






一、JVM结构
JVM是可运行Java代码的假想计算机
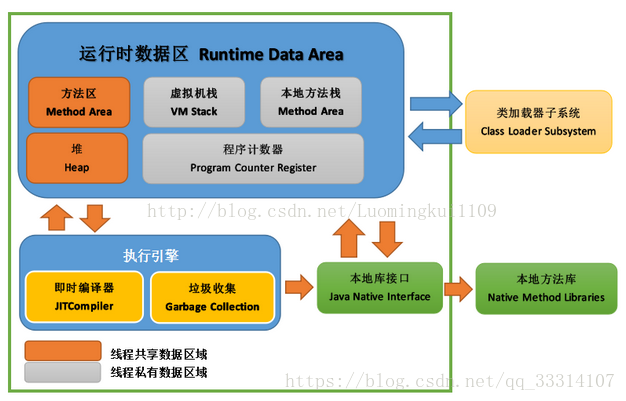
1.1 类加载器
1.2 执行引擎:执行包在装载类的方法中的指令,也就是方法,class文件是否可运行,由执行引擎决定
1.3 本地库接口:融合不同的编程语言为Java所用
1.4 运行数据区
1.4.1 本地方法栈:登记native方法,在Execution Engine执行时加载native libraies
1.4.2 程序计数器:每个线程都有一个程序计算器,就是一个指针,指向下一个将要执行的指令代码,由执行引擎读取下一条指令
1.4.3 方法区:线程共享,存储静态变量、常量、类信息、编译后的字节码
1.4.4 栈:线程私有。主管Java程序的运行。生命周期和线程一致,随线程创建时创建,线程结束栈内存释放,不存在垃圾回收问题。
1)存储:基本类型的变量和对象的引用变量
2)原理:栈中的数据都是以栈帧(Stack Frame)的格式存在,帧用来存储方法的参数、局部变量和运算过程中的临时数据。当一个方法A被调用时就产生了一 个栈帧F1,并被压入到栈中,A方法又调用了B方法,于是产生栈帧F2也被压入栈,B方法又调用了C方法,于是产生栈帧F3也被压入 栈…… 依次执行完毕后,先弹出后进......F3栈帧,再弹出F2栈帧,再弹出F1栈帧。遵循“先进后出”/“后进先出”原则。
1.4.5 堆:线程共享。jvm区域最大。一个jvm实例只存在一个堆类存,存储初始化对象,成员变量
1.4.5.1 新生区:类的诞生、成长、消亡的区域。分为伊甸区和幸存区(分为from区、to区)
1.4.5.2 养老区:保存从新生区筛选出来的 JAVA 对象
1.4.5.3 永久区:存放JDK自身所携带的 Class,Interface 的元数据。垃圾回收主要两部分内容:废弃的常量和无用的类
注意 :Jdk1.6及之前:常量池分配在永久代 。
Jdk1.7:有,但已经逐步“去永久代” 。
Jdk1.8及之后:无(java.lang.OutOfMemoryError: PermGen space,这种错误将不会出现在JDK1.8中),采用了Metaspace
二、类加载机制
2.1 类加载过程
2.2.1 加载:通过全限定名来加载生成class对象到内存中
2.2.2 验证:验证这个class文件,包括文件格式校验、元数据验证,字节码校验等
2.2.3 准备:分配内存,为类变量分配(被static修饰的变量,不包括实例变量,实例变量在对象实例化阶段分配)并设置类变量初始值的阶段,假如public static int value = 123;在准备阶段过后的初始值为0而不是123
2.2.4 解析:将符号引用转化为直接引用(指针引用)
2.2.5 初始化:为类的静态变量赋予正确的初始值,上述的准备阶段为静态变量赋予的是虚拟机默认的初始值,此处赋予的才是程序编写者为变量分配的真正的初始值
主动引用(会发生初始化):
- 遇到new、getstatic、putstatic、invokestatic这4条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。比如以下几种场景:1)、new对象 2)、调用类中的静态成员,除final 3)、调用类中的静态方法
- 使用java.lang.reflect包的方法对类进行反射调用的时候,例如通过调用java.lang.Class.forName(String className)
- 当初始化一个类的时候,如果发现其父类还没进行过初始化,则需要先触发其父类的初始化
- 当虚拟机启动时,用户需要指定一个要执行的主类,虚拟机会先初始化这个主类。 其实就是public static void main(String[] args)所在的那个类 。
被动应用(看上去会,其实不会发生初始化):
- 通过子类引用父类的静态字段,不会导致子类初始化;
- 通过数组定义类引用类,不会触发此类的初始化;
- 静态常量在编译阶段会存入调用类的常量池中,本质上没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化
2.2 双亲委派模型
2.2.1 概念:一个类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载
