







仅用于学习交流,未做商业用途,侵权请联系本人删除!!!(原文地址:BFC是什么?10 分钟讲透BFC 原理)
1. 引言
在前端的布局手段中,一直有这么一个知识点,很多前端开发者都知道有它的存在,但是很多人也仅仅是知道它的存在而已,对它的作用也只是将将说得出来,可是却没办法说得非常的清晰。这个知识点,就是BFC。想要了解BFC的规则,前提必须是熟悉前端网页的多种布局手段,例如盒的显示模式display,三种布局手段标准流(normal)、浮动流(float)、定位流(position)等。你只有熟练掌握了这些布局手段之后,才能很好的理解BFC。今天这篇文章,来大家解析一下BFC,希望对各位新老朋友有所帮助。
2. 定义
BFC - Block Formatting Context 块级格式化上下文 BFC的定义,在官方文档到中,是这么介绍BFC的。
A block formatting context contains everything inside of the element creating it that is not also inside a descendant element that creates a new block formatting context.
强行翻译一下吧,简单来说,这句话的意思就是:
一个BFC区域包含创建该上下文元素的所有子元素,但是不包括创建了新的BFC的子元素的内部元素
很显然,哪怕强行翻译了,大部分人依旧是看不懂这句话的。看都看不懂,那自然就没什么能把它说明白。talk is cheap, show me the code.看不懂意思,我用代码来给你演示。
<div class="box1" id="HM_bfc1">
<div class="box2"></div>
<div class="box3"></div>
<div class="box4"></div>
<div class="box5" id="HM_bfc2">
<div class="box6"></div>
<div class="box7"></div>
<div class="box8"></div>
