后,才能在网络上传送;接收方则需要把中间格式反序列化恢复为对象。
(2)持久存储:我们经常需要将对象(数据)的字段值保存到硬盘中(内存无法持久存储数据),并在以后检索(使用)此数据。尽管不使用序列化也能完成这项工作,但不使用这种方法通常很繁琐而且容易出错,并且在需要跟踪对象(数据)的层次结构时,会变得越来越复杂。可以想象一下编写包含大量对象(数据)的大型业务应用程序的情形,我们(程序员)不得不为每一个对象(数据)编写代码,以便将字段和属性保存至硬盘以及从硬盘还原这些字段和属性。序列化提供了轻松实现这个目标的快捷方法。
json
json是一种支持多语言的序列化方式。json支持以下几种数据格式,分别对应python中的以下数据
| JSON | Python |
|---|---|
| {} | dict |
| [] | list |
| "string" | str |
| 1.2 | int/float |
| true/flase | True/False |
| null | None |
这里需要注意的是:json数据格式中的字符串,必须是用双引号。
json模块下有四个我们常用的方法:load & dump、loads & dumps
load与dump是一组,loads与dumps是一组,都是用来序列化与反序列化的。
我们来看一下示例代码来区别这两组
# 反序列化
with open("a.json","rt",encoding="utf-8") as f:
res = json.loads(f.read())
print(type(res))
with open("a.json",encoding="utf-8") as f:
print(json.load(f))
# 序列化
with open("b.json","wt",encoding="utf-8") as f:
f.write(json.dumps(mydic))
with open("b.json", "wt", encoding="utf-8") as f:
json.dump(mydic, f)
区别:我们可以看到,load与dump只需要打开文件获得一个文件句柄,不需要对其进行进一步操作,但是loads与dumps需要得到文件进一步操作后的结果拿来序列/反序列化。
pickle
pickle模块的使用方法与json一模一样,优点在于pickle支持所有的python格式。但是pickle的缺点也很明显:局限性很强,只适用于python。
两者区别:json适用于多种语言,跨平台性高,pickle是python专属序列化方式,别的无言无法识别pickle。json将数据以字符串的形式存储,pickle将数据以二进制的形式存储。
七、shelve
python独有的轻量级序列化模块,使用方法极其简单
shelve模块比pickle模块简单很多,只有一个open函数,返回一个类似于字典的对象,可以对其进行读、写、修改等操作。‘shelve字典’的key必须是字符串,值可以是python支持的任意数据类型
import shelve
f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'Catalog Spri','age':18,'hobby':['smoking','drinking']}
# f['school_info']={'website':'http://www.pypy.org','city':'shanghai'}
print(f['stu1_info']['hobby'])
f.close() # 使用完毕一定要记得关闭文件
八、XML
XML模块是一个古老的用于跨平台的序列化语言,在json出现之前,人们通常使用XML进行数据序列化。XML的使用及其复杂,所以以后我们使用json来将数据序列化,那为什么我们要学习XML呢,因为还有一些遗留下来的XML文件,我们需要学会碰到XML文件如何去解析该文件。
我们先来了解一下XML的数据格式:
<?xml version="1.0"?>
<data> # 主节点
<country name="Liechtenstein"> # 子节点1
<rank updated="yes">2</rank> # rank:标签名, updated=‘yes’:属性,2:文本内容
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country> # 子节点1结束
<country name="Singapore"> # 子节点2
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country> # 子节点2结束
<country name="Panama"> # 子节点3
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country> # 子节点3结束
</data> # 主节点结束
# xml数据格式
XML模块在python中的使用:
import xml.etree.ElementTree as ET
# 导入模块并起别名
tree = ET.parse("xmltest.xml") # 传入xml文件并将解析结果赋值给一个变量名
root = tree.getroot() # 获取主节点
print(root.tag) # 查看主节点的标签名
#遍历xml文档
for child in root: # 循环遍历子节点
print('========>',child.tag,child.attrib,child.attrib['name'])
# 将子节点的标签名,属性输出到显示屏
for i in child: # 循环遍历子节点下面的各子子节点
print(i.tag,i.attrib,i.text) # 获取子子节点下面的标签名,属性,文本内容
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text) # 将year节点下的标签名与文本内容输出到屏幕
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1 # 更改year的文本内容
node.text=str(new_year)
node.set('updated','yes') # 设定一个属性
node.set('version','1.0')
tree.write('test.xml') # 修改完毕一定要记得写回文件
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country) # 删除一个节点
tree.write('output.xml') # 所有增删改操作都要重新写回文件
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')
XML格式的文件生成不需要刻意了解,因为我们可能真的一点都用不到生成一个XML文件。但是XML语言的数据格式必须了解。


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











