




 本文介绍了Hadoop集群完全分布搭建的详细步骤。包括使用3台Linux虚拟机设置IP和主机名,配置ssh免密码登录,安装与配置JDK,安装Hadoop集群并修改相关配置文件,最后运行自带Demo进行集群测试,完成整个搭建流程。
本文介绍了Hadoop集群完全分布搭建的详细步骤。包括使用3台Linux虚拟机设置IP和主机名,配置ssh免密码登录,安装与配置JDK,安装Hadoop集群并修改相关配置文件,最后运行自带Demo进行集群测试,完成整个搭建流程。
操作系统:Centos7
JDK:1.8
Hadoop:2.7
全分布我们需要用到三台机器,三台机器配置均如上。
1、使用3台linux虚拟机,设置IP地址和主机名,使得虚拟机和主机互通
(1)编辑/etc/sysconfig/network-scripts/ifcfg-ens33文件,修改IP地址
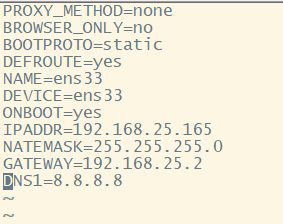
我三台机器的IP地址分别为:
192.168.25.165 192.168.25.175 192.168.25.185
(2)编辑/etc/sysconfig/network和/etc/hostname文件,修改主机名为chenjinyu,从机名分别为slave1和slave2
(3)编辑/etc/hosts文件,配置名字解析

(4)检查虚拟机能够使用名字ping通
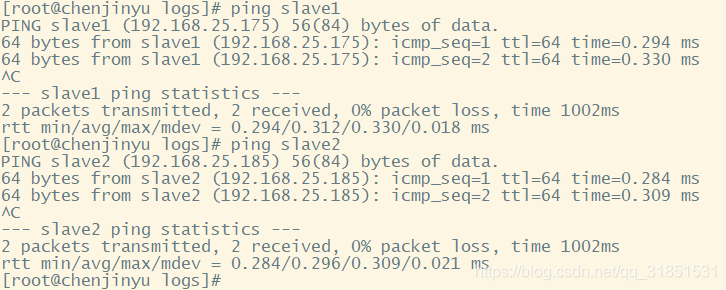
2、配置ssh免密码登录,使用ssh可以免密码登录本机
(1)安装openssh-clients,使用命令生成密钥对
#ssh-keygen -t rsa
(2)把公钥复制到authorized_keys文件(这个文件没有,执行下面这个命令会自动创建该文件)
# cat id_rsa.pub >> authorized_keys
(3)使用ssh免密码登录localhost进行测试
# ssh localhost

(4)接下来打开slave1机器,重复步骤(1),然后将生成的id_rsa.pub复制到主机
cd ~/.ssh
scp id_rsa.pub chenjinyu:~/.ssh/slave1 #这条命令的意思是将slave1里的id_rsa.pub文件传送到chenjinyu机器的~/.ssh文件夹中,并且命名为slave1
(5)打开slave2机器,重复步骤(1)和(4),然后回到主机chenjinyu,查看.ssh文件夹下面的内容
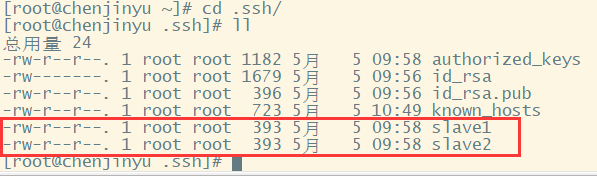
然后我们需要把圈起来的两个文件内容追加到authorized_keys中
cat slave1 >> authorized_keys
cat slave2 >> authorized_keys
执行完这两行命令之后,查看authorized_keys,如果类似于下图这样,说明完成