</div>
</div>用这段代码来解释上面那段BFC定义的话,就应该是这个意思:#HM_bfc1是一块BFC区域,这块区域包含了box2、box3、box4、box5,也就是所有#HM_bfc1的子元素。同时#HM_bfc2也创造了一块BFC区域,包含了box6,box7,box8。注意,第一个box1的BFC,只包括box1的子元素box2345,不包括box678。#HM_bfc2这个BFC同样也仅仅是包括自己的子元素box678。
划重点
每一个BFC区域只包括其子元素,不包括其子元素的子元素。(这1点比较容易理解)
每一个BFC区域都是独立隔绝的,互不影响!(这点不太好理解,但是后续会使用代码验证)
看完上面的描述,很多朋友依旧不懂,把第2节用心的再读一遍,相信你会有新的收获。然后往下继续阅读,你会豁然开朗。
3. 触发BFC
并不是任意一个元素都可以被当做BFC,只有当这个元素满足以下任意一个条件的时候,这个元素才会被当做一个BFC。
触发BFC的条件
·body根元素
·设置浮动,不包括none
·设置定位,absoulte或者fixed
·行内块显示模式,inline-block
·设置overflow,即hidden,auto,scroll
·表格单元格,table-cell
·弹性布局,flex
上代码说明

首先, body元素是1个BFC,因为它满足我们的第1个条件(body根元素),这个BFC区域包含子元素hm1234,但是不包括两个p标签,需要注意的是,hm3不是一个BFC区域,因为他不满足上面任意1个条件。如果我们希望hm3也是1个BFC区域,只要让hm3满足上面任意一个条件即可。
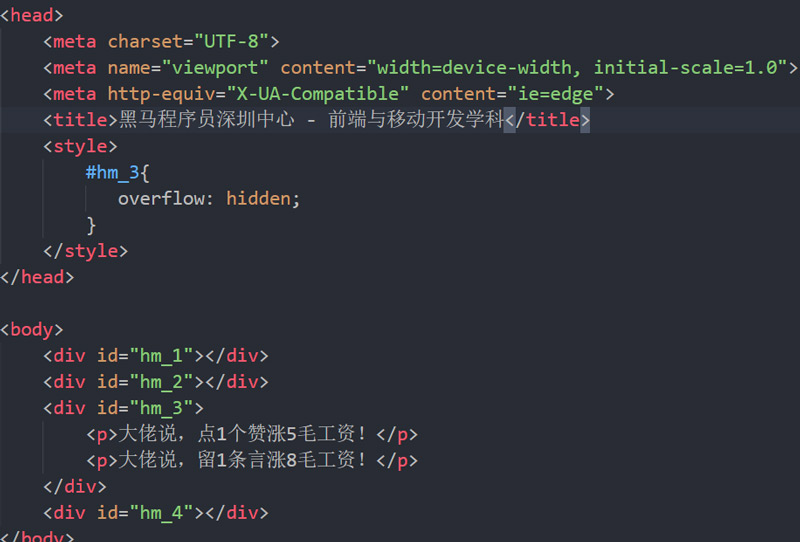
这个时候,hm3元素被设置为了overflow为hidden,满足上面第5个条件,所以此时,hm3就成为了一个BFC区域,这个BFC区域包含其所有子元素 – 两个p标签。
划重点:
并不是所有的元素都是BFC, 只有满足了上面的任意1个条件之后,这个元素才成为1个BFC。
一个BFC区域,只包含其所有子元素,不包含子元素的子元素。
4. 利用BFC解决问题
