




 本文档详细介绍了Hive的配置步骤,包括编辑`hive-env.sh`和`hive-site.xml`文件,设置Hadoop路径及数据库连接信息。此外,还展示了Hive的启动方式,如通过`hiveserver2`和`beeline`进行连接。文中给出了Hive创建单分区和多分区表的语法,并演示了如何加载数据。最后,讨论了如何启用分桶并创建分桶表,以及数据导入的过程。
本文档详细介绍了Hive的配置步骤,包括编辑`hive-env.sh`和`hive-site.xml`文件,设置Hadoop路径及数据库连接信息。此外,还展示了Hive的启动方式,如通过`hiveserver2`和`beeline`进行连接。文中给出了Hive创建单分区和多分区表的语法,并演示了如何加载数据。最后,讨论了如何启用分桶并创建分桶表,以及数据导入的过程。
- Hive 启动
0. cp hive-env.sh.template hive-env.sh
1. vim hive-env.sh
2. export HADOOP_HOME=/data/module/hadoop-2.7.2
3. :wq
4. vim hive-site.xml
5.
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.41.8:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
6. :wq
- Hive 启动方式
方式一:
./bin/hive
方式二:
./bin/hiveserver2
注意方式二链接方式:
./bin/beeline
beeline> ! connect jdbc:hive2://hadoop01:10000
Enter username for jdbc:hive2://hadoop01:10000: root
Enter password for jdbc:hive2://hadoop01:10000: ***
- 建表语法【单分区】示例:
create table t_t3(id int,name string) partitioned by (type string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
- 加载【单分区】数据示例:
LOAD DATA local INPATH '/data/module/apache-hive-1.2.2-bin/hivedata/2.txt' INTO TABLE t_t3 partition(type='china');
- 【多分区】示例:
create table t_t4 (id int, name string) partitioned by (dt string, hour string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 加载【多分区】数据示例:
LOAD DATA local INPATH '/data/module/apache-hive-1.2.2-bin/hivedata/2.txt' INTO TABLE t_t4 partition(dt='2020-07-08',hour='09');
-
效果展示:
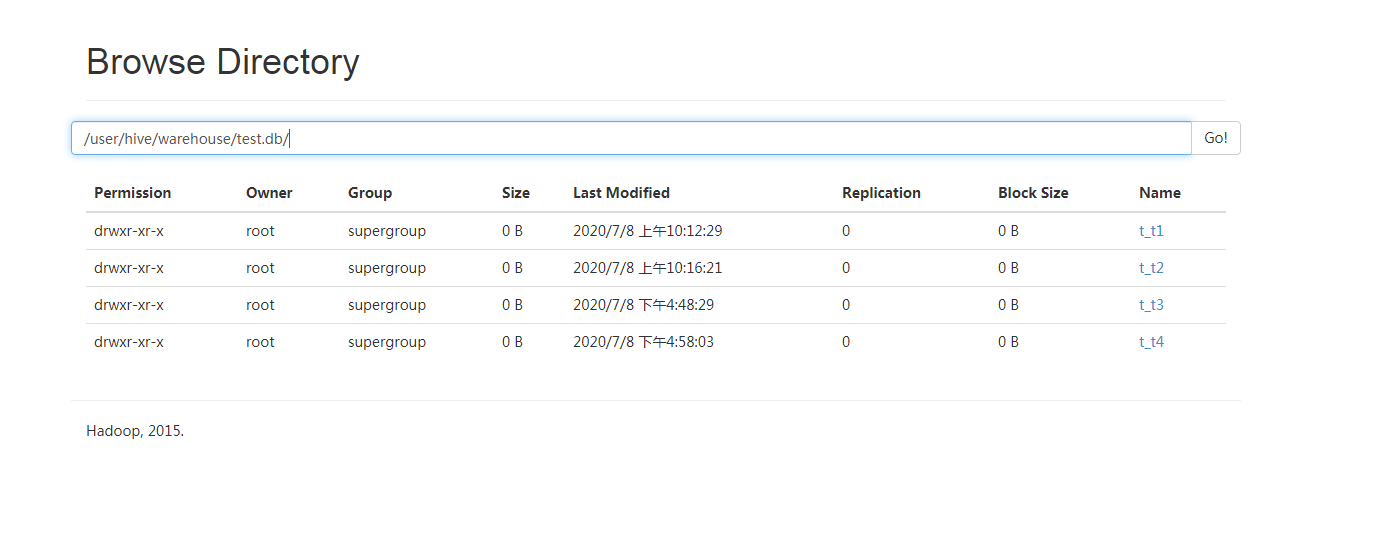
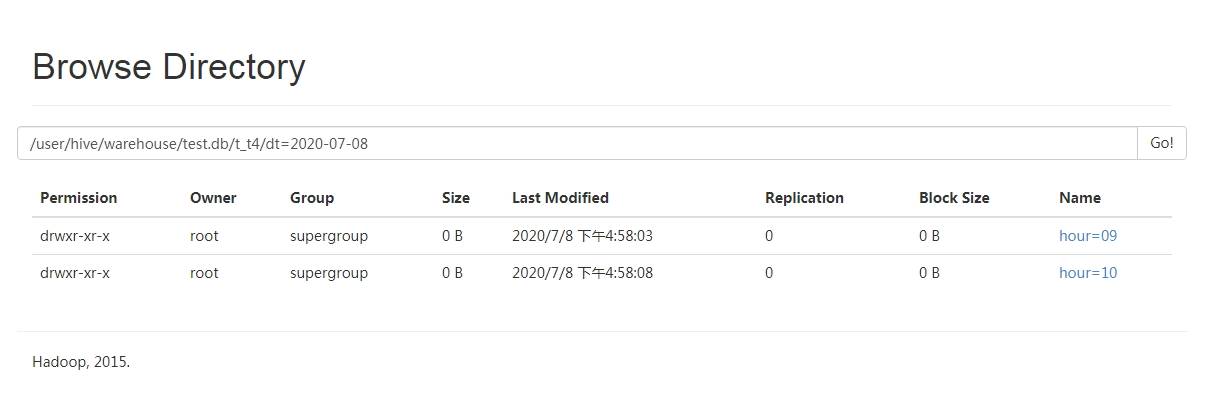
-
指定开启分桶
set hive.enforce.bucketing = true;
#分桶个数
set mapreduce.job.reduces=4;
# 创建分桶表
create table t_t5 (id int, name string)
clustered by(id)
into 4 buckets
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
#创建临时表-数据导入
create table t_t6 (id int, name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
#先进行 mr 程序,在 插入到分桶表
insert overwrite table t_t5 select * from t_t6 cluster by(id);
- 效果展示:

