




 本文探讨了机器阅读理解领域中的两种关键注意力机制:BiDAF和动态共注意力网络(DCN),并提出了一种名为DoubleCrossAttention(DCA)的新模型,该模型在SQuAD数据集上表现出优于BiDAF和DCN的性能。
本文探讨了机器阅读理解领域中的两种关键注意力机制:BiDAF和动态共注意力网络(DCN),并提出了一种名为DoubleCrossAttention(DCA)的新模型,该模型在SQuAD数据集上表现出优于BiDAF和DCN的性能。
《Pay More Attention: Neural Architectures for Question-Answering》阅读笔记
摘要
机器阅读理解是自然语言理解领域的经典任务。这个任务一般是获得一篇上下文文档,目的是回答与这篇文档相关的问题。这样一个问题的目的是关注文档(context)与问题(question)之间复杂的联系。该领域最新成果表明,带有注意力流的注意力机制在解决这个任务的时候可以起到很好的效果,其中包含问题到文档(question-to-context)和文档到问题(context-to-question)两个方向。这篇文章我们介绍关于注意力机制的两个最新成果:Bi-Directional Attention Flow( BiDAF )和Dynamic Co-Attention Networks(DCN),然后提出了一个新的混合了两种注意力机制的新模型,这个模型取得了更好的效果。我们将我们提出的这种模型称为Double Cross Attention(DCA)。我们的实验结果在the Stanford Question Answering Dataset(SQuAD )数据集上取得了相较于BiDAF和DCN更好的结果。
Pay More Attention: Neural Architectures for Question-Answering
Machine comprehension is a representative task of natural language understanding. Typically, we are given context paragraph and the objective is to answer a question that depends on the context. Such