




上篇文章向大家简单介绍了Hadoop,这篇文章向大家详细介绍Hadoop环境搭建,大家可以跟随这篇教程完成Hadoop的环境搭建。
Hadoop是大数据处理框架,有三种安装模式。
1)本地模式:使用本地文件系统,而不是HDFS,只能测试MapReduce程序。
2)伪分布式模型:具备Hadoop的所有功能,在单机上模拟一个分布式的环境。
3)全分布式模式:真实的分布式环境。
由于条件的限制,小编只能带大家了解本地模式和伪分布式模型的搭建。所有安装模式在搭建过程中有一些共同的准备工作,如Linux系统安装和JAVA环境配置,所以我们先来做准备工作。
Linux系统安装和JAVA环境配置。
大部分人应该都是使用window系统,然而Hadoop是运行在Linux系统上的,所以我们必须安装Linux系统。大家可以使用虚拟机来创建一个Linux系统,如果是学生的话,我建议在阿里云服务器上购买一个学生机,每月只要9.9元,学生机的操作系统为Centos7版本。有了Linux系统之后,就要配置JAVA环境了,因为Hadoop是基于JAVA语言开发的。
先下载jdk1.7版本的压缩包,上传到Linux系统文件目录中,小编使用的文件目录为 /usr/local。上传之后如下图所示。
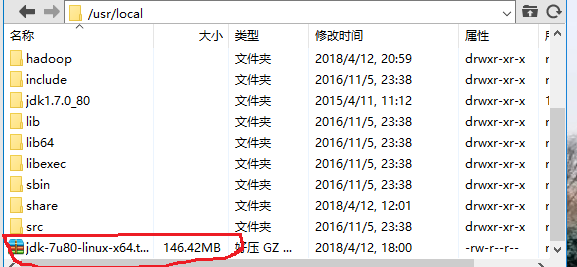
接下来在 /usr/local 目录下用tar命令解压缩。
tar -zxvf jdk-7u80-linux-x64.tar.gz 接下来配置环境变量。用vi /etc/profile 来编辑profile文件,在文件最后加入如下图的两句。
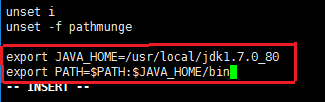
接着执行 source /etc/profile 命令来重新加载profile文件,最后执行 java -version 命令,如下图所示即表明JAVA环境配置成功。

JAVA环境配置好了之后就可以搭建Hadoop环境了。
本地模式搭建
先下载hadoop压缩包,并上传到Linux文件目录下,小编使用的文件目录为 /usr/local/hadoop。上传之后如下图所示。
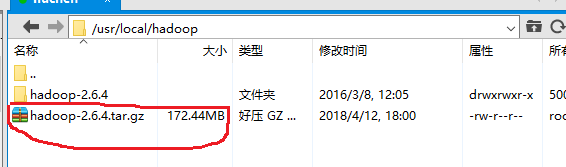
接下来在 /usr/local/hadoop 目录下用tar命令解压缩。
tar -zxvf hadoop-2.6.4.tar.gz解压之后设置环境变量。使用 vi ~/.bash_profile 命令来编辑 bash_profile 文件。在文件后加入下面的语句。
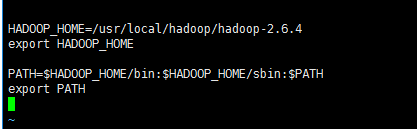
执行source ~/.bash_profile命令来重新加载bash_profile文件。要安装本地模式需要修改配置文件。在/usr/local/hadoop/hadoop-2.6.4/etc/hadoop目录下有一个hadoop-env.sh文件,修改其中的第25行为export JAVA_HOME=/usr/local/jdk1.7.0_80。这样Hadoop的本地模式就搭建好了。
前面已经提到本地模式主要是测试MapReduce程序,接下来我为大家演示一个Demo。Hadoop本身已经提供了许多MapReduce示例程序,位于/usr/local/hadoop/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar的jar包下。在/usr/local/hadoop/hadoop-2.6.4/share/hadoop/mapreduce目录下执行 hadoop jar hadoop-mapreduce-examples-2.6.4.jar 命令,可以查看该jar包下所有的示例程序。如下图所示。
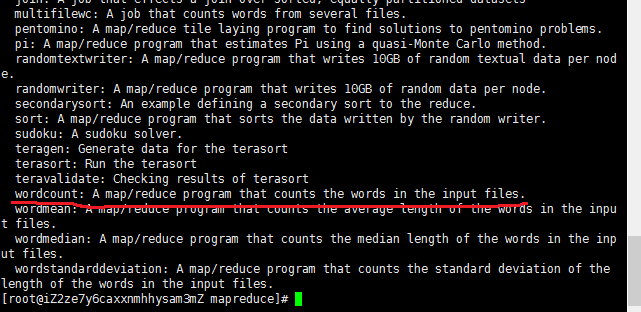
我们就用其中的wordcount程序来演示。wordcount程序的功能是统计文件中每个单词的个数。
首先在/usr/local/hadoop目录下创建两个文件夹,data/input 和 data/output 分别作为程序的输入和输出。在data/input文件夹下创建一个data.txt文件,文件内容如下图所示。
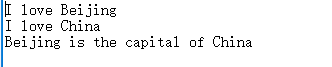
在 /usr/local/hadoop/hadoop-2.6.4/share/hadoop/mapreduce 目录下执行 hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount /usr/local/hadoop/data/input/data.txt /usr/local/hadoop/data/output/wc 命令。执行完之后再 /usr/local/hadoop/data/output/wc目录下出现两个文件,如下图所示。
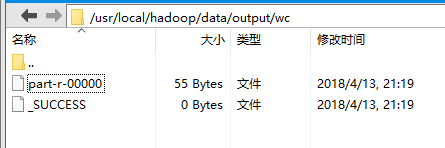
其中_SUCCESS表明程序执行成功,part_r_00000是程序执行保存的结果,用vi打开显示如下。
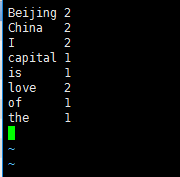
结果表明data.txt文件中有2个Beijing单词,2个China单词等。至此,Hadoop的本地模式搭建成功。
伪分布式模式搭建
本地模式是只修改了hadoop-env.sh文件,而伪分布式模式不仅要修改hadoop-env.sh文件,还要修改其他配置文件。需要修改的配置文件参数如下图所示。
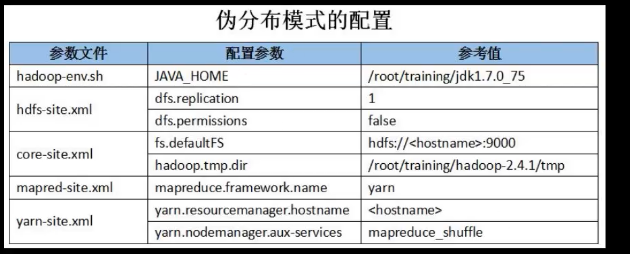
在配置文件参数之前我们先来设置ssh免密码登陆和IP主机映射。依次执行以下命令可设置ssh免密码登陆。
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys分别编辑/etc/hostname 和 /etc/hosts 来完成IP主机映射。如下图所示。


