1、编写UDF函数,来将原来创建的buck_ip_test表中的英文国籍转换成中文
iptest.txt文件内容:
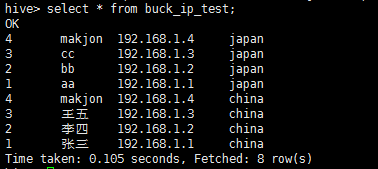
| 1 张三 192.168.1.1 china
2 李四 192.168.1.2 china
3 王五 192.168.1.3 china
4 makjon 192.168.1.4 china
1 aa 192.168.1.1 japan
2 bb 192.168.1.2 japan
3 cc 192.168.1.3 japan
4 makjon 192.168.1.4 japan
|
表数据截图:
UdfTest.java代码如下:
| import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
public class UdfTest extends UDF{
private static HashMap<String,String> countryMap = new HashMap();
static {
countryMap.put("china", "中国");
countryMap.put("japan", "日本");
}
//此段代码进行国家的转换
public String evaluate(String str){
String country = countryMap.get(str);
if(country ==null){
return "其他";
}else{
return country;
}
}
//在函数中可以定义多个evaluate方法,进行重载
//此段代码进行国家和IP的拼接,测试重载用
public String evaluate(String country,String ip){
return country+"_"+ip;
}
/*
*
*此段代码用于测试上面编写的方法是否正确
public static void main(String[] args) {
UdfTest ut = new UdfTest();
// TODO Auto-generated method stub
String aa = ut.evaluate("AAAAAA");
System.out.println(aa);
}
*/
}
|
在eclipse测试无问题后,导出成utftest.jar并上传到服务器的/opt目录
| 进入hive,执行:
add jar /opt/udftest.jar;
将jar包导入到hive中
再执行create temporary function convert as 'UdfTest';
创建convert方法
执行结果如下图:
|
然后在Hive中进行查询:
| select country,convert(country,ip),convert(country) from buck_ip_test;
|
执行结果如下图:
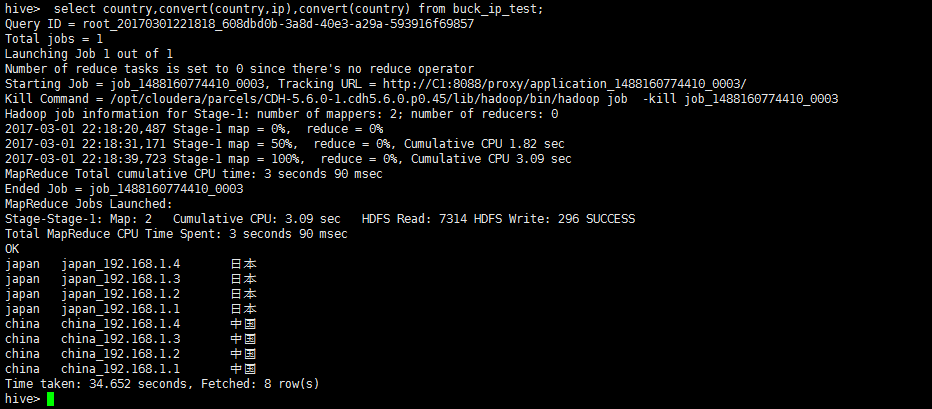
这样一个简单的udf就开发完成啦
2、Hive中使用udf对JSON进行处理
数据文件movie.txt内容如下:
| {"movie":"2797","rate":"4","timeStamp":"978302039","uid":"1"}
{"movie":"2321","rate":"3","timeStamp":"978302205","uid":"1"}
{"movie":"720","rate":"3","timeStamp":"978300760","uid":"1"}