a problem requires to model the complex interactions between the context paragraph and the question. Lately, attention mechanisms have been found to be quite successful at these tasks and in particular, attention mechanisms with attention flow from both context-to-question and question-to-context have been proven to be quite useful. In this paper, we study two state-of-the-art attention mechanisms called Bi-Directional Attention Flow (BiDAF) and Dynamic Co-Attention Network (DCN) and propose a hybrid scheme combining these two architectures that gives better overall performance. Moreover, we also suggest a new simpler attention mechanism that we call Double Cross Attention (DCA) that provides better results compared to both BiDAF and Co-Attention mechanisms while providing similar performance as the hybrid scheme. The objective of our paper is to focus particularly on the attention layer and to suggest improvements on that. Our experimental evaluations show that both our proposed models achieve superior results on the Stanford Question Answering Dataset (SQuAD) compared to BiDAF and DCN attention mechanisms.
keywords: Machine Reading Comprehension; Neural Architectures; Double Cross Attention;
论文原文链接:https://arxiv.org/pdf/1803.09230v1.pdf.
论文源码链接:https://github.com/crack00ns/SQuAD-challenge
1 引言
机器阅读理解任务简介
使机器能够理解自然语言是实现人工智能系统的关键挑战之一。问机器问题并得到有意义的答案对我们来说是有价值的,因为它极大地自动化了知识获取工作。苹果公司(Apple)的Siri和亚马逊公司(Amazon)的Echo就是两款能够实现机器阅读理解的大众市场产品,它们的出现已经导致了消费者与机器互动方式的范式转变。
SQuAD数据集简介
斯坦福大学的Rajpurkar等人于2016年在自然语言处理的顶级会议EMNLP上发布了SQuAD语料库。SQuAD通过众包的方式,从wikipedia上的536篇文章提取超过10w个问题-答案对,且其中的答案是原文的一个片段而不是单一的实体对象。

图 1 SQuAD语料库中的一个原文-问题-答案样本
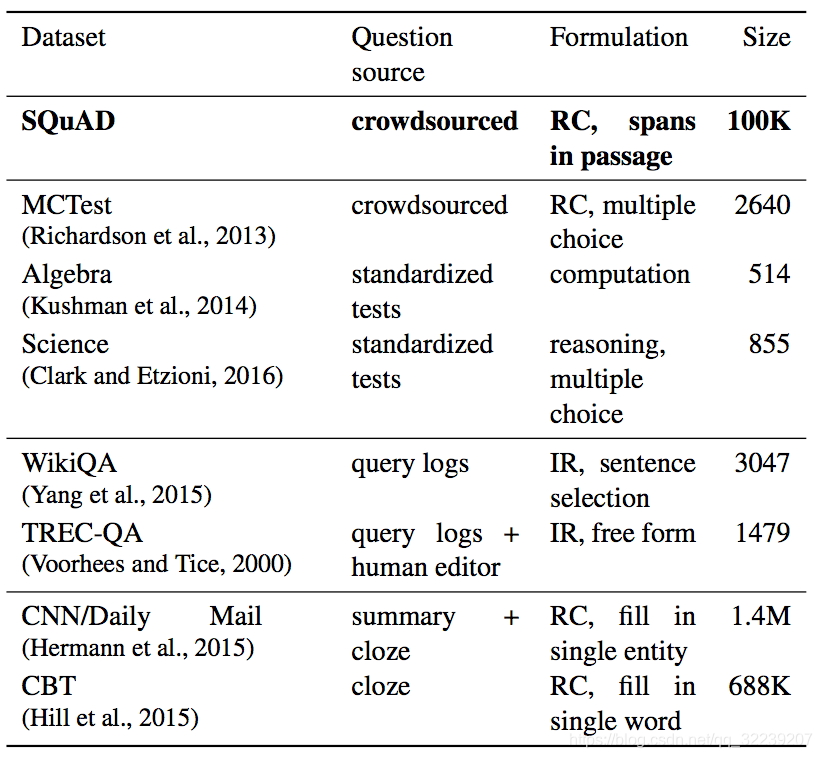
图2 机器阅读理解领域知名语料库对比
2 模型
在本文中,使用的机器阅读理解模型是经典的端到端的网络模型(end-to-end networks)。本文介绍的模型 BiDAF 和 DCN ,以及本文提出的新模型 DCA 区别主要体现在注意力层的不同处理上,本文的模型是综合了 BiDAF 和 DCN 的特点提出的新的注意力机制。
单词级和字符级嵌入层(Word and Character Embedding Layer)
嵌入层将单词映射为向量。词嵌入层(word embedding layer)将文档和问题中的每个词映射在一个定长的预训练的GloVe(Global Vector)词嵌入。首先,我们将文档和问题中的每个单词编码在GloVe嵌入的基准系统上。然后,我们将获得的词嵌入与在字符级嵌入上获得的词嵌入连接(concatenate)在一起,因为字符级嵌入可以帮助解决未登录词的嵌入问题。然后,我们将词级和字符级编码作为输入,加入到文档和问题的编码层
