




第一天
三一重工
- 今年这形势,只要有公司招,就得投啊!
- 每次问题回答到一半,就问下一个,全程8分钟结束。
- 自我介绍
- 嵌入式和Java都用过,熟悉哪个
- 类加载机制说一下
- 类加载器都有哪些
- redis用过吗?除了用作缓存还能干啥?
- 分布式锁介绍一下
- springboot用过吗?简单说一下
- springboot启动方式说一下
解:直接在idel中运行main函数,在springboot项目目录下运行 mvn:项目名:run,maven打包成jar后输入: java -jar 项目名
- 责任链模式有什么好处
解:(1)首先,很长的if-else结构或很长switch-case结构不见了,取而代之的是直接把处理情景交给一个责任链即可,代码十分简洁
(2)之前每个分支的代码,在责任链模式中,会被分布放到不同的处理类中。虽然类的个数不算少,但每个类的指责十分单一,便于维护。
- lambda表达式好处:延时运行,代码简洁
- MySQL的优化方式
- 能接受其他工作地点吗?
- 祈祷总经理面🙏
第二天
平安壹钱包Java面经
1、自我介绍
2、JVM内存分区
3、垃圾回收有哪些算法
4、hashmap的数据结构
5、数组和链表的区别
6、B树和B+树的区别
7、多线程比单线程的优势,在什么情况下适合用多线程?多线程的劣势?
8、说一下对SpringIOC的理解
9、MySQL引擎用过哪些?区别?MySQL优化?
10、用过哪些缓存?redis为什么这么快?
解:https://zhuanlan.zhihu.com/p/81195864
11、SpringBoot比Spring的优势在哪里?
12、三次握手和四次挥手?
13、业余外除了学习java还学了什么?简单介绍一下
14、没有返校,学校的课程是怎么安排的?期末考试呢?
15、实习时间7月初-10月底可以吗?
16、学习成绩?期望薪资?
第三天
安恒信息
一面
- Http 的执行过程?
- TCP三次握手过程
- TCP中第一次Seq是如何产生的?
- linux,shell命令,编写计算nginx日志中访问最多的100个ip
- 如何编程实现?排序的时间复杂度?如何优化?
- 进程、线程、协程的区别
- python中多进程和多线程的区别
- 做题:二叉树右视图,先探讨了一下方案和时间复杂度、空间复杂度,然后要求把空间复杂度降到O(logN),开始写代码,写得很磕磕绊绊
二面
- 先聊了会人生,为什么当时拒了字节的实习,为什么选择开发岗...
- 说了下在蚂蚁金服的短暂的实习期间干的事情,一个分布式的转账demo,开始聊分布式
- 二阶段提交协议的实现方法探讨(主要讲了蚂蚁内部某分布式事务框架的实现思想)
解:https://www.cnblogs.com/balfish/p/8658691.html
https://www.cnblogs.com/leeSmall/p/9571514.html
- 二阶段提交协议的缺点,以及三阶段提交协议如何弥补这些缺点
- 其他的分布式框架,聊了下RAFT,主要讲了RAFT的leader选举策略
- RAFT 如何克服数据分区(Split-brain)的问题
- RAFT 实现了CAP中的哪两个原则
- 开始聊数据库,事务的隔离级别有哪几种
- 可重复读的实现方式,是否了解MVCC(完全没听过)
- MySQL(Innodb)锁的类型及作用(没答全)
解:innodb行级锁的模式和加锁方法
nnoDB到底有几种锁?
(1) 共享/排它锁(Shared and Exclusive Locks)
(2) 意向锁(Intention Locks)
(3) 记录锁(Record Locks)
(4) 间隙锁(Gap Locks)
(5) 临键锁(Next-key Locks)对应非唯一索引
(6) 插入意向锁(Insert Intention Locks)
(7) 自增锁(Auto-inc Locks)
innodb实现了两种模型的行锁:
1.共享锁(S):允许一个事务去读一行,阻止其它事务获得相同数据集的排他锁
2.排他锁(X):允许获得排他锁的事务更新数据,阻止其它事务取得相同数据集的共享锁和排他锁
innodb同时为了支持表锁和行锁的共存,实现多粒度的锁定机制,还有两种意向锁(intention locks):
1.意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加锁前必须获得该表的IS锁
2.意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加锁前必须获得该表的IX锁
四种锁的兼容情况如图:
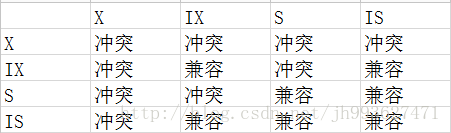
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT ... LOCK IN SHARE MODE
排他锁(X):SELECT ... FOR UPDATE
innodb行锁的实现方式
innodb行锁是通过给索引上的索引项加锁来实现的,如果没有索引,innodb将通过隐藏的聚簇索引来对记录加锁。innodb的行锁分为三种:Record lock、Gap lock、Next-Key Locks
Record lock