其中lc是主机名,大家可自行修改,172.17.240.15是Linux服务器的私网IP地址
下面我们就来配置文件参数。hadoop-env.sh文件的配置和本地模式一样,不再赘述。yarn-env.sh文件也和hadoop-env.sh文件一样只配置JAVA_HONE的地址就可以了。接下来首先配置hdfs-site.xml文件,该文件位于 /usr/local/hadoop/hadoop-2.6.4/etc/hadoop 目录下,用vi编辑,添加参数如下图所示。 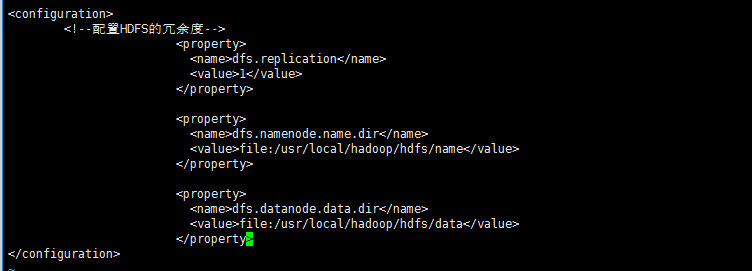
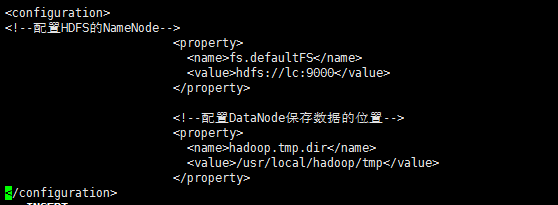
接下来先在 /usr/local/hadoop/ 目录下创建一个名为tem的新目录,然后配置core-site.xml文件,同样用vi编辑,添加参数如下图所示。
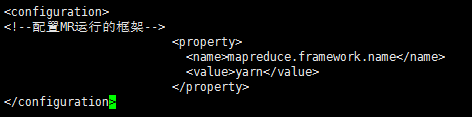
接下来配置 mapred-site.xml 文件,我们发现在 /usr/local/hadoop/hadoop-2.6.4/etc/hadoop 目录下没有此文件,但有个 mapred-site.xml.template 文件,我们复制一份此文件,并命名改为 mapred-site.xml ,然后vi编辑,添加参数如下图所示。
最后配置yarn-site.xml文件,添加参数如下图所示。
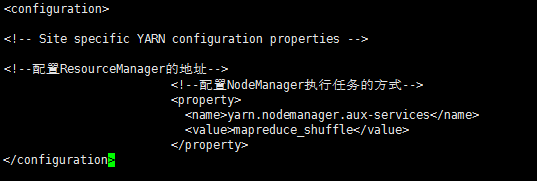
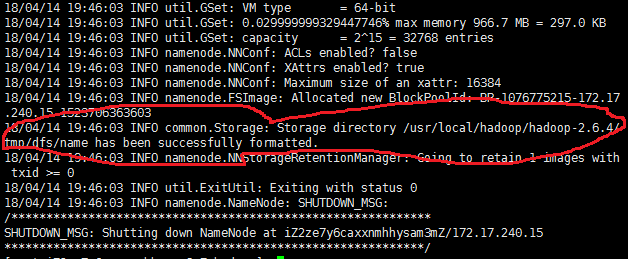
到此所有的配置文件都配置好了,但还不能启动Hadoop,我们还要格式化NameNode。在 /usr/local/hadoop/hadoop-2.6.4/bin 目录下执行 ./hdfs namenode -format 命令,当出现下面语句是表明NameNode成功格式化。
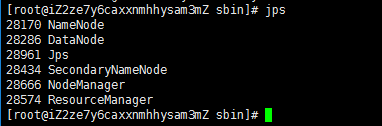
NameNode格式化成功之后就可以启动Hadoop了,执行 start-all.sh 命令来启动Hadoop,用jps命令查看所有Java进程,如下图所示。Hadoop有5个进程全部启动即表明搭建成功。
到此,我们介绍了Hadoop的本地模式和伪分布式模式搭建,大家有任何疑惑可在后台联系小编。
获取更多干货请关注微信公众号:追梦程序员。


















 44万+
44万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