2.2.2 优点:例如类java.lang.Object,它存在在rt.jar中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的Bootstrap ClassLoader进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,那系统中将会出现多个不同的Object类,程序将混乱
2.2.3 类加载器
- Bootstrap ClassLoader:启动类加载器,负责将$ Java_Home/lib下面的类库加载到内存中(比如rt.jar)
- Extension ClassLoader:标准扩展(Extension)类加载器,它负责将$Java_Home /lib/ext或者由系统变量 java.ext.dir指定位置中的类库加载到内存中
- ApplicationClassLoader:它负责将系统类路径(CLASSPATH)中指定的类库加载到内存中。开发者可以直接使用系统类加载器
2.3 java反射中,Class.forName和classloader的区别
java中class.forName()和classLoader都可用来对类进行加载。class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static代码块和static方法
三、垃圾回收
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中
3.1 GC判定方法
1)引用计数法:指的是如果某个地方引用了这个对象就+1,如果失效了就-1,当为0就会回收但是JVM没有用这种方式,因为无法判定相互循环引用(A引用B,B引用A)的情况
2)根搜索算法:通过一种GC ROOT的对象来判断,如果有一条链能够到达GC ROOT就说明,不能到达GC ROOT就说明可以回收
可以作为GC ROOT的对象有:
1、栈(栈帧中的本地变量表)中引用的对象。
2、方法区中的静态成员。
3、方法区中的常量引用的对象(全局变量)
4、本地方法栈中JNI(一般说的Native方法)引用的对象。
3.2 GC收集方法
1)标记清除:效率不高,会产生碎片
2)复制算法:解决标记清除效率问题,采用8:1的Eden区和survivor区(伊甸区98%对象会死去,没必要1:1),其中Eden和一块Survivor空间用来存放新生代的对象,还有一块用来复制垃圾回收时Eden和另外一块Survivor的存活对象
3)标记整理:解决标记清除算法的内存碎片问题,清理完可回收的对象后会对该内存块进行整理
4)分代收集算法:新生代采用复制算法,老年代采用“标记-清除”或者“标记-整理”算法
它们的区别如下:(>表示前者要优于后者,=表示两者效果一样)
(1)效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
(2)内存整齐度:复制算法=标记/整理算法>标记/清除算法。
(3)内存利用率:标记/整理算法=标记/清除算法>复制算法。
3.3 垃圾收集器
3.3.1 新生代的垃圾收集器
1) Serial收集器(复制算法):缺点是垃圾收集器回暂停用户的所有线程来进行单线程的垃圾收集
2) ParNew收集器(复制算法):Serial的多线程版本,默认开启的线程=CPU核心数,通过使用-XX:ParallelGCThreads参数可以来限制垃圾收集的线程数
3)Parallel Scavenge收集器(复制算法):跟parNew收集器差不多,但与上面2个收集器的关注点不同,前面的2个更多的关注用户的停顿时间,而此收集器更关注CPU的吞吐量(吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)。其中有2个参数可以控制这个吞吐量,1、-XX:MaxGCPauseMillis xxxx,控制最大垃圾收集停顿时间(x>0的毫秒数)。2、-XX:GCTimeRatio XXX,设置吞吐量大小(设置一个0<x<100的整数,表示垃圾收集器时间占总时间的比率,相当于吞吐量的倒数)。 另外,此收集器还有一个参数-XX:+UseAdaptiveSizePolicy,如果打开这个开发,则新生代的大小(-Xmn)、Eden、Survivor(-XX:SurvivorRatio)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等参数就不需要手工指定了,虚拟机会根据系统的运行情况来动态调整。
3.3.2 老年代收集器
1、Serial Old收集器(标记-整理算法):新生代serial的老年代版本,主要有如下2个用途:1、在JDK1.5以及之前的版本搭配新生代的Parallel Scavenge收集器使用。2、作为CMS收集器发生Concurrent Mode Failure的一个后备方案
