




 这篇博客详细介绍了如何在三台服务器上配置和启动Hadoop的完全分布式模式,包括HDFS和YARN组件的配置,如NameNode、DataNode、SecondaryNameNode、NodeManager和ResourceManager的设置。配置完成后,通过jps命令检查服务状态,并使用浏览器访问HDFS的Web UI进行监控。
这篇博客详细介绍了如何在三台服务器上配置和启动Hadoop的完全分布式模式,包括HDFS和YARN组件的配置,如NameNode、DataNode、SecondaryNameNode、NodeManager和ResourceManager的设置。配置完成后,通过jps命令检查服务状态,并使用浏览器访问HDFS的Web UI进行监控。
hadoop学习笔记 - HDFS - 完全分布式模式
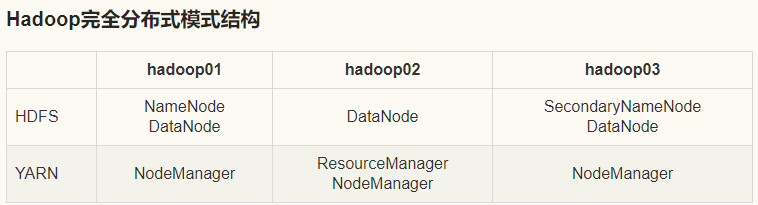
Hadoop完全分布式模式结构
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
准备工作:
- 3台服务器
- Jdk环境
- SSH配置
- Hadoop安装
配置hadoop01的core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
<description>namenode上传到hadoop的临时文件夹</description>
</property>
</configuration>
配置hadoop01的hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本个数,默认配置是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
配置hadoop01的yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置hadoop01的mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
配置hadoop01的slaves,不要出现多余空格、换行
hadoop01
hadoop02
hadoop03
同步hadoop01上 etc/hadoop/下面的配置文件到hadoop02、hadoop03
- scp
- xsync
- 两种方式自选
启动
bin/hdfs namenode -format
sbin/start-dfs.sh #需要在hdoop01启动
sbin/start-yarn.sh #需要在hadoop02启动
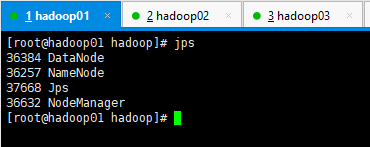
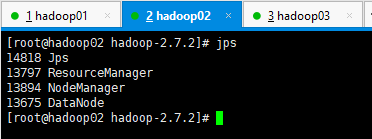
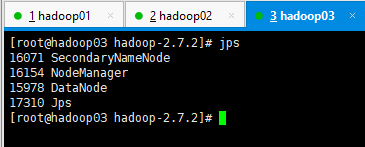
jps 查看我们的服务结构
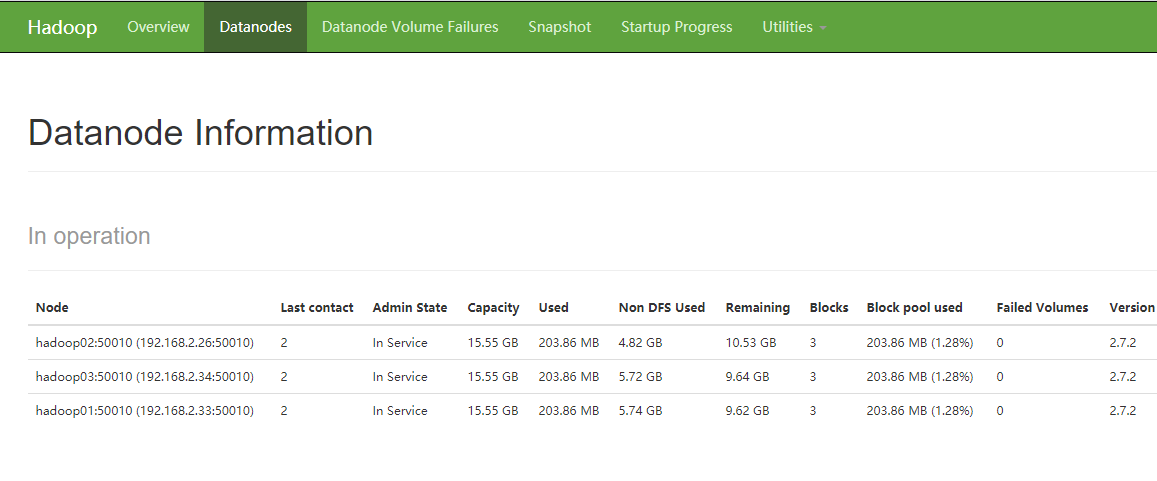
浏览器访问
http://hadoop01:50070/dfshealth.html#tab-overview


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









