




 本文分享了数据库查询优化的三大要点:基本规范、数据库连接注意事项与性能提升策略。涵盖SQL语句编写技巧,如避免SELECT *,使用绑定变量,合理利用索引,以及数据库连接的最佳实践,包括使用连接池,适时申请和关闭连接,避免循环中建立连接。同时,介绍了如何通过减少函数运算、优化排序操作、合理使用事务和避免大表模糊查询来提升数据库性能。
本文分享了数据库查询优化的三大要点:基本规范、数据库连接注意事项与性能提升策略。涵盖SQL语句编写技巧,如避免SELECT *,使用绑定变量,合理利用索引,以及数据库连接的最佳实践,包括使用连接池,适时申请和关闭连接,避免循环中建立连接。同时,介绍了如何通过减少函数运算、优化排序操作、合理使用事务和避免大表模糊查询来提升数据库性能。
前几天听了公司一位DB前辈的讲解,很受用。此文参照前辈(baoyongfei)的讲解。讲的很基础,适合大部分人参考。
此文讲解的都是基础的,也是很多开发最容易忽略的部分。理解错误之处,望指出。
分为三部分内容:基本规范、数据库连接注意点、性能提升。
一、基本规范:
- 对于的查询语句,输出字段(不算子查询):输出字段越多,对CPU的消耗就会增多;输出字段越多,网络传输的代价更大;输出字段越多,程序处理结果集的代价更大。
所以尽量避免使用 SELECT * FROM ... - 使用绑定变量:一是安全方面的考虑,防SQL注入基本要求;二是可以在库缓存中共享游标,避免硬解析以及与之相关的额外开销;
最好使用 WHERE name=:v_name ... - SQL的解析过程如图所示:
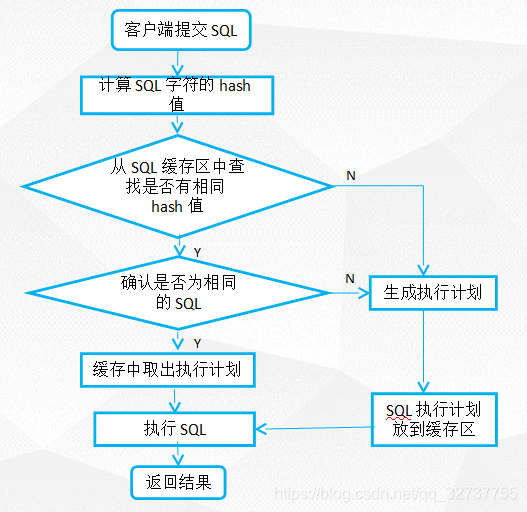
- 代码的可读性:对于较长、较复杂的sql语句,或者字段名、表名字不明了的语句,或子查询、关联条件、过滤条件等尽量加上注释。表别名与原表关联性,最好别使用a,b,c之类的字符。
SELECT code,changedate,--变动日期 f057n_stk035--总值 FROM ( SELECT comcode,changedate f057n_stk035 FROM stk035 WHERE isvalid=1 ) s035 --某某表 INNER JOIN ( SELECT code,f014v_pub205 FROM pub205 WHERE isvalid=1 ) p205 --某总表 ON s035.comcode=p205.f014v_pub205 --XX代码 - count(*)与count(字段):count(字段)为空的记录不会被统计进去;count(*)一般更容易用到索引。
最好使用count(*) 另:count(1) count(2) count(3) ... 和count(*)没区别,查询速度也一样。 -
对查询的记录数没有把握的情况下,建议加limit字段。通常数据表要加”isvalid=1”字段。
select count(*) from stk011 where isvalid=1; select code,stk012 from stk035 where isvalid=1 limit 100;
二、数据库连接注意点:
- 使用连接池。
不使用连接池流程:TCP三层握手协议 -> 登录认证 -> 执行SQL返回结果 -> TCP连接关闭 导致的问题: 1.网络IO较多 2.数据库负载相对较高,创建及释放连接会消耗一定CPU 3.响应时间较长及QPS较低 4.应用频繁的创建连接和关闭连接,导致临时对象较多,GC频繁 5.在关闭连接后,会出现大量TIME_WAIT 的TCP状态 -
要在“最晚的时刻”申请连接。
用到数据库的时候再去连接,而不是一开始就连接。 不当的写法: con.conndb();//连接数据库 com.proc01();//处理业务逻辑1 com.proc02();//处理业务逻辑2 con.executeQuery(sql);//执行SQL 推荐的写法: com.proc01();//处理业务逻辑1 com.proc02();//处理业务逻辑2 con.conndb();//连接数据库 con.executeQuery(sql);//执行SQL -
在“最早的时刻”关闭连接
sql执行完,尽快的关闭数据库连接。 不当的写法: con.executeQuery(sql);//执行SQL com.proc01();//处理业务逻辑1 com.proc02();//处理业务逻辑2 con.closedb();//关闭数据库 推荐的写法: con.executeQuery(sql);//执行SQL con.closedb();//关闭数据库 com.proc01();//处理业务逻辑1 com.proc02();//处理业务逻辑2 -
禁止循环中建立连接
通过第一条,我们可以知道建立连接池的必要性。将建立连接放置到循环中,会耗费很多资源 错误的写法: for( int i = 0 ; i < 100000 ; i++) { v_sql="select * from mac505 where vseq=?"; con.connect(); ...执行sql... con.close(); } 正确的写法: con.connect(); for( int i = 0 ; i < 100000 ; i++) { v_sql="select * from mac505 where vseq=?"; ...执行sql... } con.close();
三、性能提升:
- 尽量不要使用函数运算、加减乘除、 “1=1”
使用函数、加减乘数等:访问量特别的大,数据内容特别的多,很容易造成速度变慢,甚至数据库的崩溃。 1=1 :数据量大的时候查询速度会非常慢,可能会造成很大的性能损失。且数据库系统无法使用索引等查询优化策略,将会被迫全表扫描。 -
慎用复杂视图嵌套
数据量越大,嵌套越复杂耗费资源越多,性能越差。 -