{"movie":"1270","rate":"5","timeStamp":"978300055","uid":"1"}
{"movie":"527","rate":"5","timeStamp":"978824195","uid":"1"}
{"movie":"2340","rate":"3","timeStamp":"978300103","uid":"1"}
{"movie":"48","rate":"5","timeStamp":"978824351","uid":"1"}
{"movie":"1097","rate":"4","timeStamp":"978301953","uid":"1"}
{"movie":"1721","rate":"4","timeStamp":"978300055","uid":"1"}
{"movie":"1545","rate":"4","timeStamp":"978824139","uid":"1"}
|
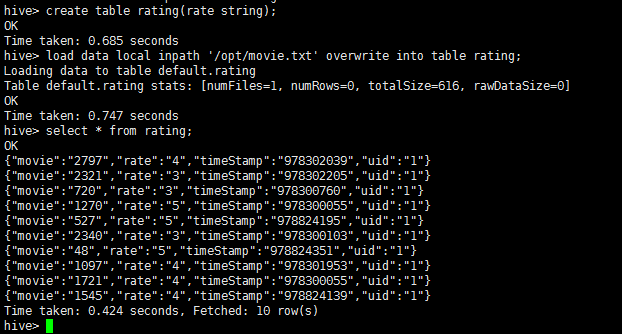
将数据导入到hive中的rating表中:
| create table rating(rate string);
load data local inpath '/opt/movie.txt' overwrite into table rating;
select * from rating;
|
结果如下图:
在本例中我们使用ObjectMapper来处理json的数据,
首先创建MovierateBean.java,代码如下:
| import java.sql.Timestamp;
public class MovierateBean {
private String movie;
private String rate;
private Timestamp timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public Timestamp getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(Timestamp timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return movie+"\t"+rate+"\t"+timeStamp+"\t"+uid;
}
}
|
然后创建MovieJsonTest.java,代码如下:
| import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
public class MovieJsonTest extends UDF {
public String evaluate(String jsonline){
ObjectMapper om = new ObjectMapper();
try{
MovierateBean bean = om.readValue(jsonline,MovierateBean.class);
return bean.toString();
}catch(Exception e){
return(jsonline);
}
}
/*
public static void main(String[] args){
MovieJsonTest mt = new MovieJsonTest();
String jsonline="{\"movie\":\"527\",\"rate\":\"5\",\"timeStamp\":\"978824195\",\"uid\":\"1\"}";
