前言
一、常用聚合函数
| 函数 | 说明 |
|---|
| count(field) | 返回字段的行数 |
| sum(field) | 返回查询到的字段总和,字段类型不是数字则无意义 |
| avg(field) | 返回查询到的字段平均值,字段类型不是数字则无意义 |
| max(field) | 返回查询到的字段最大值,字段类型不是数字则无意义 |
| min(field) | 返回查询到字段的最小值,字段类型不是数字则无意义 |
二、修饰符
| 标识 | 语句 | 描述 |
|---|
| group by | select * from user group by field1 | 根据给定的字段,对查询结果进行分组。一般配合聚合函数使用。多表联查时,group by字段必须与查询结果相匹配 |
| order desc | select * from user order desc | 对查询结果进行排序-降序 |
| order desc | select * from user order asc | 对查询结果进行排序-升序 |
| ORDER BY | SELECT * FROM user ORDER BY field1,field2 DESC | 对查询的结果根据field字段进行排序 ASC升序DESC降序 |
| having | select * from user group by field1 having field2=val | 对分组后的结果进行过滤 |
| where | select * from user where field2=val group by field1 | 对分组前的结果进行过滤 |
二、数据类型
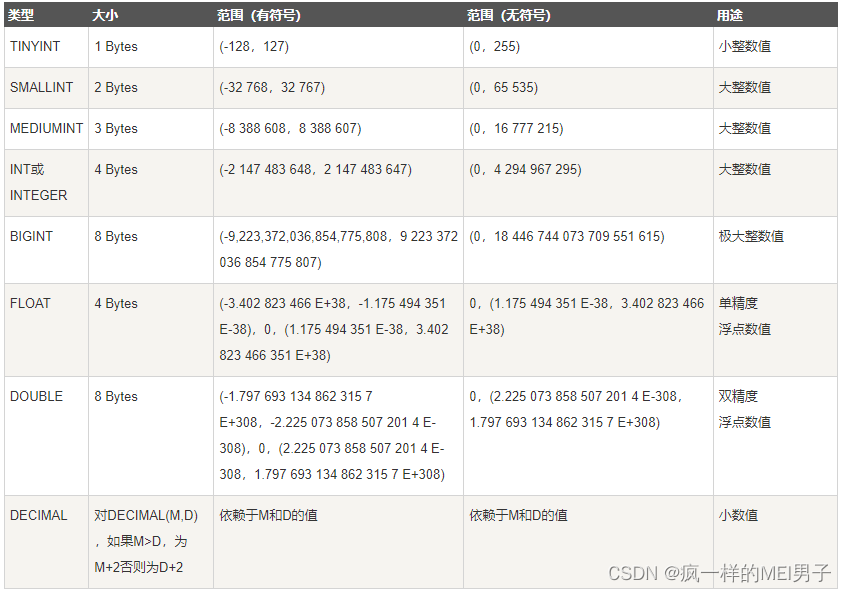
- 数字
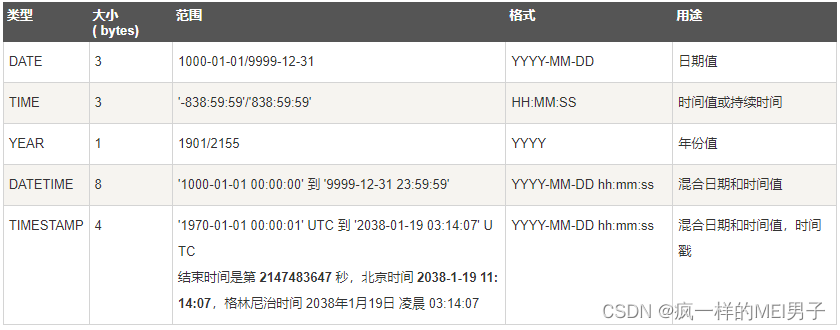
- 时间
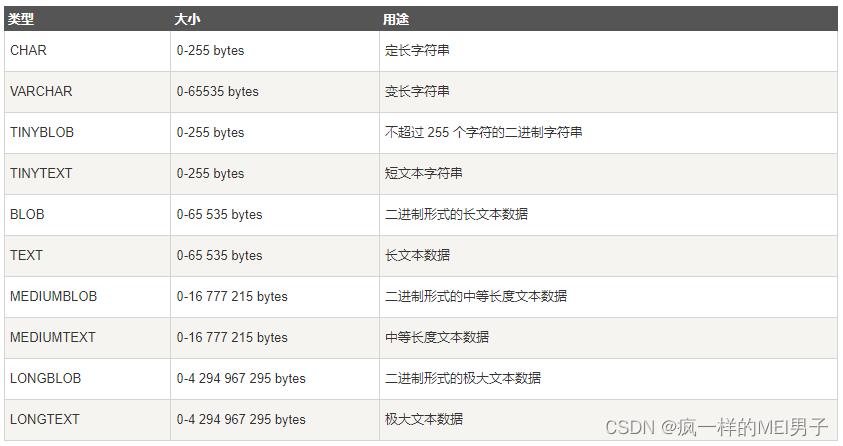
- 字符串
三、多表联查
| 描述 | 示例 |
|---|
| 内连接 | select a_field , b_field from tabel_a,tabel_b where a.id=b.id |
| 外连接 | xs |
| 自连接 | xs |
| 子查询 | xss |
| 合并查询 | 欣赏欣赏 |
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。





 本文介绍SQL中常用的聚合函数如COUNT、SUM、AVG等及其应用场景,并讲解GROUP BY、HAVING等修饰符的作用。同时探讨了数据类型及多表联查的基本方法。
本文介绍SQL中常用的聚合函数如COUNT、SUM、AVG等及其应用场景,并讲解GROUP BY、HAVING等修饰符的作用。同时探讨了数据类型及多表联查的基本方法。


















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