在你明白了解BFC的触发规则之后,那么就需要利用BFC的特点来解决我们在布局中遇到的一些问题了,还记得我们之前说过,BFC有一个特点是:每一个BFC区域都是相互独立,互不影响的。
4.1 解决外边距的塌陷问题(垂直塌陷)
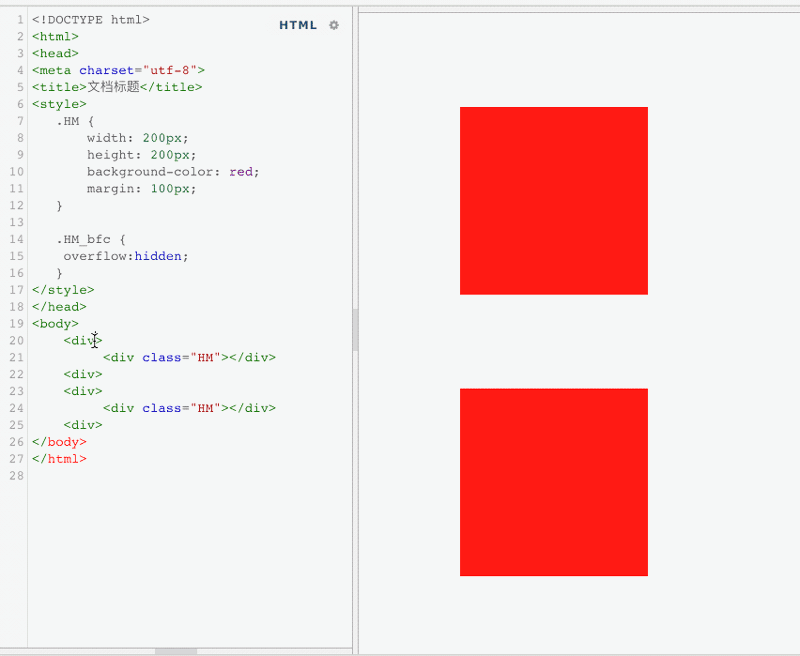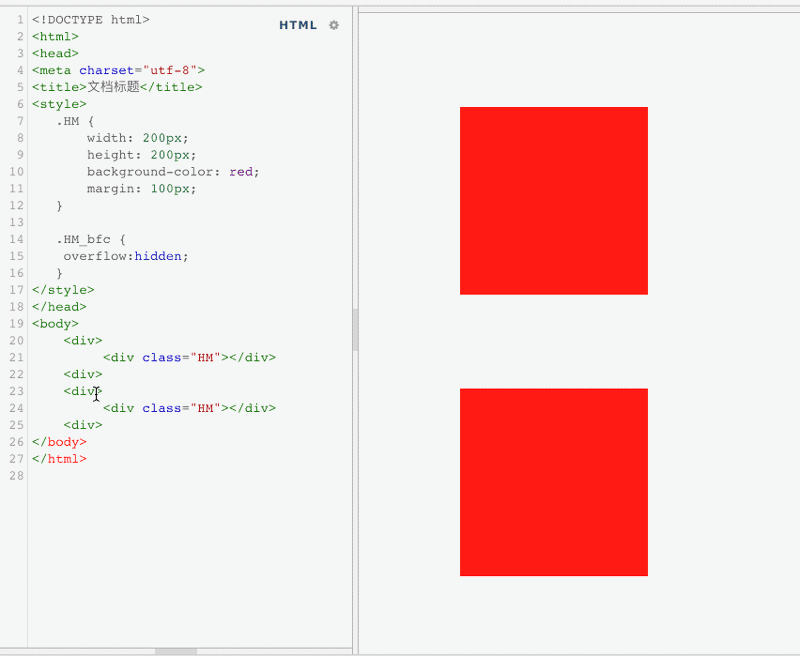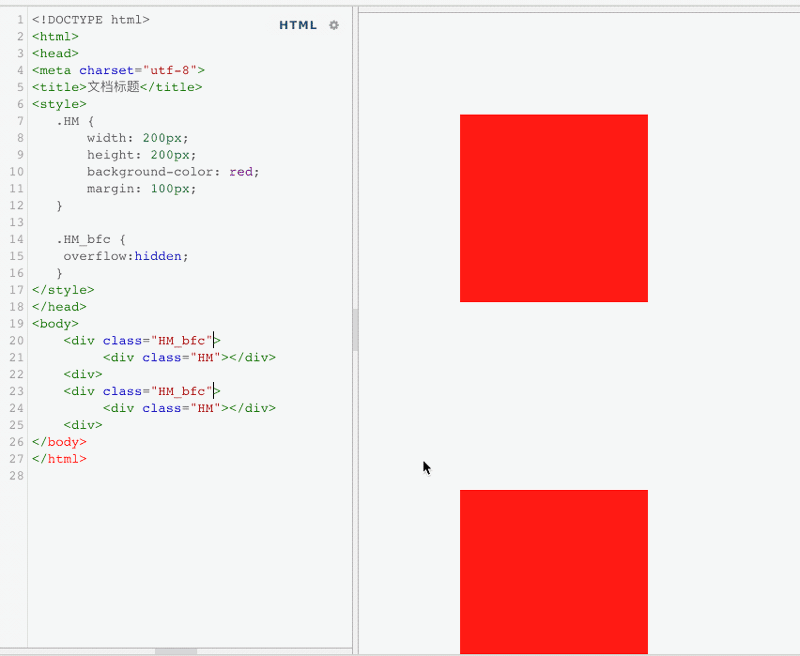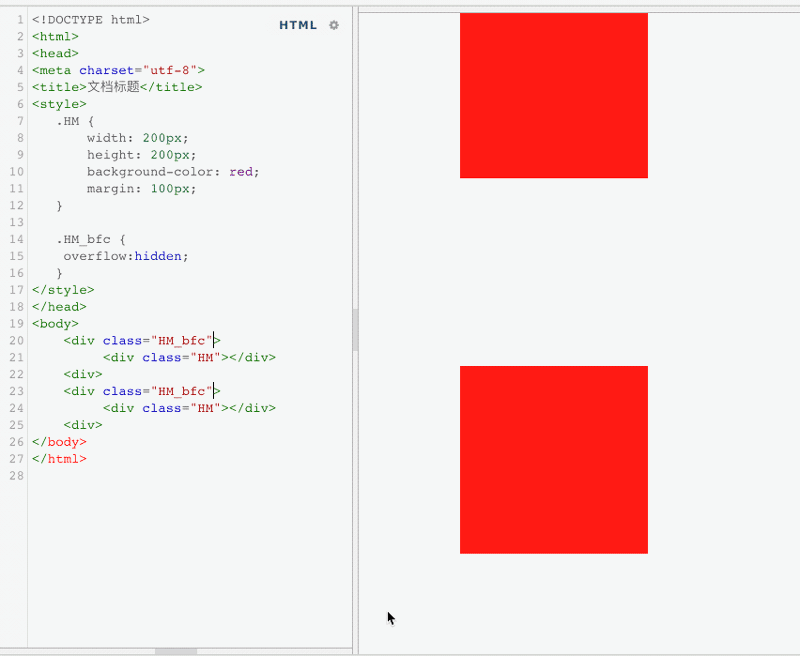
开发中,前端的布局手段,离不开外边距margin,那么,也会遇到一些问题,例如外边距的垂直塌陷问题。
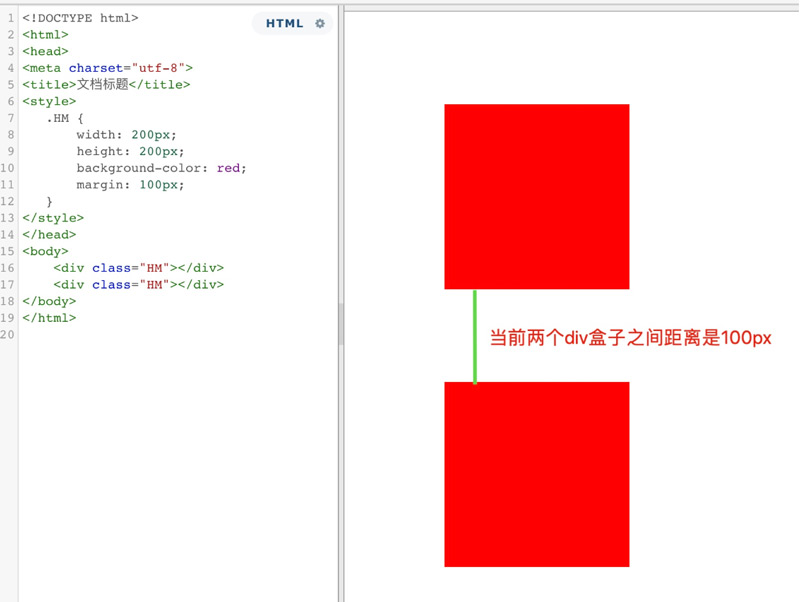
通过以上的实例,我们会发现,代码给两个div盒子,都添加了四个方向的margin,讲道理,学过数学的都知道,100+100=200.可是,盒子之间的距离,现在却之后100px。