排序操作要适量
原因: 1.排序时会占用大量内存资源; 2.当数据量超过分配给session的内存时会采用临时表空间,瞬间写磁盘压力会很大; 2.排序占用的资源和数据量、输出字段数有关。 解决之道: 1.减少甚至不用排序; 2.减少输出字段,特别是大文本字段; 3.选择合适的排序方式(使用算法)。 基本排序: Order by Group by distinct 集合运算: union except/minus intersect 窗口分析函数: First_value/last_value Row_number() over() rank/dense_rank/percent_rank -
数据库不擅长复杂数据运算
不要在数据库中做复杂运算,比如使用循环处理相同的数据,使用python耗费了10S 使用数据库运算耗费了154S -
索引需要合理使用(这个涉及到的就比较多了,原来写过一篇博文 链接:https://blog.youkuaiyun.com/qq_32737755/article/details/88600871)
-
表关联时用”or”时效率偏低
原SQL: SELECT code,s128.* FROM public205 p205 inner join stket128 s128 ON p205.f4v_pub205=s128.orgid_stk128 AND p205.isvalid=1 and s128.isvalid=1 AND ( p205.rtime>’2019-06-01 16:00:00’ OR s128.rtime>’2019-06-01 16:00:00’) 优化之后的SQL: SELECT code,s128.* FROM public205 p205 inner join stket128 s128 ON p205.f4v_pub205=s128.orgid_stk128 AND p205.isvalid=1 and s128.isvalid=1 AND p205.rtime>’2019-06-01 16:00:00’ UNION SELECT code,s128.* FROM public205 p205 inner join stket128 s128 ON p205.f4v_pub205=s128.orgid_stk128 AND p205.isvalid=1 and s128.isvalid=1 AND s128.rtime> ’2019-06-01 16:00:00’ -
避免单条提交
以事务举例,单条提交的影响: 1.事务日志包含维护信息,产生更多的事务日志 2.单条commit的IOPS肯定大于多条commit,每commit一次,至少产生一次iops 3.如果表上有索引,会增加维护索引的成本 4.对应PostgreSQL数据库,事务号消耗过快 原SQl: Insert into tab(id,f001,f002)values(1,’a’,’b’); Commit; Insert into tab(id,f001,f002)values(2,’a’,’b’); Commit; Insert into tab(id,f001,f002)values(3,’a’,’b’); Commit; 优化后: begin Insert into tab(id,f001,f002)values(1,’a’,’b’); Insert into tab(id,f001,f002)values(2,’a’,’b’); Insert into tab(id,f001,f002)values(3,’a’,’b’); …… Commit; 另:数据量过多(不包含大文本、文件流)的时候,批量插入(一次插入1000条是没问题的)要比单挑插入速度快的多的多! 但是若数据中包含大文本、大文件流(一个文件几M)类的,最好一次插入10-100条。 具体情况视单个数据大小而定。 -
避免单个事务过大
1.事务过大,造成维护事务元数据占用资源过多,如回滚表空间过大; 2.事务进行中影响期间的并发能力; 3.增加crash recovery的恢复时间; 4.对应PostgreSQL数据库,表不能及时回收dead tuple,导致表空间膨胀,从而引起性能问题; 如果需要提交的数据量有很多,建议分批处理。 -
及时提交事务
1.事务未提交可能导致其他session没法提交事务,造成锁等待 2.不及时提交或不提交,造成回滚段没法及时回收,从而造成性能问题 3.对应PostgreSQL数据库,可能会导致事务回绕; 例: Begin UPDATE tb_hk001 SET isvalid=1,mtime=now() WHERE id=128; /*接下来进行大量php或java的处理逻辑*/ Commit; 如果在进行逻辑处理的时候,因为网络或程序等各类原因没有“commit”,以pg来说,就很有可能导致表空间无法回收导致查询性能下降。 -
大表少用模糊查询
1.大表模糊查询交给搜索数据库,关系型数据库支持,但性能不高; 2.关系型数据库模糊查询会消耗大量资源,影响其他session的正常查询,性能低下。 like模糊查询的使用,避免使用%% 例如select * from table where name like '%de%' and isvalid=1; 代替语句:select * from table where name >= 'de' and name < 'df' and isvalid=1; -
高并发的查询交给redis
1.关系型数据库响应速度远不及Redis; 2.相同条件下关系型数据库的qps较Redis要低很多; 3.Key-value键值较小时给Redis相对合适,较大时影响qps。

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









