




 介绍了一种使用递归自编码器进行句子情感分类的方法。该方法无需预设情感词汇或规则,能从无标签数据中学习词汇及句子表示,并预测复杂情感分布。
介绍了一种使用递归自编码器进行句子情感分类的方法。该方法无需预设情感词汇或规则,能从无标签数据中学习词汇及句子表示,并预测复杂情感分布。
读论文《Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions》
文章主要介绍了使用递归自编码器做句子情感分类的方法。和之前的方法相比,本文的算法没有使用任何预设定的情感词汇和极性转换规则。并在movie reviews数据集上取得了SOTA的效果。
当时主流的方法还是词袋模型,但词袋模型无法很好的句法信息,而一些改进则利用的是一些手工特征(如:情感词,解析树,极性转换规则)
本论文的创新:
- 使用层次结构和成分语义信息
- 可以使用无标签数据,也可以监督学习,且不需要手工特征
- 没有把情绪限制在积极/消极, 而把情绪映射到一个复杂的相互关联的分布
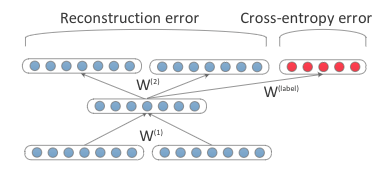
文章介绍了一个使用半监督学习的递归自编码器,它以词嵌入为输入,使用层次的结构从非监督文本中学习词汇和句子表示,并使用层次结构中的节点来预测情感标签的分布。
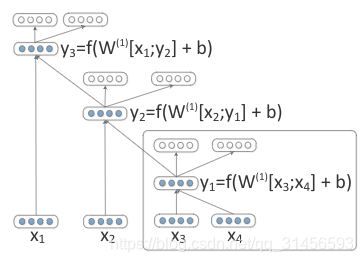
父节点表示:
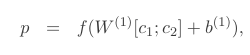
这样就可递归获取句子的语义表示。
同时,我把父节点解码为原词语表示,以达到自编码器无监督训练的效果。
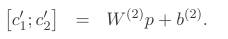
作者使用重构词和原词的分布的欧式距离作为重构误差。
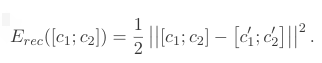
Greedy Unsupervised RAE:
每一次,都会便利当前的所有节点,并把重构误差最小的那两个合并,用合并的父节点代替这两个节点,然后重复操作。
Weighted Reconstruction:
为了让拥有更多子节点的点拥有更多的权重,作者对重构误差进行了调整。(n为子节点个数)
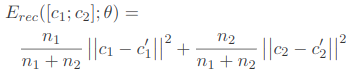
Length Normalization:
为避免通过过度降低隐藏重构误差的方法来使总体重构误差更小,作者使用了长度归一化
最后使用句子节点经过softmax进行分类
整体损失函数如下
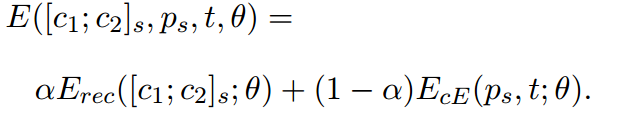


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