文档和问题编码层(Context and Question Encoding Layer)
编码层给词嵌入上下文的信息。当我们获得了文档和问题的词嵌入(word embedding)之后,我们使用双向GRU(bidirectional GRU)将文档和问题的词嵌入转换为编码(encoding).单一的LSTM/GRU编码序列时只有左到右(left-to-right)一个方向,而双向的LSTM/GRU还会将序列从右到左(right-to-left)编码,然后将编码进行连接。序列的双向表征(representation)会比单向的表征效果好很多。
注意力层(attention layer)
注意力层是为了表示文档和问题之间的复杂的相互作用。,然后我们借此介绍几种应用在我们系统中的注意力机制。
Bidirectional attention flow
Bidirectional attention flow layer(BiDAF)。BiDAF在这一层,计算了问题到文档(question-to-context)和文档到问题(context-to-question)l两个方向上的注意力并将他们有机结合。他的基本思想是,得到一个文档和问题之间的关系的相似度矩阵,并且用这个矩阵来获得文档到问题和问题到文档之间的注意力向量(attention vector)。最后,把注意力向量和文档的编码用特殊方法连接起来,作为BiDAF的输出。在BiDAF的原文中,使用的是一个经典的双向RNN来对这些连接的向量进行重新编码,但是这个双向RNN对我们的系统没有帮助。,所以我们最后没有使用。
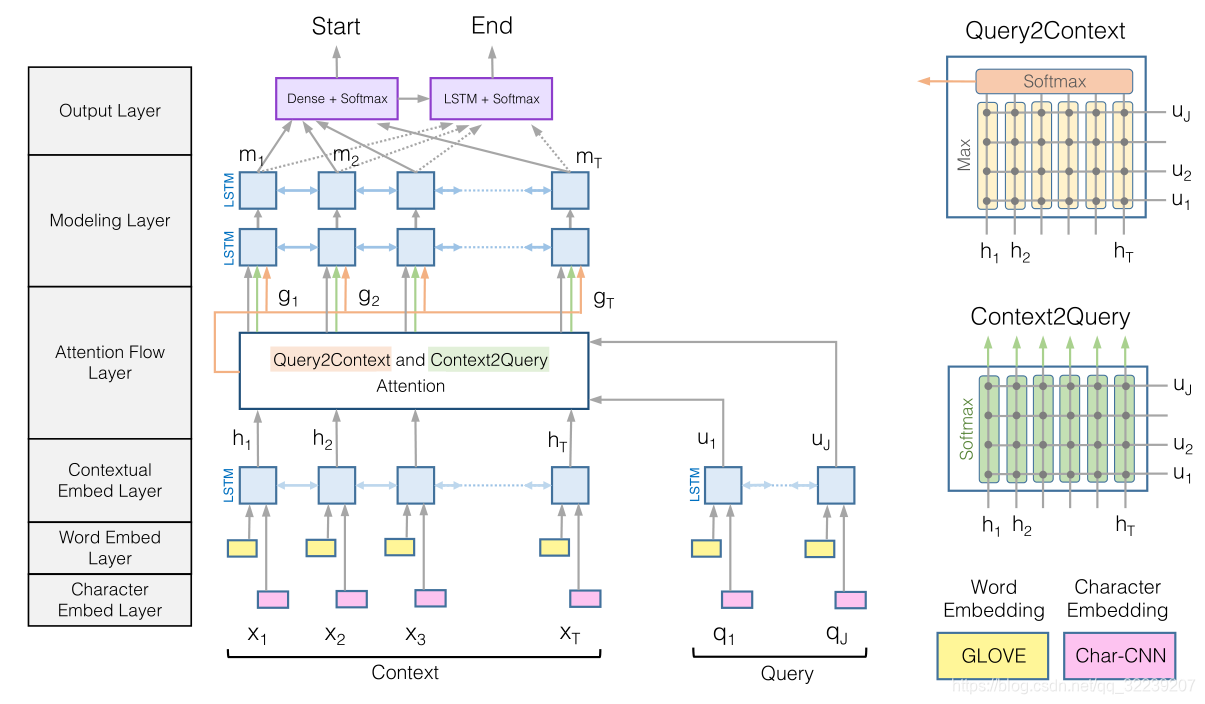
图3 BiDAF模型图解
Dynamic Co-Attention
Dynamic Co-Attention Networks layer(DCN)。DCN和BiDAF一样使用的是双向的注意力机制,他们不同的地方是,DCN在原始的计算的注意力上使用了二级注意力计算(second-level attention computation)。DCN这个模型是典型的端到端的网络模型。作者指出上下文的专注于文档的能力极大依赖于问题。这个思想直觉上是因为人类回答问题的能力和问题是什么样的有很大的关系,如果先知道了问题,人会回答地更好,这样人能更好地注意到文档中应该被注意的相关片段。这个模型的具体细节需要看原文。原文中有提到哨兵向量(sentinel vector)的概念,这个概念对我们的系统没有什么用,所以我们没有用上。