(6)将authorized_keys文件复制到slave1和slave2
scp authorized_keys slave1:~/.ssh/authorized_keys
scp authorized_keys slave2:~/.ssh/authorized_keys
(7)关闭防火墙,三台机器都要执行下面两条命令
systemctl stop firewalld.service
systemctl disable firewalld.service
(8)然后进行测试,在chenjinyu主机上,直接输入一下命令,第一次输入会需要按一下回车,如有不需要输入密码就能连接到slave1,说明ssh配置完成
ssh slave1

这个时候这个控制台已经是slave1机器了,记得切回主机进行配置操作
···
ssh chenjinyu
···
3、JDK安装与环境配置
(1)一般centos7会自带一个JDK,我们要先将其删除掉,用以下命令查看是否安装了自带的JDK
rpm -qa|grep java
如果有内容显示出来,说明有,使用一下命令进行卸载,如果什么都没有,说明没有自带的JDK
rmp -e --nodeps xxxx #这里的xxx表示直接复制上调命令显示出来的jdk名字,有多少就卸载多少,一个不留
(2)然后上传我们自己的JDK并进行解压
mkdir /usr/java
cd /software #我的jdk我放在这个文件夹下面的,你的JDK放在哪里就去哪里
tar -zxvf 3--jdk-8u181-linux-x64.tar.gz -C /usr/java
(3)配置环境变量
vim /etc/profile
复制以下内容到文本最后面
export JAVA_HOME=/usr/java/jdk1.8.0_181
CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
(4)测试,执行下面两行命令,如果出现版本信息,表示安装JDK成功
source /etc/profile
java -version

4、安装Hadoop集群(完全分布)
(1)解压到/usr目录
tar -zxvf 1--hadoop-2.7.7.tar.gz -C /usr
(2)配置环境变量,复制下面文本到/etc/profile最后面
export HADOOP_HOME=/usr/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONFIG_DIR=$HADOOP_HOME/etc/hadoop
刷新环境变量进行测试,出现以下内容表示安装成功
source /etc/profile
hadoop version