这就是很典型的margin的塌陷,两段margin重叠到了一块,互相影响。那么,如何利用BFC,让这个问题得到解决呢。回忆下,上文说过,BFC,就是一个与世隔绝的独立区域,不会互相影响,那么,我们可以将这两个盒子,放到两个BFC区域中,即可解决这个问题。
4.2 利用BFC解决包含塌陷
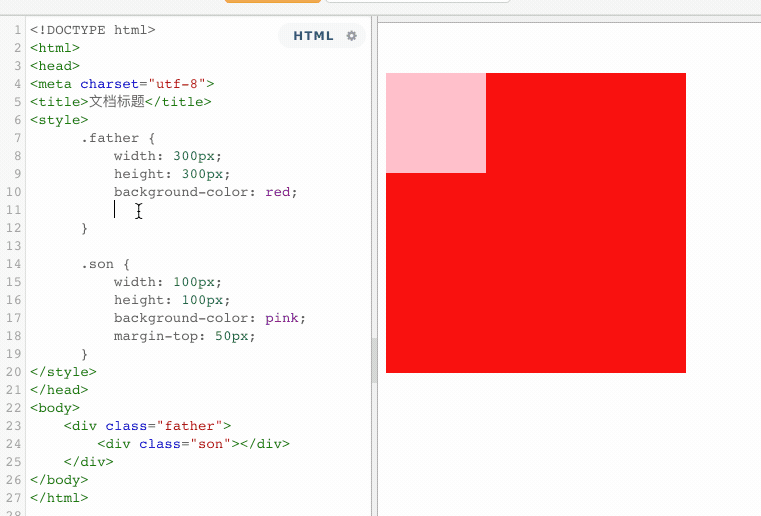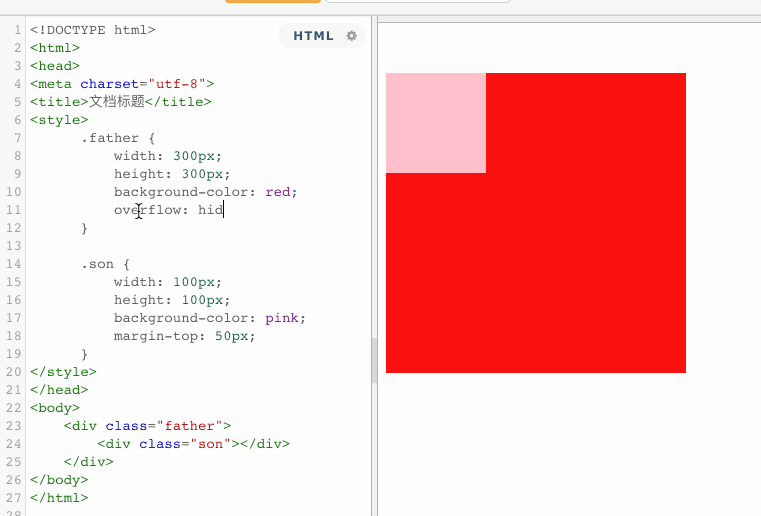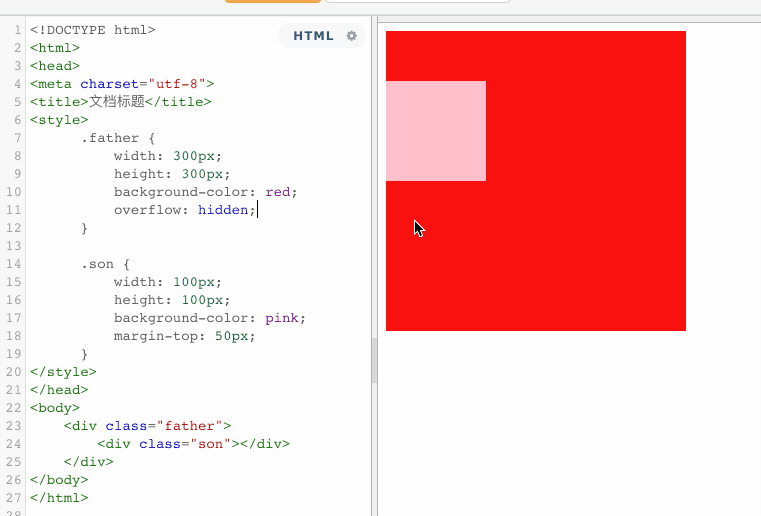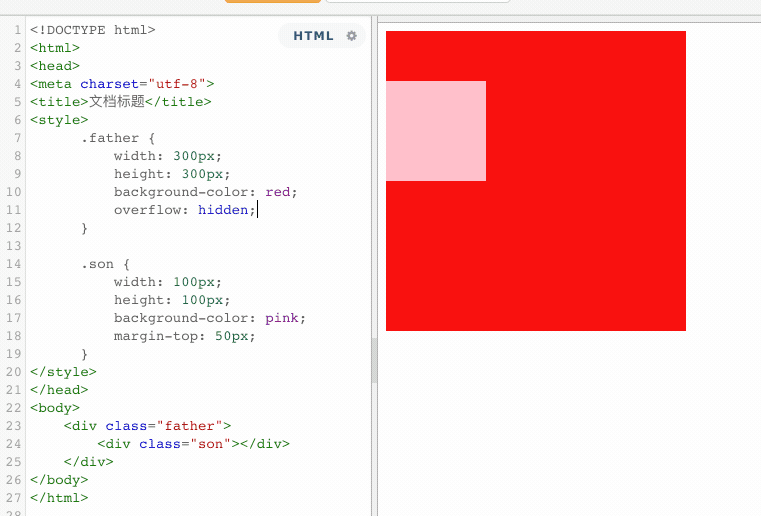
当父子关系的盒子,给子元素添加margin-top,有可能会把父元素一起带跑。
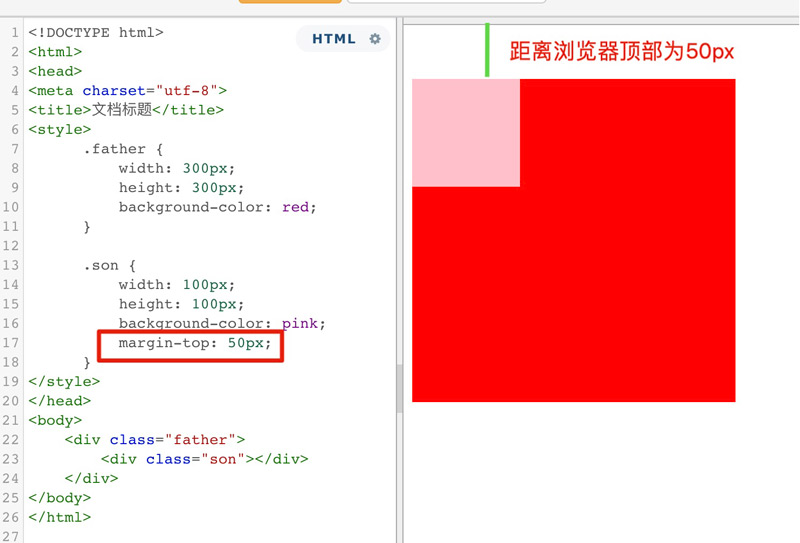
原本,正确的显示方式,应该是粉色盒子与红色盒子的顶部距离为50px,但是由于margin的塌陷问题,导致盒子内部的布局影响到了外部。这个时候,就可以触发BFC,将父盒子变成一个独立的区域,这样在BFC区域内部的任何操作,都不会影响到外部。