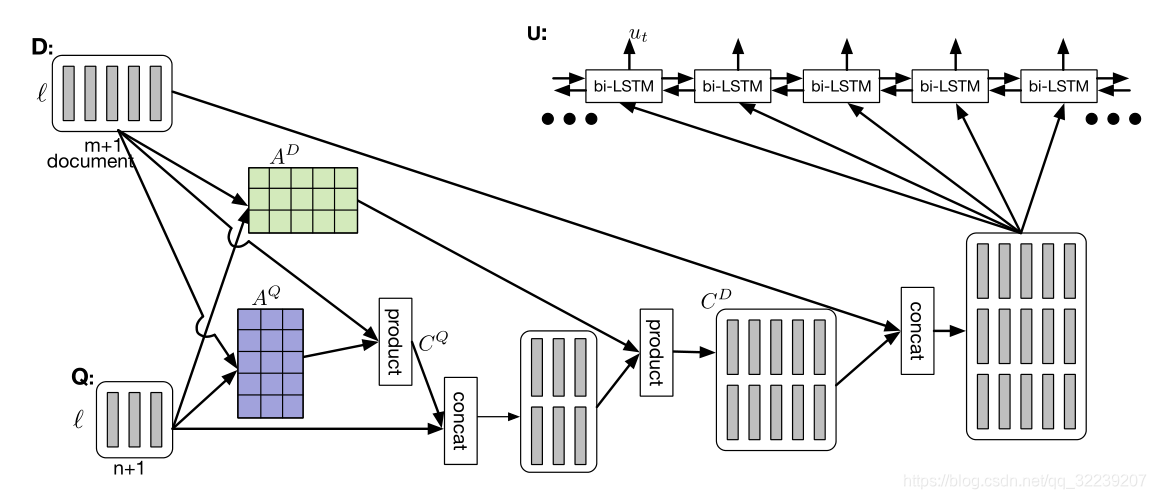
图4 DCN模型图解
Hybrid BiDAF-Co-Attention(New Model)
我们的新模型很大程度上是建立在 BiDAF 和 DCN 这两个模型之上的。因为BIDAF和DCN这两个模型的注意力层(attention layer)的输出都是有他们的含义的。我们的想法是把这两个注意力层的attention向量都连接在原始的上下文向量(context state)上。我们直觉地感觉到这样应该可以训练好神经网络,并且发挥他们俩的优势。试验结果表明这样做效果会更好,并且也满足了我们的需要。想了解详细的细节可以参考我们的代码。
Double Cross Attention(New Model)
在这一部分,我们提出了另一个简单的想法,并将他命名为Double Cross Attention(DCA),这个模型的效果比BiDAF和DCN两个模型都要好,和上一部分提到的混合模型表现相似。首先我们要注意每个问题和文档,然后我们采用一个和DCN相似的方式注意(attend)彼此。直觉来源是,反复阅读/关注问题和文档可以帮助我们更轻松地搜索答案。DCA模型的图形化表示如图3所示。
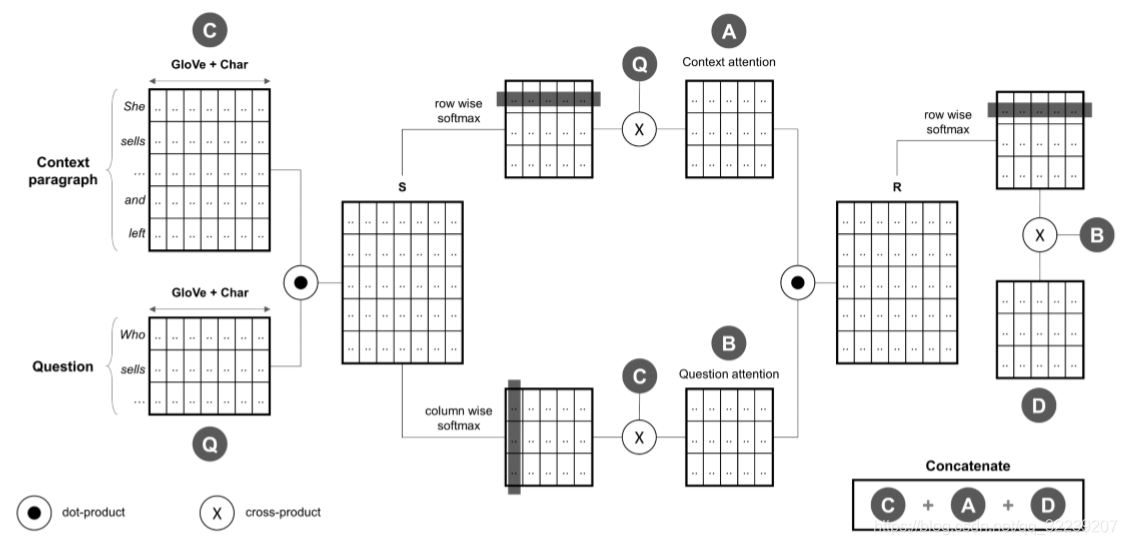
图5 Double Cross Attention模型
问题与文档隐藏状态的表示
context‘ hidden states表示为: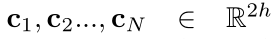
question hidden states表示为: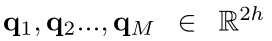
交叉注意力矩阵计算方法
cross-attention matrix表示为: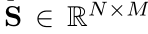
矩阵中,*Si,j*是每一对上下文和问题的隐藏状态对(ci,qj)之间的相似度分数,我们计算Si,j这个分数的方式是