2.Parallel Old收集器(标记-整理算法):新生代Parallel Scavenge收集器的老年代版本,在JDK1.6的版本中才提供,只能和新生代的Parallel Scavenge收集器搭配使用
3.CMS收集器(标记-清除算法):响应优先。分为初始标记、并发标记、重新标记、并发清除四个过程
优点:以获取最短回收停顿时间为目标的收集器,具有并发低顿挫的特点
缺点:1)对CPU资源很敏感(需要跟用户线程并发执行)
2)无法处理浮动垃圾(Floating Garbage,在标记过程后产生的垃圾),CMS需要预留足够的内存空间给用户线程使用,所以CMS收集器在老年代使用了68%的空间后被激活(可以通过-XX:CMSInitiatingOccupancyFranction参数来配置触发百分比),如果在运行过程中预留的内存无法满足程序需要,则会出现一次“Concurrent Mode Failure”失败并启用后备预案(Serial Old收集器)进行Full GC
3)采用标记-清除算法,会产生内存碎片,不过可以配置-XX:+UseCMSCompactAtFullCollection开关让Full GC后进行一次碎片整理,也可以使用-XX:CMSFullGCsBeforeCompaction来设置执行多少次Full GC自动来一次碎片整理。
4.G1收集器:吞吐量优先。在JDK1.6_update14提供试用,是一款面向服务器应用的垃圾收集器
特点:1)并发运行 2)基于标记-整理算法,不会产生空间碎片
3)非常精确的控制停顿,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在收集上的时间不超过N毫秒
4)将整个堆(新生代、老年代)划分为多个大小固定的独立区域,并与这些区域为单位进行垃圾回收,避免对整个堆进行全量回收操作,并对这些区域进行优先级维护和回收
四、JVM调优
4.1 常用参数设置:
4.1.1 堆设置
- -Xmx3550m:设置JVM最大堆内存为3550M。
- -Xms3550m:设置JVM初始堆内存为3550M。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
- -Xss128k:设置每个线程的栈大小。JDK5.0以后每个线程栈大小为1M,之前每个线程栈大小为256K。应当根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。需要注意的是:当这个值被设置的较大(例如>2MB)时将会在很大程度上降低系统的性能。
- -Xmn2g:设置年轻代大小为2G。在整个堆内存大小确定的情况下,增大年轻代将会减小年老代,反之亦然。此值关系到JVM垃圾回收,对系统性能影响较大,官方推荐配置为整个堆大小的3/8。
- -XX:NewSize=1024m:设置年轻代初始值为1024M。
- -XX:MaxNewSize=1024m:设置年轻代最大值为1024M。
- -XX:PermSize=256m:设置持久代初始值为256M。
- -XX:MaxPermSize=256m:设置持久代最大值为256M。
- -XX:NewRatio=4:设置年轻代(包括1个Eden和2个Survivor区)与年老代的比值。表示年轻代比年老代为1:4。
- -XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的比值。表示2个Survivor区(JVM堆内存年轻代中默认有2个大小相等的Survivor区)与1个Eden区的比值为2:4,即1个Survivor区占整个年轻代大小的1/6。
- -XX:MaxTenuringThreshold=7:表示一个对象如果在Survivor区(救助空间)移动了7次还没有被垃圾回收就进入年老代。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代,对于需要大量常驻内存的应用,这样做可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代存活时间,增加对象在年轻代被垃圾回收的概率,减少Full GC的频率,这样做可以在某种程度上提高服务稳定性。
疑问解答:-Xmn,-XX:NewSize/-XX:MaxNewSize,-XX:NewRatio 3组参数都可以影响年轻代的大小,混合使用的情况下,优先级是什么?