4.3 当浮动产生影响的时候,可以利用BFC来清除浮动的影响
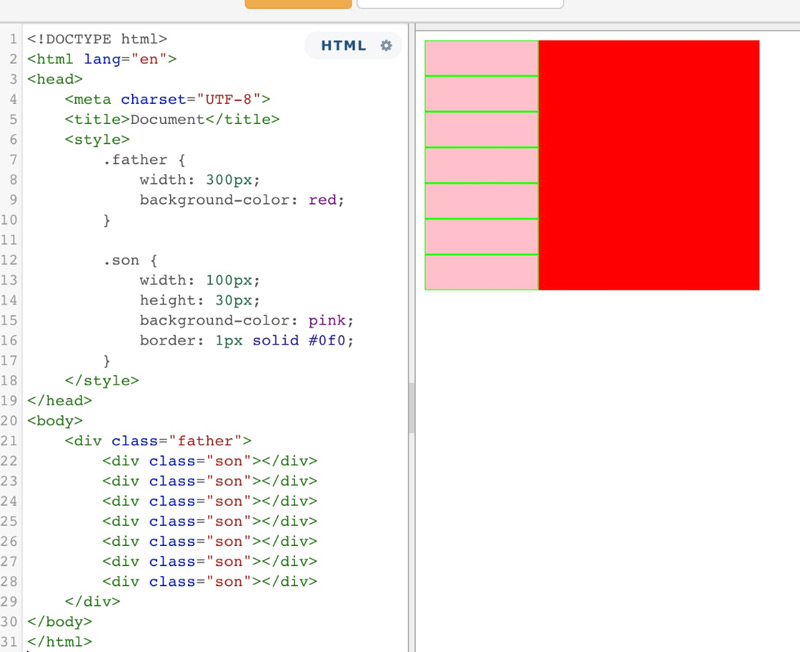
以上代码表示,一个没有设置高度的父盒子,包含着七个子元素。如果此时,所有的子元素都浮动的话。
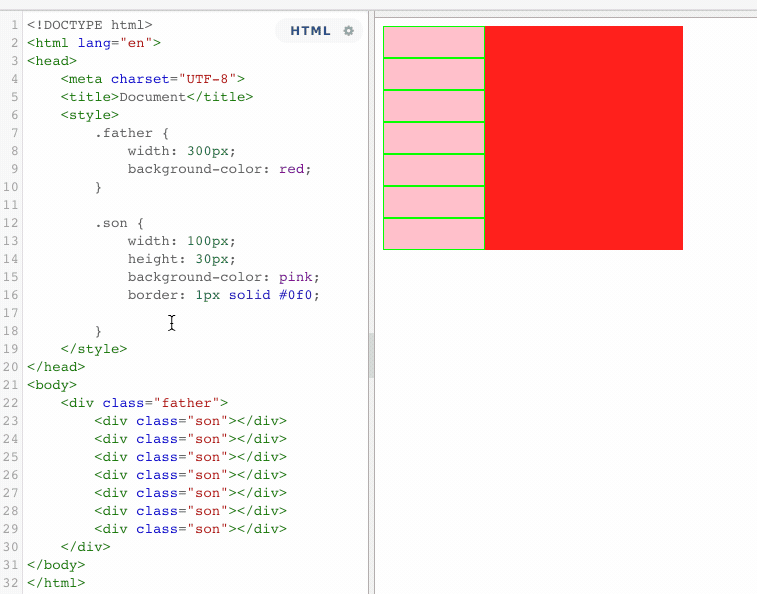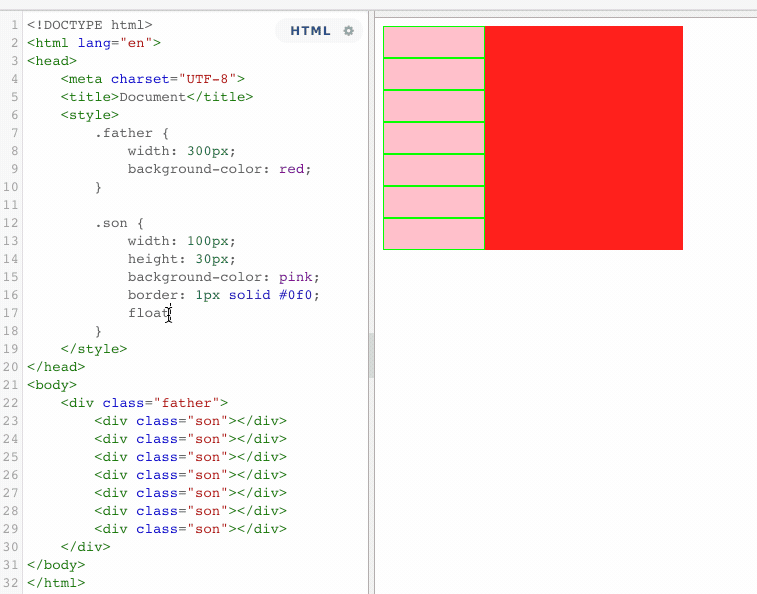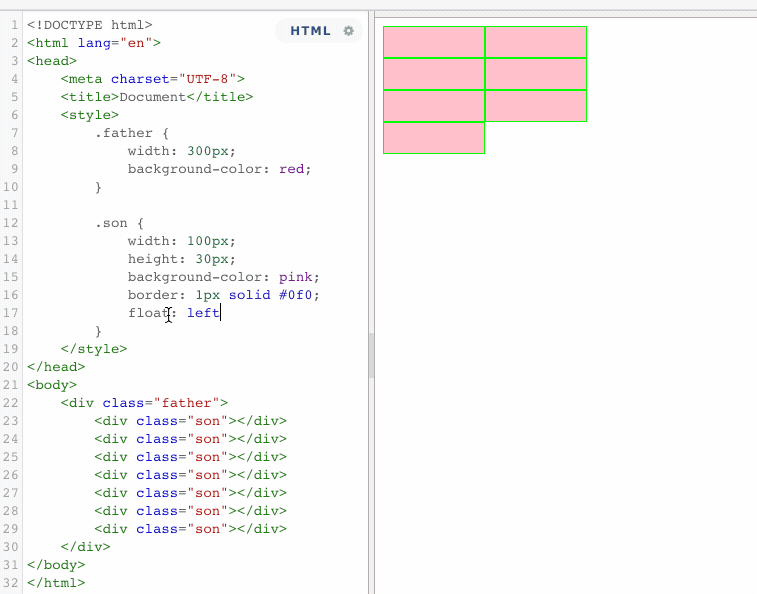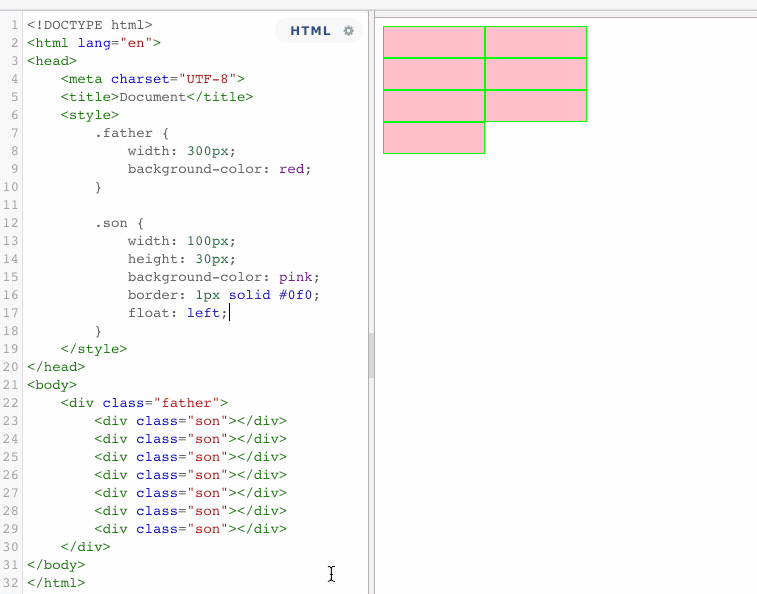
当所有的子元素都浮动了,这个时候,父盒子失去了原有的高度,这就是浮动的影响。这个时候,同样也可用BFC的机制,来清除浮动带来的影响。使用BFC,将所有的浮动元素包裹起来。

4.4 BFC可以阻止标准流元素被浮动元素覆盖
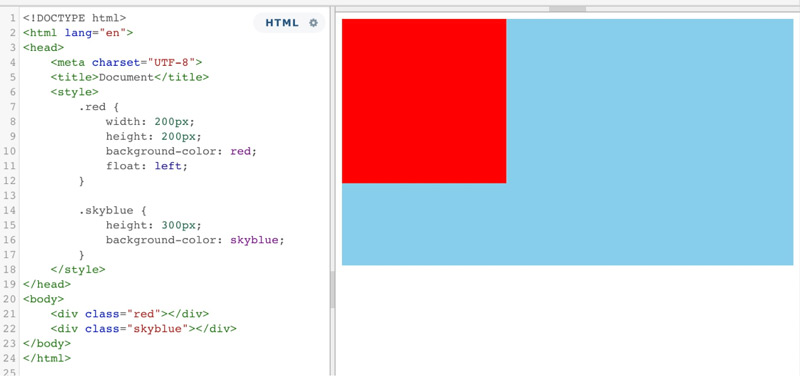