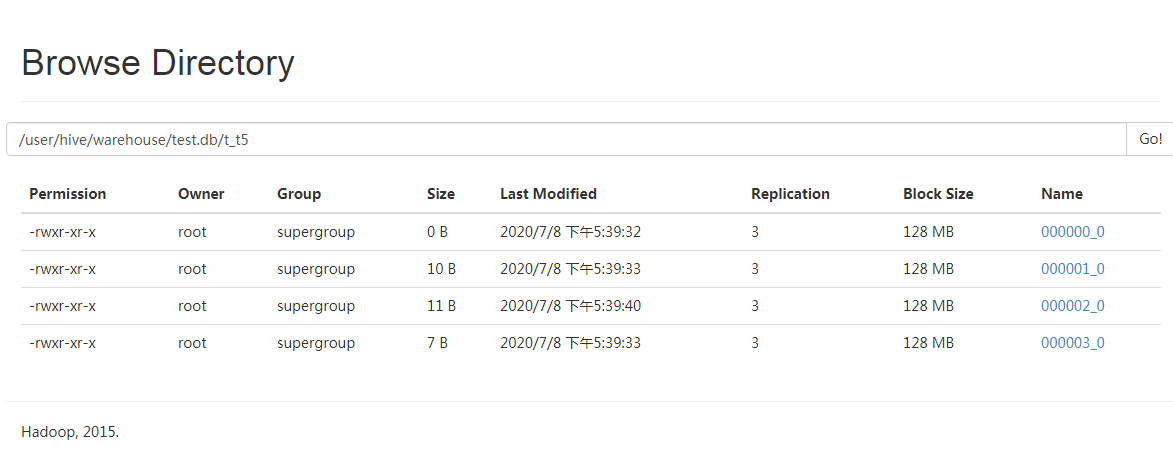

















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