System.out.println(mt.evaluate(jsonline));
}
*/
}
|
将上述文件打包成movie.jar,并上传到服务器的/opt目录下,并执行如下代码:
| add jar /opt/movie.jar;
create temporary function movie_convert as 'MovieJsonTest';
select movie_convert(rate) from rating;
|
执行结果如下:
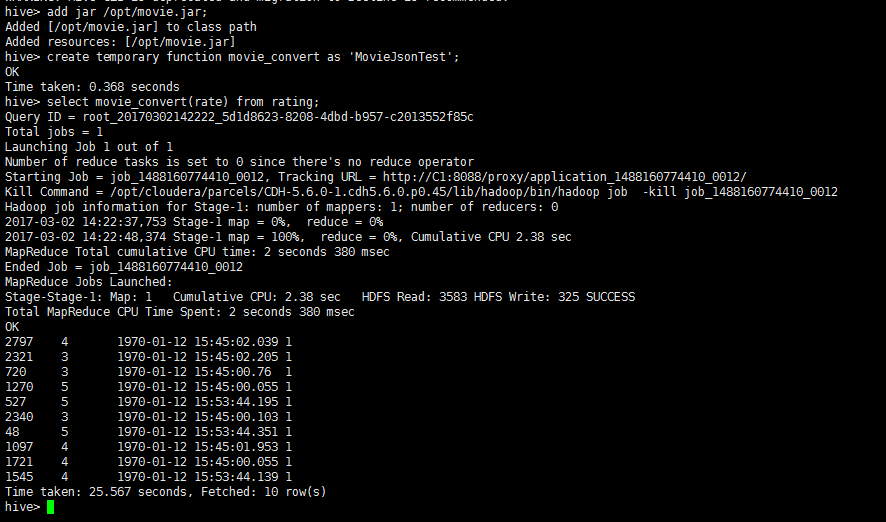
可以看到原来的json格式以及被解析成对应的字段了
3、Hive Transform简单介绍
Hive的UDF、UDAF需要通过java语言编写。Hive提供了另一种方式,达到自定义UDF和UDAF的目的,但使用方法更简单。这就是TRANSFORM。TRANSFORM语言支持通过多种语言,实现类似于UDF的功能。
Hive还提供了MAP和REDUCE这两个关键字。但MAP和REDUCE一般可理解为只是TRANSFORM的别名。并不代表一般是在map阶段或者是在reduce阶段调用。详见官网说明。
我们可以使用如下的python脚本代替上面的UDF函数:
服务器端/opt/movie_trans.py脚本内容如下:
| import sys
import datetime
import json
for line in sys.stdin:
#line='{"movie":"2797","rate":"4","timeStamp":"978302039","uid":"1"}'
line = line.strip()
hjson = json.loads(line)
movie = hjson['movie']
rate = hjson['rate']
timeStamp = hjson['timeStamp']
uid = hjson['uid']
timeStamp = datetime.datetime.fromtimestamp(float(timeStamp))
print '\t'.join([movie, rate, str(timeStamp),uid])
|
在hive中执行如下脚本:
| ADD FILE /opt/movie_trans.py;
SELECT
TRANSFORM (rate)
USING 'python movie_trans.py'
AS (movie,rate, timeStamp, uid)
FROM rating;
|
执行结果如下图:
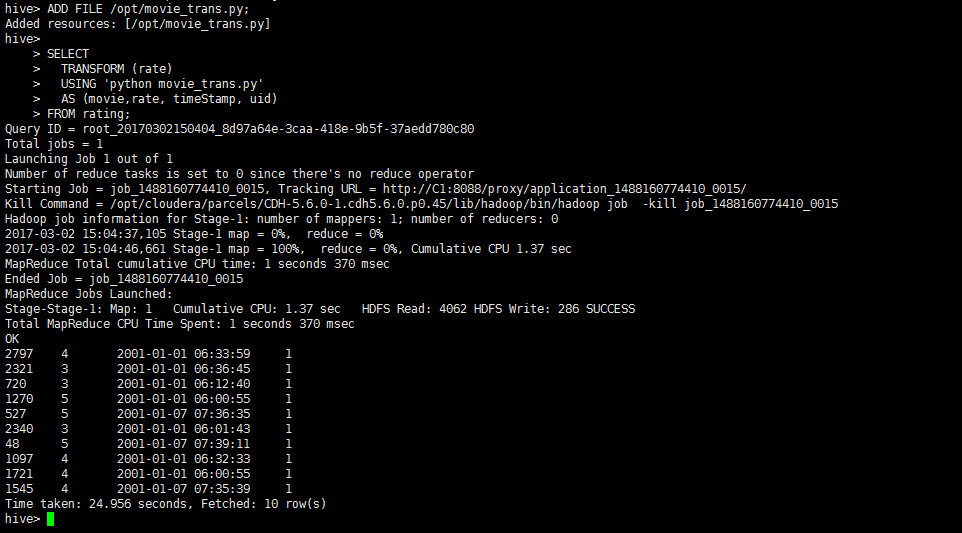
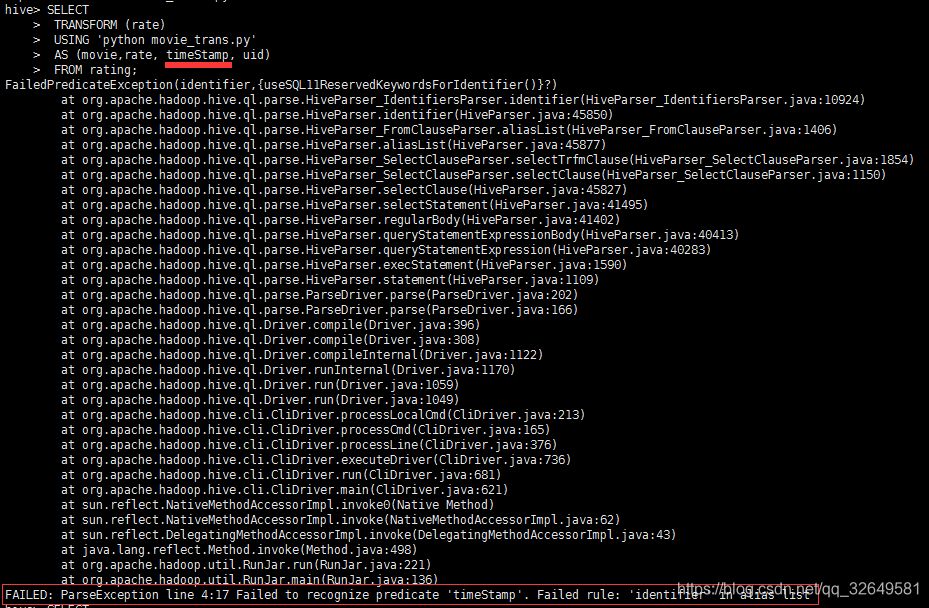
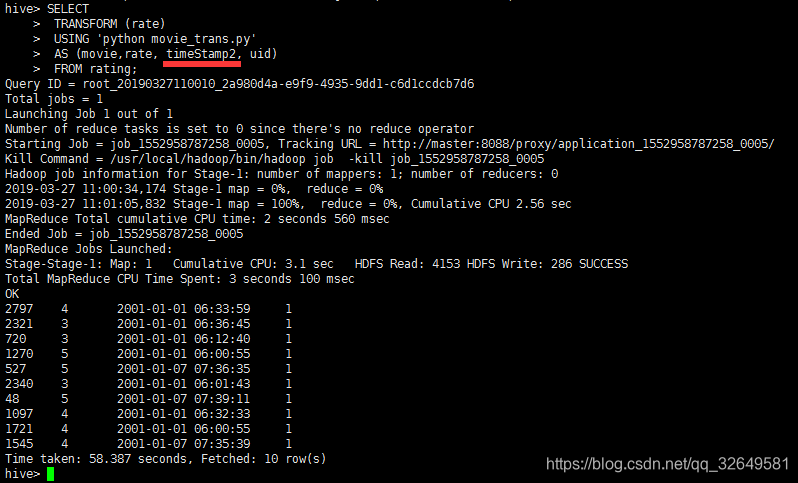
可以看到我们使用transform实现了上述UDF实现的功能
原文地址:https://www.cnblogs.com/cangos/p/6486651.html








 本文介绍了如何在Hive中使用UDF将英文国籍转换为中文,并演示了使用UDF处理JSON数据的方法,同时对比了使用TRANSFORM实现相同功能的过程。
本文介绍了如何在Hive中使用UDF将英文国籍转换为中文,并演示了使用UDF处理JSON数据的方法,同时对比了使用TRANSFORM实现相同功能的过程。

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