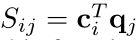
,这是一种计算注意力的无参数方法,但是也可以用可训练的权重参数(weight parameters)构造这个函数。
注意力向量计算方法
首先,我们可以得到Context-to-Question(C2Q)注意力向量ai:
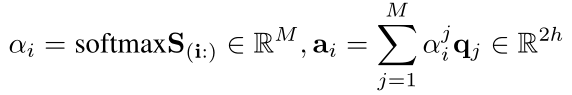
然后得到Question-to-Context(Q2C)注意力向量bj:
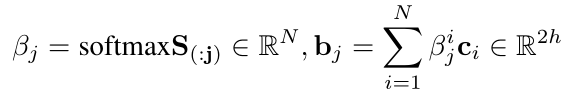
二级交叉注意力向量
然后我们计算一个二级的交叉注意力矩阵: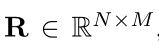 ,矩阵中包含的Ri,j是每一个问题和文档的注意力状态对(ai,bj)的相似度分数。我们再次使用一个简单的点积注意力(cross product attention):
,矩阵中包含的Ri,j是每一个问题和文档的注意力状态对(ai,bj)的相似度分数。我们再次使用一个简单的点积注意力(cross product attention):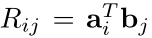 ,随后得到Context Attention-to-Question Attention(CA2QA)的交叉注意力向量di,计算方法如下:
,随后得到Context Attention-to-Question Attention(CA2QA)的交叉注意力向量di,计算方法如下:
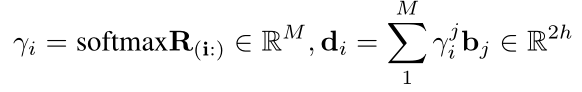
最后
我们将ci,ai和di当作一个新的状态[ci:ai:di],并且让它通过一个双向的biLSTM层来获得双向问题被注意了的被编码了的上下文状态(double query attended encoded context states),方法如下:
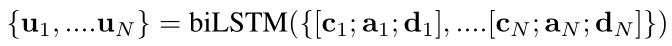
,最后,将所有的注意力层输出连接(concatenate)起来,提供给一个SoftMax层,用来独立的计算开始和结束token的概率分布,就像在基准系统里做的那样。
3 实验
首先,我们展示了SQuAD数据集的问题、答案和上下文长度的分布,随后,我们统计了不同的问题类型的数量。
1.我们发现大部分答案长度要小于5
