



 文章探讨了MySQL在数据量增大后的性能下降问题,提出了分库、分表、分区和分片等策略来提升数据库的读写性能。分库旨在降低单库数据量,分表包括垂直和水平划分,以减少单表数据量和IO压力。分区是将数据文件按规则切割,而分片则涉及多库多表的分布。此外,文章强调了监控数据库状态、优化SQL和设置合适的连接池大小的重要性,因为慢SQL可能导致连接池耗尽和其他问题。
文章探讨了MySQL在数据量增大后的性能下降问题,提出了分库、分表、分区和分片等策略来提升数据库的读写性能。分库旨在降低单库数据量,分表包括垂直和水平划分,以减少单表数据量和IO压力。分区是将数据文件按规则切割,而分片则涉及多库多表的分布。此外,文章强调了监控数据库状态、优化SQL和设置合适的连接池大小的重要性,因为慢SQL可能导致连接池耗尽和其他问题。
1.前言
MySQL单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而变弱。MySQL单表的数据量是500w-1000w之间性能比较好,超过1000w性能也会下降。
2.mysql分布式
-
分库
分库一般有两种目的:将库中不同表进行拆分,将库中某个表进行拆分,目标就是降低单库的数据量,从而提高io能力和并发能力。
将不同表拆分即将不同的大表移动到其他库中,缓解单库压力,通过多数据源即可进行切换查询,成本最低。
将相同表进行拆分,需要根据某种规则进行拆分,比如按照时间、按照某个主键,这种方式既进行了分表也进行了分库,属于分片的范畴。
-
分表
分表分为垂直划分和水平划分。
垂直划分即将不同的字段进行拆分。比如一个学生表中,含有年龄、班级、成绩等属性。我们可以将其拆分为学生、年龄表和学生、成绩表,防止某个属性过大,造成单表的数据量不大,但占用空间极大,造成io缓慢。
水平划分即可通过主键区间划分,或者主键取模或者位运算。这些方式均是将数据水平拆分,每个表的数据结构都是一样的,将数据打散到多个表中,降低单表的数据量,提高能力。
-
分区
mysql提供的一种能力。首先 mysql的文件分为三个,具体名字不做阐述,分别为存储表结构、存储数据文件、存储索引数据。分区时,可按照list、hash、区间等多个方式进行分区,将这存储数据的两个文件打散,根据以上的规则分为多个文件。实际仍处于同一个库同一个表中,只是文件切割开,不同的分区文件可以存储咋不同的磁盘上,不允许跨DB。
-
分片
分片是将表中数据按照某种规则放到多个库中,既分表又分库,就相当于原先一个库中的一个表,现在放到了好多个表里面,然后这好多个表又分散到了好多个库中。它可以提高 MySQL 数据库的读写性能,特别是在读多写少的情况下。
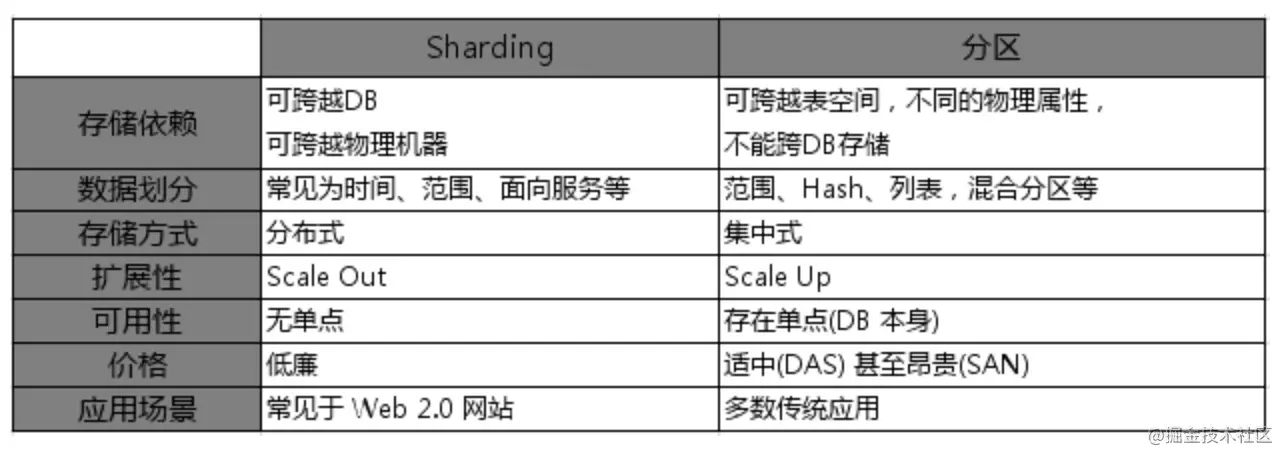
以上是数据库方面的性能增强,总结以上为,单库单表存在性能瓶颈,我们首先突破单表,接着突破单库,突破单机器,将磁盘更换为ssd,增强读写性能。数据库的性能一部分在于自身的局限性,一部分在于硬件的性能。
日常开发中,我们也需要对数据库进行监控,查看cpu数值、硬盘使用率等,监控慢sql,监控数据库连接数。
总结历史问题如下:
1.之前出现过多次,因慢sql导致数据库连接池被打满导致后续无连接问题。
2.也出现过,因多个系统同时连接一个库,导致连接数暴增。
3.亦出现过,因调整服务读写分离,使用不同数据源时,未配置新插件的数据库连接池大小,导致连接数过小,请求数一多,就将数据库链接打满,导致无法响应了。所以设置好服务的数据库连接池数也是重中之重。
4.事务开启过大,导致死锁、回滚时间长、易发生异常回滚、数据库连接池占满、接口性能差
5.通过非索引字段进行更新操作,导致间隙锁的发生,最终死锁。
6.事务中,开启分布式锁,事务结束前,解锁,导致并发问题。
7.查询sql中未对空值进行校验,导致查询全表数据,直接oom
8.查询sql未命中索引,导致查询语句过慢,连接池被打满。
总结以上,慢sql致命。

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









