




 本文探讨了RDD(弹性分布式数据集)的计算模型,包括任务(Task)的设计思路与数据流动方式。提出了针对RDD分区的不同计算策略,并通过一个具体示例说明了从原始数据到最终结果的整个计算过程。
本文探讨了RDD(弹性分布式数据集)的计算模型,包括任务(Task)的设计思路与数据流动方式。提出了针对RDD分区的不同计算策略,并通过一个具体示例说明了从原始数据到最终结果的整个计算过程。
物理图的意义
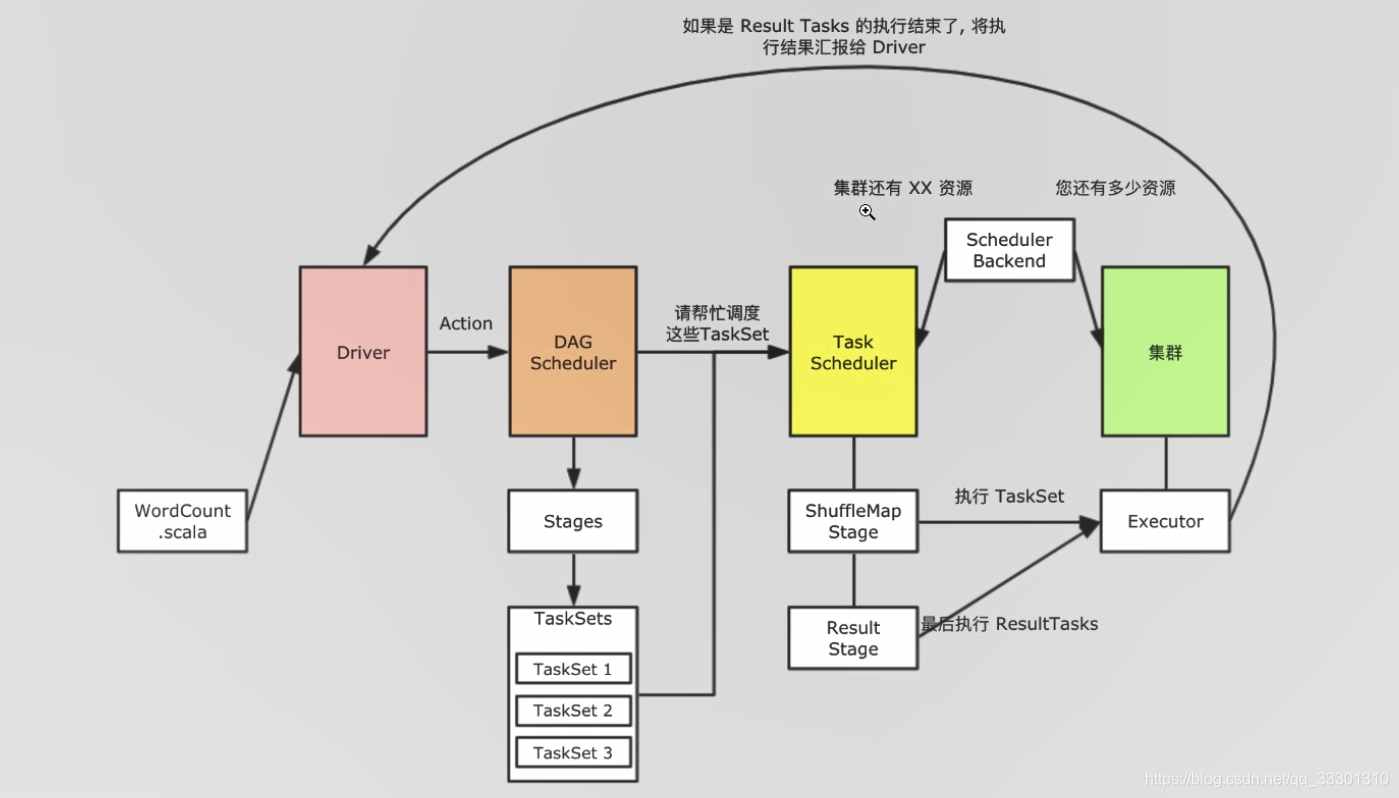
谁来计算RDD呢
Task
Task如何设计
1 . 第一个想法,每个RDD 的每个分区都对应一个Task
2 . 第二个想法,用一个Task计算所有RDD 中对应的分区
3 . 这两个想法都有问题,分阶段,采用数据流动的模型来进行设计
阶段怎么划分
阶段 + Task 就是执行RDD 的执行者
总结
数据是如何流动的
- 数据计算发生在需要数据的地方,FinalRDD
- 第一个获取数据的 RDD 是 firstRDD
小案例
val firstRdd = sc.parallelize(Seq("spark flink", "docker k8s", "spark docker"))
val splitRdd = firstRdd.flatMap(_.split(" "))
val reduceRdd = splitRdd.map((_, 1)).reduceByKey(_ + _)
val mapRdd = reduceRdd.map(item => s"${item._1},${item._2}")
mapRdd.foreach(println(_))
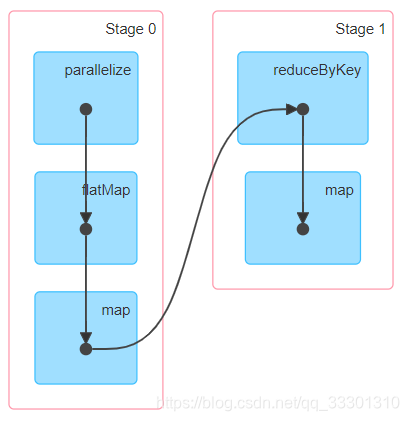
运行过程

















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