2.我们注意到文档的平均长度大概在120(由于位置不够所以没展示)。
3.一个问题的答案倾向于是一篇文档的开头部分的片段。
4.我们可以看到问题类型是"what"的问题是最多的,几乎是其他所有问题类型的的数目的总合。
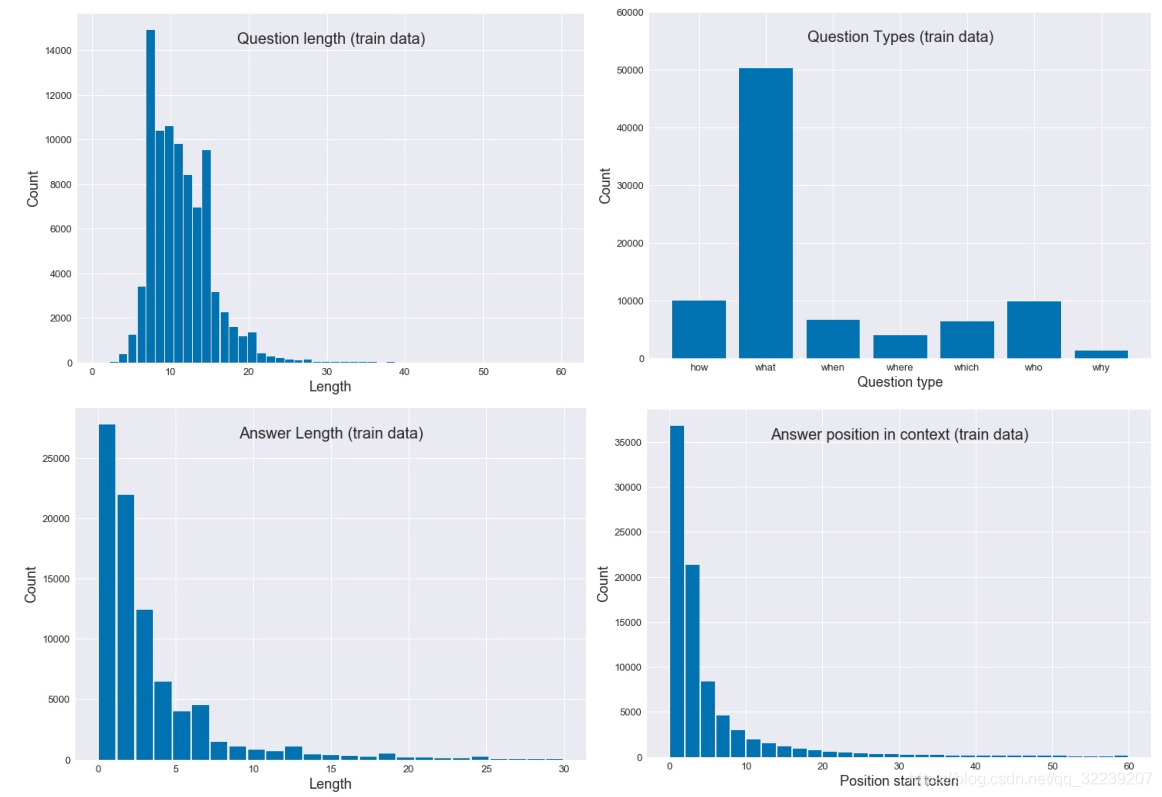 图6 SQuAD数据集问题、答案、文档的分布
图6 SQuAD数据集问题、答案、文档的分布
结果
在这一节我们报告了我们的实验结果。为了保证我们实验结果的通用性,我们使用了Dropout的技术来调整网络模型。
我们的模型包含的默认超参数:
词嵌入的长度(embedding size)为100,
批量大小(batch size)为100,
隐藏状态(hidden size)长度为200,
学习速率(learning rate)为0.001,
dropout率为0.15,
字符级编码长度(character embedding size)是20,
核大小(kernel size)为5,
滤波器(filter)的数量是5。
随后我们展示了我们模型在测试集上的F1和EM评估分数。

图7 实验结果
字符级嵌入(character level embedding)在模型BIDAF上的效果见table 1。在F1值和EM值上有2%的提升。这是因为字符级嵌入可以提供未登录词一个独一无二的嵌入。
随后,我们在table 2上展示了基准系统、BIDAF、Co-Attention、混合模型(hybrid model)和DCA注意力模型分别在SQuAD数据集上的表现。
1.我们可以发现两个模型的EM/F1分数都没有怎么优化,但是我们更应该关注在这些模型的固定长度的超参数(a fixed set of hyperparameters)。
2.混合模型和DCA相较于BiDAF和Co-Attention有着轻微的优势。
3.Co-Attention模型加上字符级Embedding之后效果更差,所以我们保留了没加字符级embedding的Co-Attention的结果。
4.这里的BiDAF并没有像原论文一样使用了BILSTM层,因为BiLSTM这一层除了拖慢训练的速度之外没有任何的优势。
随后,我们在展示了图8展示了tensorboard可视化上的结果。
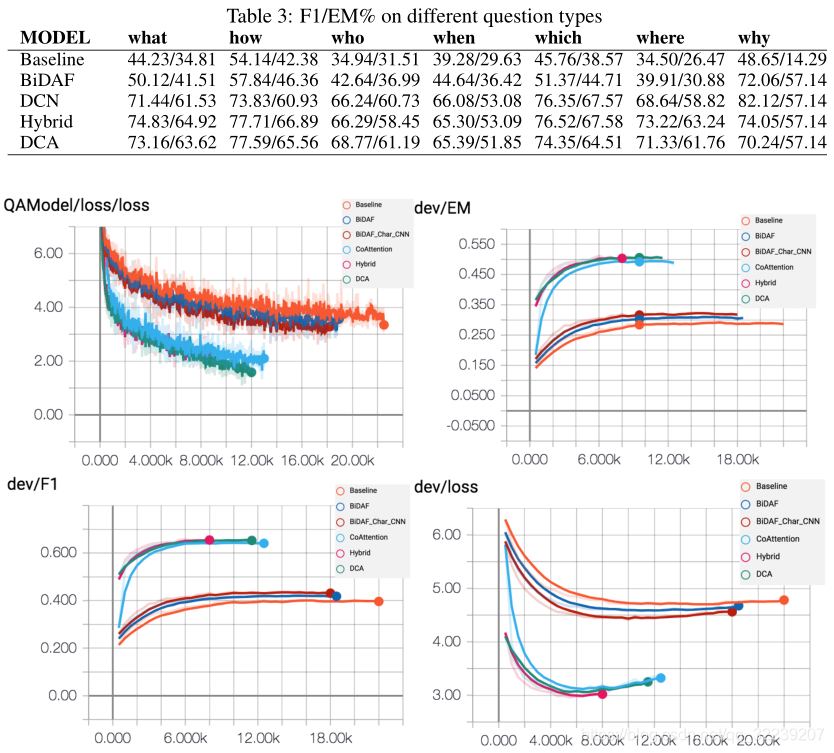 图8 tensorboard可视化结果