单条索引记录上加锁,record lock锁住的永远是索引,而非记录本身,即使该表上没有任何索引,那么innodb会在后台创建一个
隐藏的聚集主键索引,那么锁住的就是这个隐藏的聚集主键索引。所以说当一条sql没有走任何索引时,那么将会在每一条聚集索引后面加X锁,这个类似于表锁
Gap lock
在索引记录之间的间隙中加锁,或者是在某一条索引记录之前或者之后加锁,并不包括该索引记录本身。
产生间隙锁的条件(RR事务隔离级别下;):
- 使用普通索引锁定;
- 使用多列唯一索引;
- 使用唯一索引锁定多行记录。
对上面三点的描述:对于使用唯一索引来搜索并给某一行记录加锁的语句,不会产生间隙锁。(这不包括搜索条件仅包括多列唯一索引的一些列的情况;在这种情况下,会产生间隙锁。)例如,如果id列具有唯一索引,则下面的语句仅对具有id值100的行使用记录锁,并不会产生间隙锁:
SELECT * FROM child WHERE id = 100 FOR UPDATE; 这条语句,就只会产生记录锁,不会产生间隙锁。
Next-Key Locks
在默认情况下,mysql的事务隔离级别是可重复读,并且innodb_locks_unsafe_for_binlog参数为0,这时默认采用next-key locks,所谓Next-Key Locks,就是Record lock和gap lock的结合,即除了锁住记录本身,还要再锁住索引之间的间隙。
例如:某普通索引列当前值有:1, 10, 20,那么此时它的防插入锁区间分别是:
(-∞, 1], (1, 10], (10, 20], (20, +∞)
那最终我们就可以得知,在根据非唯一索引 对记录行进行 UPDATE \ FOR UPDATE \ LOCK IN SHARE MODE 操作时,InnoDB 会获取该记录行的 临键锁 ,并同时获取该记录行下一个区间的间隙锁。
即事务 A在执行了上述的 SQL 后,最终被锁住的记录区间为 (10, 32)。
InnoDB的默认事务隔离级别是RR,在这种级别下,如果你使用select ... in share mode或者select ... for update语句,那么InnoDB会使用临键锁,因而可以防止幻读;但即使你的隔离级别是RR,如果你这是使用普通的select语句,那么InnoDB将是快照读,不会使用任何锁,因而还是无法防止幻读。
注意:innodb通过范围条件加锁时使用next-key锁外,如果使用相等条件请求给一个不存在的记录加锁,innodb会使用next-key锁
下列SQL语句自带的行锁级别为:
insert——记录锁、update——防插入锁、delete——防插入锁
此外,若查询的列包含唯一索引或主键,则行锁将被自动降级到记录锁
(1)在不通过索引条件查询时,innodb会锁定表中的所有记录,innodb引擎支持行锁,但在不使用索引或无索引的时候会使用表锁
(2)mysql的行锁是针对索引加的锁,所以虽然是访问不同行的记录,如果使用相同的索引键,是会出现锁冲突的
(3)当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,不论是使用主键索引,唯一索引或普通索引,innodb都会使用行锁来对数据加锁
(4)即使在条件中使用了索引字段,但是否使用索引来检索数据是由mysql通过判断不同计划的代价来决定的,如果mysql认为全表扫描效率更高,它就不会使用索引,这种情况下innodb会对所有记录加锁。
————————————————
表锁:mysql中锁粒度是最大的,不会出现死锁;
行锁:锁粒度最小的,因此锁定资源发生的正用也就最小,提高了并发的能力,但每次都要获取和释放带来了性能消耗,易发生死锁;
叶锁:锁粒度介于表锁和行锁之间,其他和行锁相似;
彩蛋:innodb存储引擎与myisam最大的不同就是:innodb支持事务;采用行级锁
- 乐观锁的实现方式(只说了Java上的CAS方式,完全不知MVCC)
- 间隙锁?
- 索引为什么选B+树而不是B树
- B+树的缺点
解:https://segmentfault.com/a/1190000020416577?utm_source=tag-newest
优点:
- 单次请求涉及的磁盘IO次数少(出度d大,且非叶子节点不包含表数据,树的高度小);
- 查询效率稳定(任何关键字的查询必须走从根结点到叶子结点,查询路径长度相同);
- 遍历效率高(从符合条件的某个叶子节点开始遍历即可);
缺点:
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
- 开始聊操作系统,虚拟内存和物理内存的区别
- 页式内存管理系统中的虚拟内存到物理内存的加载方法以及页淘汰策略
- 在程序中取地址得到的是物理地址还是虚拟地址
- 进程间通信方式
- 信号和信号量的区别
- 智力题:圆形桌子,A和B下棋,棋子是圆的,A先走,每人轮流下,一次只能下一颗(不能不下),如何保证A一定赢?
- 算法题:顺时针打印矩阵
总结
算法题刷得不够熟练,需要再练习。做题的时候遇见不会的明显紧张了,一面结束后没多久就反应过来那个题其实蛮简单的,但是我最后还是写错了。。。
二面结束后问了下面试官能不能给我的秋招如何准备一点建议,他说写在简历上的东西一定要熟悉,MySQL那一块我蛮多的问题没有答上来(我简历上确实写了熟悉Redis/Mysql...)