如下:
- 高优先级:-XX:NewSize/-XX:MaxNewSize
- 中优先级:-Xmn(默认等效 -Xmn=-XX:NewSize=-XX:MaxNewSize=?)
- 低优先级:-XX:NewRatio
推荐使用-Xmn参数,原因是这个参数简洁,相当于一次设定 NewSize/MaxNewSIze,而且两者相等,适用于生产环境。-Xmn 配合 -Xms/-Xmx,即可将堆内存布局完成。
-Xmn参数是在JDK 1.4 开始支持。
4.1.2 收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
4.1.3 垃圾回收统计信息
-XX:+PrintGC:输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails:输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps:可与上面两个混合使用,输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-Xloggc:filename:把相关日志信息记录到文件以便分
4.2 调优总结
年轻代大小选择
响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
养老代大小选择
响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
1. 并发垃圾收集信息
2. 持久代并发收集次数
3. 传统GC信息
4. 花在年轻代和年老代回收上的时间比例
减少年轻代和年老代花费的时间,一般会提高应用的效率
吞吐量优先的应用
一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
较小堆引起的碎片问题
因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:
1. -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
2. -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
案例一:大型网站服务器案例
承受海量访问的动态Web应用
服务器配置:8 CPU, 8G MEM, JDK 1.6.X
参数方案:
-server -Xmx3550m -Xms3550m -Xmn1256m -Xss128k -XX:SurvivorRatio=6 -XX:MaxPermSize=256m -XX:ParallelGCThreads=8 -XX:MaxTenuringThreshold=0 -XX:+UseConcMarkSweepGC
案例二:内部集成构建服务器案例
高性能数据处理的工具应用
服务器配置:1 CPU, 4G MEM, JDK 1.6.X
参数方案:
-server -XX:PermSize=196m -XX:MaxPermSize=196m -Xmn320m -Xms768m -Xmx1024m
4.3 调试工具
常用的几种内存调试工具(jdk自带,位于bin目录下):jmap、jstack、jconsole、jhat
详情访问 https://blog.youkuaiyun.com/qq_33314107/article/details/81045318
五、问题总结
1、进入老年代的几种途径
1)、在新生代GC过程中survivor空间不够,通过老年代的分配担保机制提前转入老年代。
2)、超过参数PretenureSizThreshold设置的值的大对象直接进入老年代,所谓大对象就是需要大量连续内存空间的java对象(例如很长的字符串和大数组)。
3)、长期存活的新生代对象进入老年代,如果对象在一次Minor GC(新生代GC)后仍存活并且能被survivor容纳后被移动到Survivor中后将该对象的年龄+1,当它的年龄达到一定程 度(默认15)后就会晋升到老年代,这个阀值可以通过-XX:MaxTenuringThreshold来设置。
4)、虚拟机并不总要求对象达到XX:MaxTenuringThreshold的值后才晋升老年代,如果在Survivor空间中相同年龄所有对象大小总和大于Survivor空间的一半,年龄大于或者等于 该年龄的对象就可以直接进入老年代。
2、 如果出现java.lang.OutOfMemoryError: Java heap space异常,说明Java虚拟机的堆内存不够。原因有二:
a.Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
b.代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
如果出现java.lang.OutOfMemoryError: PermGen space,说明是Java虚拟机对永久代Perm内存设置不够。原因有二:
a. 程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用。
b. 大量动态反射生成的类不断被加载,最终导致Perm区被占满。
3、几种常用的内存调试工具:jmap、jstack、jconsole、jhat;例如当出现了内存溢出时,可以用jmap看内存情况,然后用 jstack主要用来查看某个Java进程内的线程堆栈信息