以上情况,红色盒子浮动,蓝色盒子时标准流,默认情况下,浮动元素覆盖了标准流元素。但是,如果将蓝色盒子的BFC触发,那么情况将有所变化。
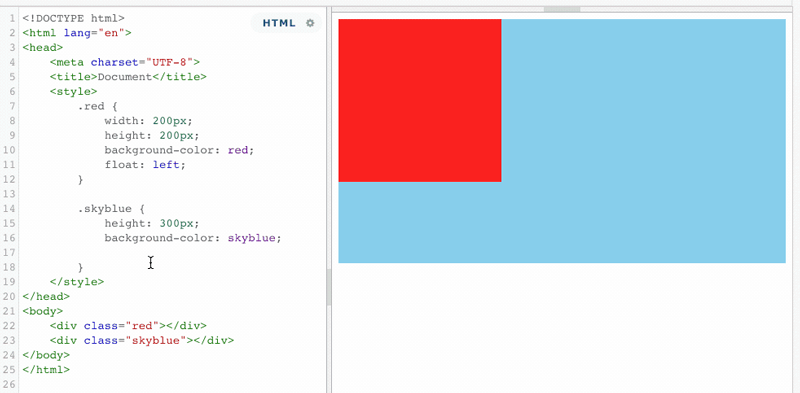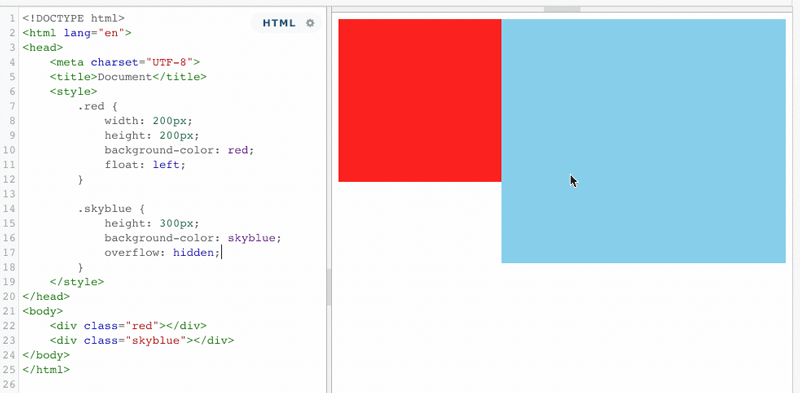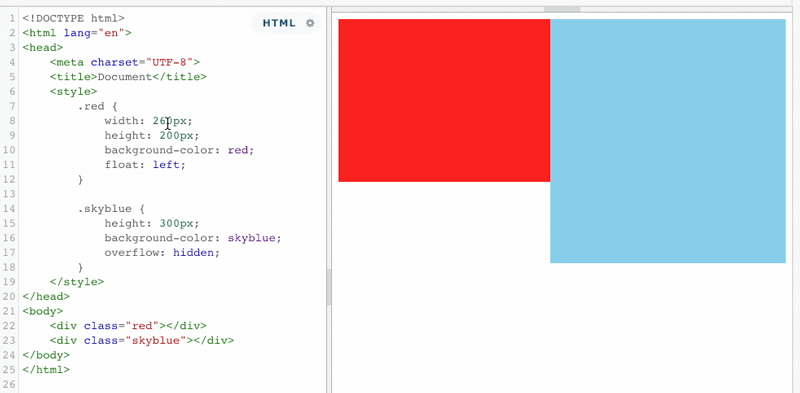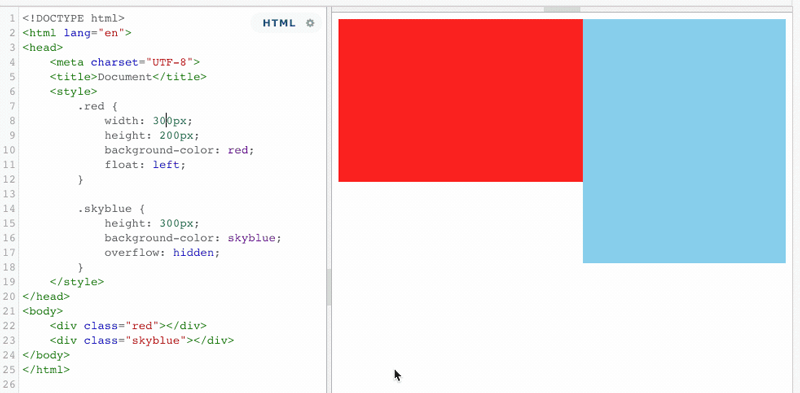
当蓝色盒子触发了BFC之后,浮动元素再也不能覆盖它了,而且还能利用这个特性,来实现蓝色盒子宽度根据红色盒子的宽度来做自动适应
5.总结
一个BFC区域只包含其子元素,不包括其子元素的子元素。
并不是所有的元素都能成为一块BFC区域,只有当这个元素满足条件的时候才会成为一块BFC区域。
不同的BFC区域之间是相互独立的,互不影响的。利用这个特性我们可以让不同BFC区域之间的布局不产生影响。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