第四天
shein提前批
端午前一天,也就是24号结束的一面,拖了好几天才来写面经,哈哈哈哈哈
一面(35min)6.24
首先是进行大约5分钟的闲聊,然后正式开始面试
0、自我介绍
1、什么是面向对象编程
解:https://zhuanlan.zhihu.com/p/75265007
2、Java三大特性
3、事务有哪些隔离级别,Mysql默认的是什么隔离级别
4、Java常用的集合类有哪些
5、你使用过哪些设计模式,挑几个重点讲一讲实现
6、双重校验锁如何实现?(这里我回答漏了voliate关键字)
7、Java中的抽象类和接口有什么区别?
8、抽象类中可以定义变量,编写实现吗?
9、Mybatis和Hibernate有什么区别?你为什么两个都使用了?
10、Mybatis底层如何绑定参数?#{}和${}有什么区别?
MyBatis在处理#{}时,会将SQL中的#{}替换为?号,使用PreparedStatement的set方法来赋值;MyBatis在处理 $ { } 时,就是把 ${ } 替换成变量的值。

源码解析:https://www.cnblogs.com/gzy-blog/p/6079512.html
彩蛋:依次查询的过程
11、你简历中提到了你手写过ORM框架,能和我简单介绍一下吗?
12、JVM有了解过吗?它管理的内存区域分为哪些?
13、对象创建的过程?(从类加载机制说起)
14、单点登陆如何实现的?
15、redis中有哪些存储类型?底层数据结构分别是什么?
https://www.cnblogs.com/ysocean/p/9080942.htmlv
16、项目中分布式架构的具体技术选型及其原因?
17、能来实习吗?
18、在导师项目组工作的情况?
最后和面试官吐槽了一下现在导师项目组的项目都要多数据源切换,写起来特别烦巴拉巴拉,就结束了
总体而言面试官人特别好,虽然有时会突然严肃,但是大多是时候都是面带笑容的。(并且从面相上一看就是强者🤣)
第五天
- 为什么要自定义协议
- 你还知道有那些通信协议
- 现在写一个序列化反序列化方法(手撕代码)
写的很差。。。当时只记得用tostring方法写成变量名字+value
解:jdk自带的序列化方法:
class User implements Serializable{
int id;
String name;
int age;
public User() {
}
public User(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class LeetCode {
public static void main(String[] args) throws Exception {
FileOutputStream fos=new FileOutputStream("C:\\Users\\adminstors\\Desktop\\Object.out");
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(new User(1,"lhc",27));
oos.flush();
oos.close();
fos.close();
FileInputStream fis=new FileInputStream("C:\\Users\\adminstors\\Desktop\\Object.out");
ObjectInputStream ois=new ObjectInputStream(fis);
User user2=(User) ois.readObject();
System.out.println(user2.toString());
}
}- 为什么不能用文本的方法传递消息(加大带宽,不安全)
- 讲一下tcp挥手
- 你觉得别的im时延是多少?
- 多设备登录怎么实现。
答的不好 - 如果设备掉线了,怎么发现处理?你知道心跳嘛?
答的不好 - malloc,realloc,callo
不会 - euqal ===
解:最大的区别是,==是运算符,equal是方法。
其次看看他们的代码:
equals方法:也使用了==这个符号
public boolean equals(Object obj) { return (this == obj); }总结:默认情况下也就是从超类Object继承而来的equals方法与‘==’是完全等价的,比较的都是对象的内存地址,但我们可以重写equals方法,使其按照我们的需求的方式进行比较,如String类重写了equals方法,使其比较的是字符的序列,而不再是内存地址。
彩蛋:重写equal()时为什么也得重写hashCode()?
从hashmap存储结构理解,同个hashcode存储在同一个“桶”。如果只重写了equal方法,会出现equal方法为true而hashcode方法为false
相等的对象必须具有相等的散列码
- define const
- volatile
- 你对于i/o 模型的了解
没有深入 - 你了解的设计模式都有哪些?
- 单例模式(手撕代码)
- linux cat echo
解:cat 是文本输出,作用对象是一个文件,
echo 是标准输出,相当于程序中的println,
- 杀掉名字里有 “abc”的线程 一条命令
不会应该是用xargs - 进程线程间通信,进程线程的区别
当时大脑短路了,应该是锁+共享内存+套接字消息队列等方式 - 手撕代码 3sum
public static void main(String[] args) throws Exception {
int[] nums = {-1, 0, 1, 2, -1, -4};
List<List<Integer>> res = new ArrayList<>();
int leg = nums.length;
Arrays.sort(nums);
for (int i = 0; i < nums.length; i++) {
if (nums[i] > 0) break;
if (i > 0 && nums[i] == nums[i - 1]) continue;
int left = i + 1, right = nums.length - 1;
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
if (sum == 0) {
List<Integer> list = new ArrayList<>();
list.add(nums[i]);
list.add(nums[left]);
list.add(nums[right]);
res.add(list);
while (left<right && nums[left + 1] == nums[left]) left++;
while (left<right && nums[right - 1] == nums[right]) right--;
left++;right--;
} else if (sum > 0) {
right--;
} else {
left++;
}
}
}
}

















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









