




消息中间件Kafka入门
百度百科:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
通过查看官网:
Apache kafka官网上一句话:Apache Kafka® 是 一个分布式流处理平台。
根据官网介绍流处理平台具有三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafa特性
-
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
-
高吞吐量 :即使是非常普通的硬件Kafka也可以支持每秒数百万 的消息。
-
支持通过Kafka服务器和消费机集群来分区消息。
-
支持Hadoop并行数据加载。
Kafka两大应用场景:
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)。
构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)。
Kafka核心API:
Kafka有四大核心API:The Producer API、The Consumer API、The Streams API、The Connector API。四大核心组件作用如下:
The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
核心API关系图如下所示:
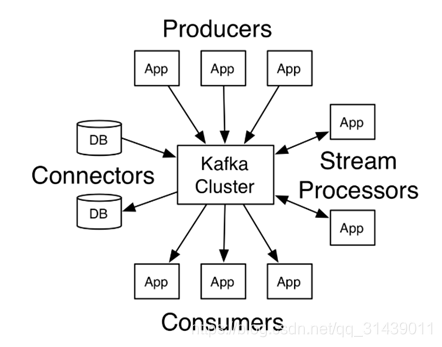
注:图片引自官网

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