图8 tensorboard可视化结果
可视化结果表明,混合模型和DCA模型结果都比BiDAF和Co-Attention模型的结果要好,而且loss减少得更快,EM/F1分数增加得也更快。
超参数调整结果

图9 超参数调整对实验结果的影响
错误结果分析
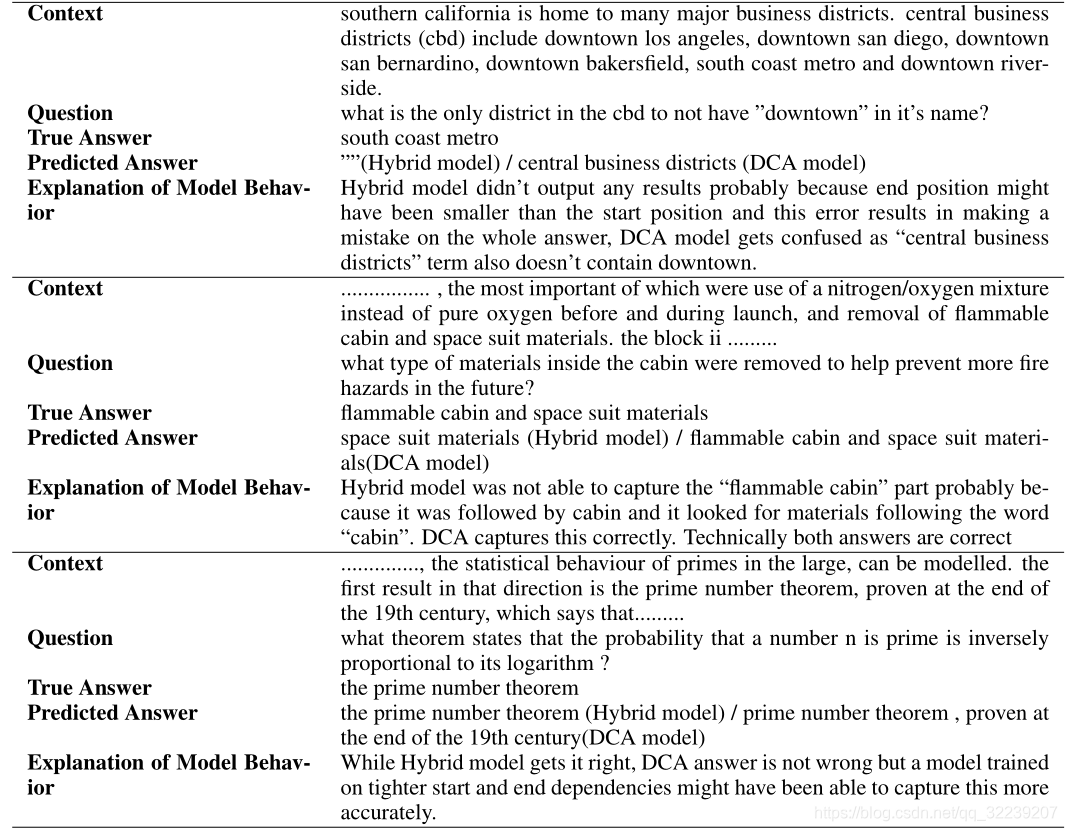
图10 数据集错误结果分析
4 总结
–>在这篇论文中,我们分析了两个有名的注意力机制,BiDAF和Co-Attention。
–>我们也介绍了两个模型的简单融合,叫做混合模型(Hybrid model),这个模型比上面两个效果都好。
–>除此之外,我们还提出了我们自己的模型Double Cross Attention(DCA),这个模型和混合模型的结果差不多。
–>这篇论文的目的是分析和比较上述两个有名的Attention的异同,而不是追求SQuAD的分数。
–>为了提升上面这些模型的EM/F1的分数,我们也用了一些增强的技术。
–>比如,我们将词级嵌入和字符级嵌入连接在一起来提高分数。更先进的做法是像文章中那样高效的把他们进行结合。
–>也还有其他的注意力机制需要被研究。
–>另一种可能有效的方法是在答案片段开始位置,适当地调整答案结束位置(答案指针层)。在原始的BiDAF论文中使用LSTM来解决这个问题。
–>指数加权平均(Exponential moving average of weights)和模型的集成是传统的方法来进一步微调并提升结果。
–> Hierarchical Maxout Network模型在Co-Attention论文中被提到可以作为我们简单的SoftMax层的替代品来进一步提升实验的结果。
–>如果不追求结果的话,适当地共享层与层之间的权重可能可以减少超参数的数量。
–>上面提到的所有建议,我们把它看作一种提升分数的方法(部分方法我们已经试过了来提升结果,但是没有包含在最终的结果里)。
–>作为cs224n的最后一课,任务虽然难,但是我们对实验的结果还是满意的。
–>我们确信,如果有更多的时间,我们可以从目前为止所实现的基线增强显著地改进我们的模型。总之,我们相信这个项目的经验,将对我们未来的专业工作具有极大的价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