4.分派:分派是多态性的体现。分为静态分派、动态分派。重载属于静态分派,重写属于动态分派
5. g1和cms区别,吞吐量优先和响应优先的垃圾收集器选择
CMS收集器:一款以获取最短回收停顿时间为目标的收集器,是基于“标记-清除”算法实现的,分为4个步骤:初始标记、并发标记、重新标记、并发清除。
G1收集器:面向服务端应用的垃圾收集器,过程:初始标记;并发标记;最终标记;筛选回收。整体上看是“标记-整理”,局部看是“复制”,不会产生内存碎片。
吞吐量优先的并行收集器:以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
响应时间优先的并发收集器:保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。
6. 说一说你对环境变量classpath的理解?如果一个类不在classpath下,为什么会抛出ClassNotFoundException异常,如果在不改变这个类路径的前期下,怎样才能正确加载这个类?
classpath是javac编译器的一个环境变量。它的作用与import、package关键字有关。package的所在位置,就是设置CLASSPATH当编译器面对import packag这个语句时,它先会查找CLASSPATH所指定的目录,并检视子目录java/util是否存在,然后找出名称吻合的已编译文件(.class文件)。如果没有找到就会报错! 动态加载包
7.内存溢出和内存泄漏的区别:
内存溢出:是指内存不足 内存泄漏:是指无法释放已申请的内存空间
8.java对象的四种引用:
1)强引用:创建一个对象并把这个对象赋给一个引用变量, 只要强引用还在,永远不会回收
public class Main {
public static void main(String[] args) {
new Main().fun1();
}
//语句1、2、3都属于强引用,当程序运行到语句3,内存不过时,jvm会抛出oom异常,不会垃圾回收,只有fun1()方法运行完,才可以回收。
可以设置值为null,jvm会在合适的时间回收
public void fun1() {
Object object = new Object(); //语句1
Object object = "fdfdfd"; //语句2
Object[] objArr = new Object[1000]; //语句3
} 2)软引用:非必需对象。内存不足时,进行回收 。主要用于缓存
MyObject aRef = new MyObject(); //强引用
ReferenceQueue queue = new ReferenceQueue(); //用来管理SoftReference对象,避免大量SoftReference对象回收之后带来的内存泄漏
SoftReference aSoftRef=new SoftReference(aRef,queue); //软引用
aRef =null;
aRef =aSoftRef.get();//在垃圾回收aSoftRef对象时,SoftReference类所提供的get()方法返回Java对象的强引用。回收之后,返回null3)弱引用:非必须对象。只要jvm进行垃圾回收,就会回收被弱引用的对象。
public class test {
public static void main(String[] args) {
WeakReference<People>reference=new WeakReference<People>(new Strinng("zhouqian"));//这里也可以跟ReferenceQueue结合使用
//String str =new Strinng("zhouqian"); //语句1
//WeakReference<People>reference=new WeakReference<People>(str); //语句2
System.out.println(reference.get()); //返回zhouqian
System.gc();//通知GVM回收资源
System.out.println(reference.get()); //返回null
}
假设是语句1和语句2这种写法,弱引用和强引用结合,被引用对象不会被回收,返回都是zhouqian
}4)虚引用:在任何时候都可能被垃圾回收器回收。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class Main {
public static void main(String[] args) {
ReferenceQueue<String> queue = new ReferenceQueue<String>();
PhantomReference<String> pr = new PhantomReference<String>(new String("hello"), queue);
System.out.println(pr.get()); //通过get()方法,得到的永远是null
}
//虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之 关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