(3)将配置文件复制到另外两台机器
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile
(4)修改Hadoop配置文件
1)hadoop-env.sh,这个文件里面已经有下面的内容,你只需要修改一下即可
export JAVA_HOME=/usr/java/jdk1.8.0_181
2)core-site.xml,添加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://chenjinyu:9000</value>
</property>
3)hdfs-site.xml,添加以下内容
<property>
<name>dfs.namenode.http-address</name>
<value>chenjinyu:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>chenjinyu:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop-2.7.7/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/usr/hadoop-2.7.7/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4)mapred-site.xml(需要复制模板)
cp mapred-site.xml.template mapred-site.xml
添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>chenjinyu:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>chenjinyu:19888</value>
</property>
5)yarn-env.sh,在最后添加以下内容
export YARN_PID_DIR=/usr/hadoop-2.7.7/tmp
export JAVA_HOME=/usr/java/jdk1.8.0_181
6)yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>chenjinyu:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>chenjinyu:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>chenjinyu:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>chenjinyu:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>chenjinyu:8088</value>
</property>
7)新建文件,名为masters
vim masters
输入以下内容
chenjinyu
8)修改slaves文件内容,删掉原来的内容,输入以下内容
slave1
slave2
(5)将hadoop整个文件夹复制到两台从机
scp -r /usr/hadoop-2.7.7 slave1:/usr/
scp -r /usr/hadoop-2.7.7 slave2:/usr/
(6)分别刷新从机上面的配置文件,并且做测试,如果出现版本信息,表名安装成功
source /etc/profile
hadoop version
(7)启动hadoop,在主机上面输入格式化命令和启动命令
hdfs namenode -format
start-all.sh
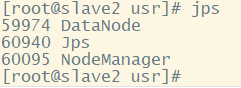
(8)查看jps,主机有四个进程,从机3个,少一个都不行,如果你的少了,去logs文件夹下面查看.log格式的日志,看看报的什么错误,然后进行修改,我没有遇到什么错误,一次成功,一般的错误都是配置文件中输入有误导致的,仔细检查。
chenjinyu:
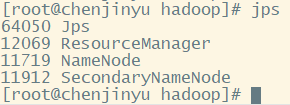
slave1:
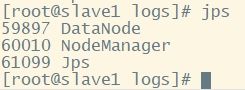
slave2:
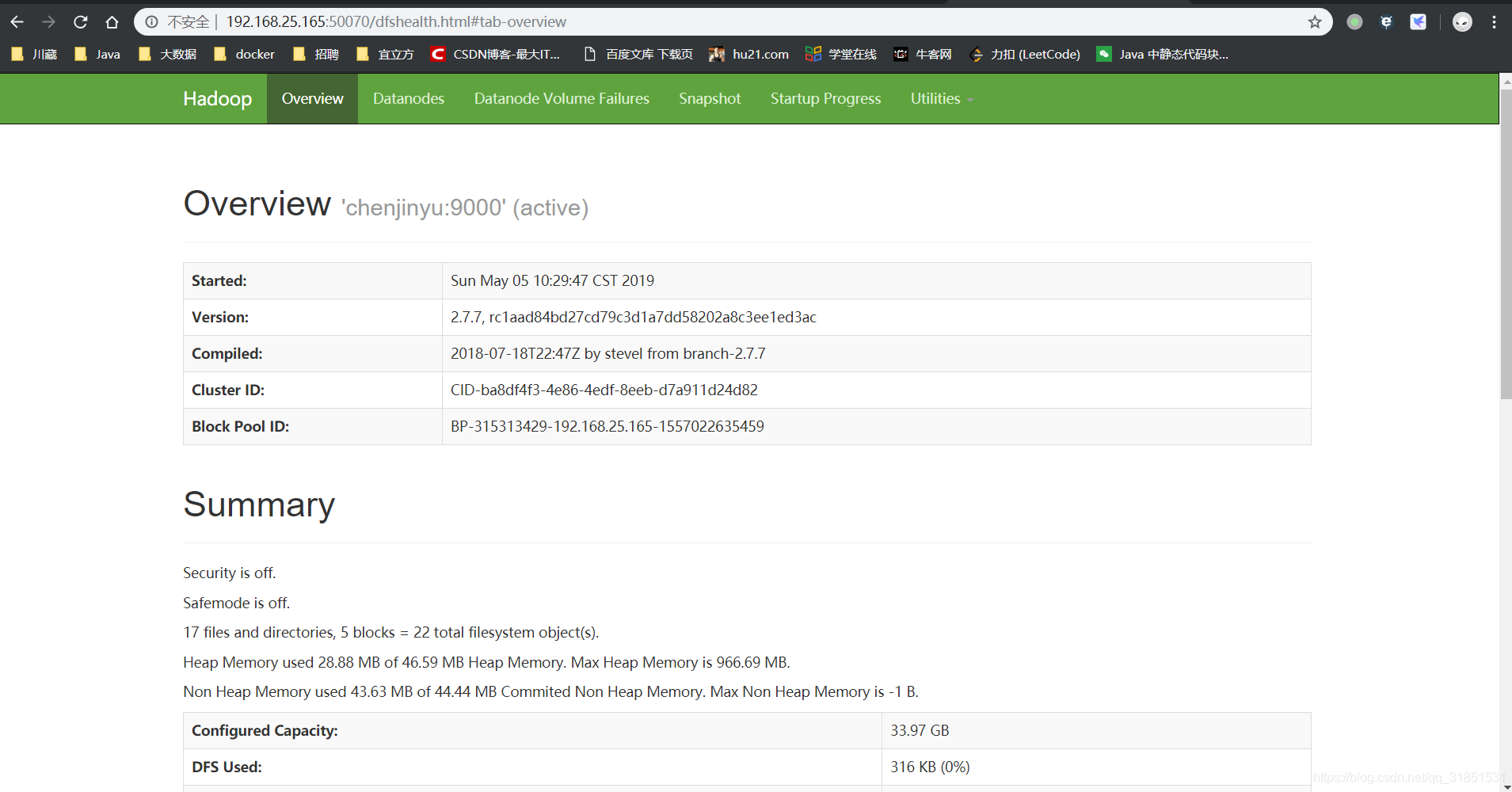
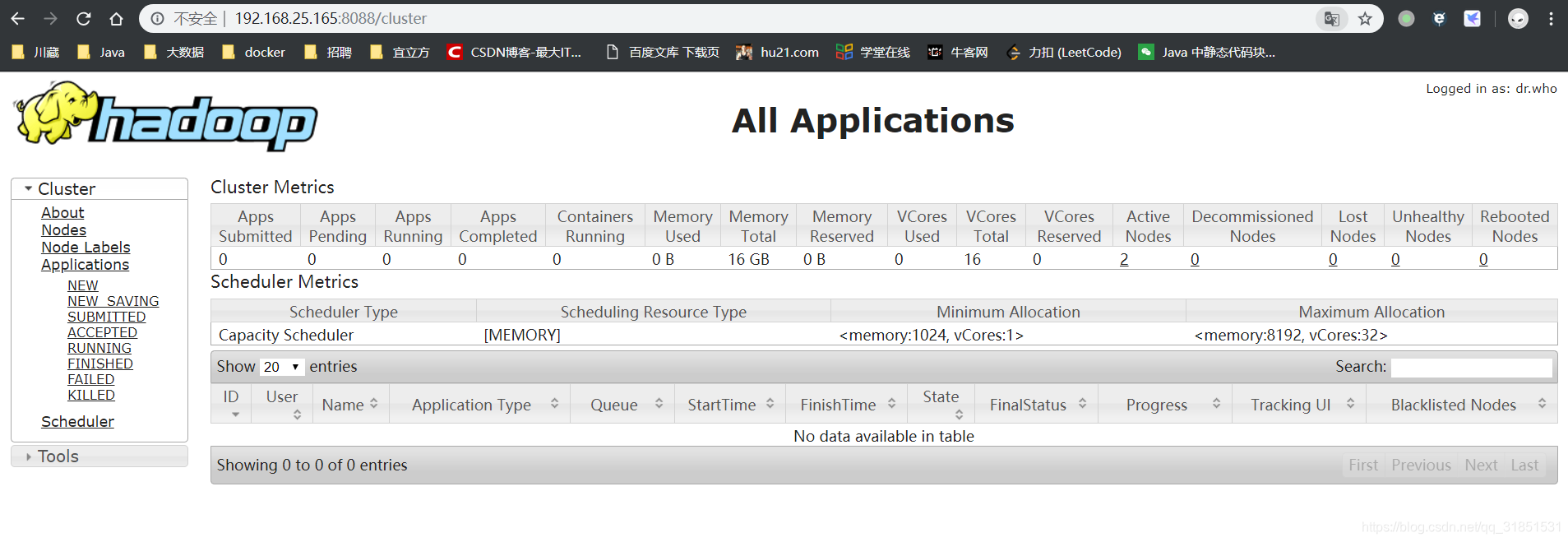
(9)查看网页是否启动成功,两个都出来说明成功
浏览器地址栏输入:IP地址:50070
浏览器地址栏输入:IP地址:8088
5、运行自带Demo,测试集群
(1)在HDFS中创建input文件夹
hadoop fs -mkdir /input
(2)将需要分析的txt文件移动到HDFS的input文件夹下,这里选取的是hadoop-2.7.7文件夹下的LICENSE.txt文件
hadoop fs -put /usr/hadoop-2.7.7/LICENSE.txt /input
(3)运行Hadoop示例程序WordCount
hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
该命令不解释了,不懂得可以去看看上一篇伪分布 ,一样的命令。

运行完之后就应该是上面这样,运行会需要一点时间,耐心等待。
(4)查看运行结果
hadoop fs -ls /output
hadoop fs -cat /output/part-r-00000

运行结果长下面这样:
恭喜你,完全分布搭建完成,并且进行了一次案例测试。

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









