




 本文聚焦NumPy的N维数组对象(ndarray),介绍了其作为大数据容器的特点。详细阐述了创建数组的多种方法,如np.array、np.zeros等;还涉及数据类型转换、数组与标量运算、基本索引与切片(包括浅拷贝、深拷贝)、布尔型索引、花式索引以及数组转置和轴对换等操作。
本文聚焦NumPy的N维数组对象(ndarray),介绍了其作为大数据容器的特点。详细阐述了创建数组的多种方法,如np.array、np.zeros等;还涉及数据类型转换、数组与标量运算、基本索引与切片(包括浅拷贝、深拷贝)、布尔型索引、花式索引以及数组转置和轴对换等操作。
NumPy最重要的特点是其N维数组对象(ndarray),该对象是一个快速而灵活的大数据容器。ndarray是一个通用的同构数据多为容器,其中的所有元素必须是相同类型的。每个数组都有一个shape(表示各维数组大小的元组),一个的type(用于说明数组数据类型的对象)
一、创建数组
np.array([],dtype='float64) 将序列类型变为ndarray
np.zeros() 创建一个全0数组
np.ones() 创建一个全1数组
np.empty() 创建一个没有任何具体值的数组,返回的都是一些未初始化的垃圾值
np.arrange(15) 返回0-14d的数组
np.eye() np.identity() 创建一个单位矩阵
np.ones_like() 以另一个数组为参数,创建形状,dtype一致的全1数组
二、数据类型
astype()可以转换宿主的dtype。调用astype无论如何都会产生一个新数组(可视为原始数组的一份拷贝)。
三、数组和标量之间的运算
arr*arr;arr+arr;arr-arr;1/arr;arr**0.5;
四、基本索引与切片
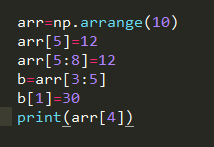
如果只是想得到ndarray切片的一份副本而非视图,arr.copy()进行赋值操作
完全不拷贝
>>> a = np.arange(12)
>>> b = a # 不会创建新的对象
>>> b is a # a和b是同一个ndarray对象的两个名字
True
>>> b.shape = 3,4 # 也会改变a的形状
>>> a.shape
(3, 4)
视图或浅拷贝
不同的数组对象可以共享相同的数据。view方法会创建一个共享原数组数据的新的数组对象。
如果数组A是数组B的视图(view),则称B为A的base(除非B也是视图)。视图数组中的数据实际上保存在base数组中。numpy中对数组切片返回的是其视图
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c is a view of the data owned by a
True
>>> a.flags.owndata # a拥有数据
True
>>> c.flags.owndata # c并不拥有数据
False
>>>
>>> c.shape = 2,6 # a的形状并不随之改变
>>> a.shape
(3, 4)
>>> c[0,4] = 1234 # a的数据也会变
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])
深拷贝
copy方法会对数组和其数据进行完全拷贝。
>>> d = a.copy() # 创建了新的数组和新的数据
>>> d is a
False
>>> d.base is a # d没有和a共享任何数据
False
>>> d[0,0] = 9999
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
布尔型索引
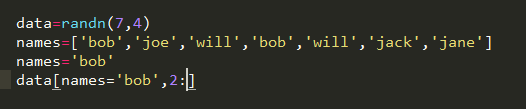
python关键字 and 和 or 在布尔型数组中无效
花式索引
花式索引是NumPy的一个术语,指的是利用整数数组进行索引
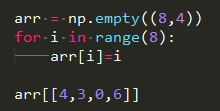
为了以特定顺序选取子集,只需传入一个用于指定顺序的证书列表或者ndarray即可。
数组转置和轴对换
arr.transpose((1,0,2))
np.dot(array.T,array) 求两个矩阵的内积

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









