




 本文详细解析了MapReduce的工作原理及流程,包括其优势与局限性。通过具体案例,如词频统计,展示了数据处理的全过程,从文件分割、映射、洗牌到归约,最终得出结果。
本文详细解析了MapReduce的工作原理及流程,包括其优势与局限性。通过具体案例,如词频统计,展示了数据处理的全过程,从文件分割、映射、洗牌到归约,最终得出结果。
mapreduce优点:海量数据离线处理&易开法&容易运行
mapreduce缺点:无法实现流式计算
分布式计算小案例:统计海量数据文件中的词频

流程分析:
1.首先将输入的文件拆分成多个文件快(spliting)
2.每台机器统计每个文件快中的单词次数,根据空格等正则来拆分单词(mapping)
3.每个节点将会吧相同的单词发送到特定的某台机器上,这样每个机器就会知道特定的单词的数量(shuffing)
4.汇总单词数量(reducing)
5返回结果
mapReduce流程:
input <k1,v1> -> map -> <k2,v2> ->combine -> <k2,v2..> -> reduce -><k3,v3>
解释:
输入的文件hadoop会按照文件中字符的偏移量来作为k1,v1就表示该偏移量后面的内容
经过mapping过程后,每个节点会得到相应字符的统计数这时k2表示单词,v2表示个数
k3,v3与k2,v2相同
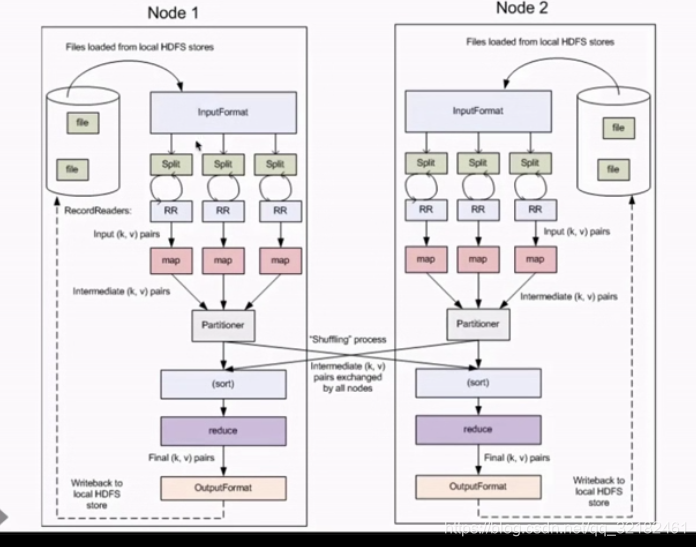
下图为流程图:
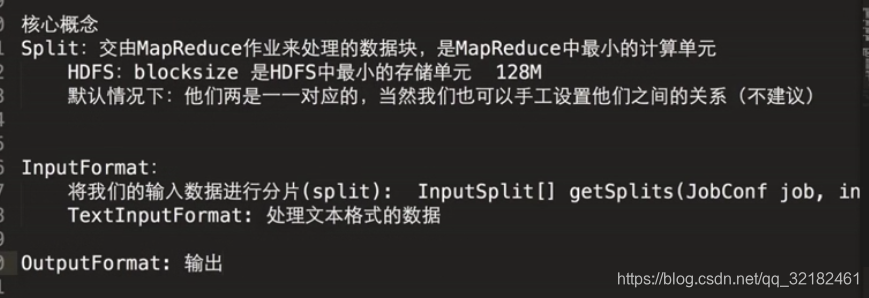
mr核心概念:
blocksize与split之间的关系:
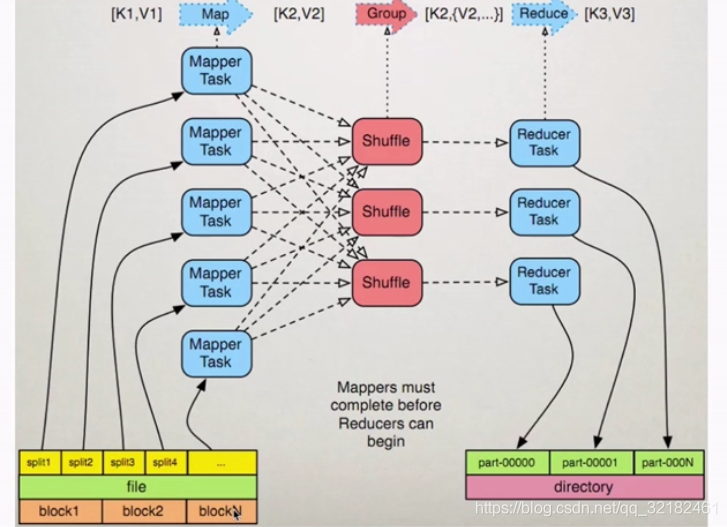
一个文件会被拆分成多个block,这是hdfs的最小存储单元
每个block会被拆分成多个split,这是mr的最小计算单元。此时的split就对应为上图的k1,v1
每个split会交给一个mapperTask来处理,也就是map过程
之后就是shuffle过程和reduce过程
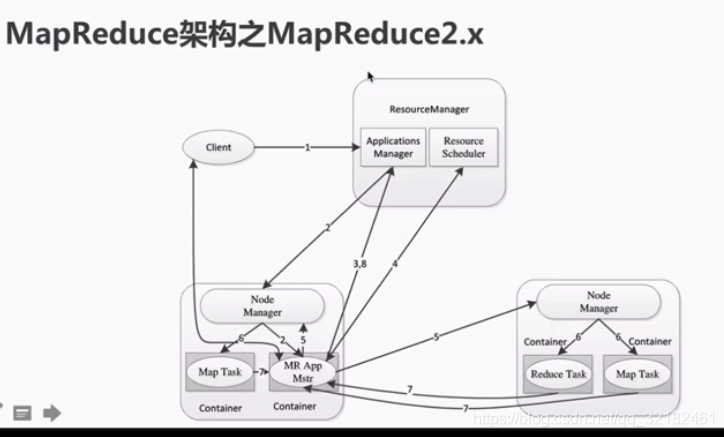
mapreduce2.x架构图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









