






 本文介绍了目标检测中的关键评价指标,包括mAP(平均精度均值)、IOU(交并比)、NMS(非极大抑制)及检测速度等,并详细解释了这些指标的计算方法和应用场景。
本文介绍了目标检测中的关键评价指标,包括mAP(平均精度均值)、IOU(交并比)、NMS(非极大抑制)及检测速度等,并详细解释了这些指标的计算方法和应用场景。
一、mAP
这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
P
代表precision即准确率, 计算公式为 预测样本中实际正样本数 / 所有的正样本数 即 precision=TP/(TP+FP);
R
代表recall 即召回率, 计算公式为 预测样本中实际正样本数 / 预测的样本数即 Recall=TP/(TP+FN)=TP/P
一般来说,precision和recall是鱼与熊掌的关系,往往召回率越高,准确率越低
AP
AP 即 Average Precision即平均精确度
mAP
mAP 即 Mean Average Precision即平均AP值,是对多个验证集个体求平均AP值,作为 object dection中衡量检测精度的指标。
P-R曲线
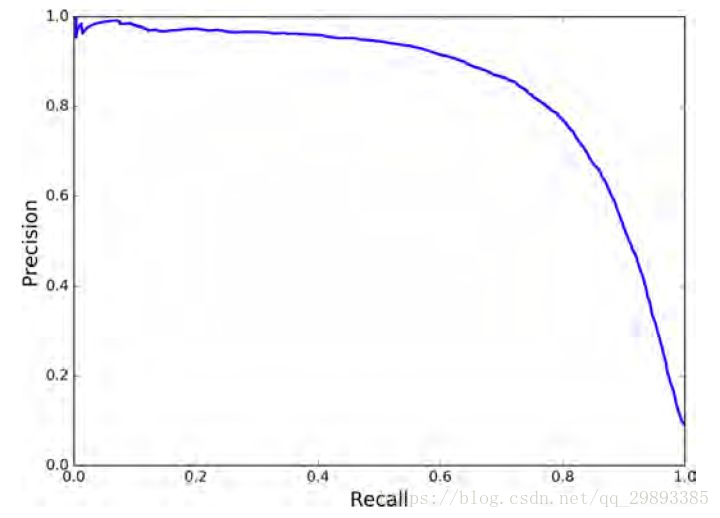
P-R曲线即 以 precision 和 recall 作为 纵、横轴坐标 的二维曲线。通过选取不同阈值时对应的精度和召回率画出
总体趋势,精度越高,召回越低,当召回达到1时,对应概率分数最低的正样本,这个时候正样本数量除以所有大于等于该阈值的样本数量就是最低的精度值。
另外,P-R曲线围起来的面积就是AP值,通常来说一个越好的分类器,AP值越高
最后小小总结一下,在目标检测中,每一类都可以根据 recall 和 precision绘制P-R曲线,AP就是该曲线下的面积,mAP就是所有类AP的平均值。
二、IOU(交并比)
IOU 即交并比 即 Intersection-over-Union,是目标检测中使用的一个概念,是一种测量在特定数据集中检测相应物体准确度的一个标准。
IOU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。

计算公式如下:
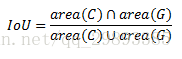
三、NMS(非极大抑制)
NMS即non maximum suppression即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
在物体检测中,NMS 应用十分广泛,其目的是为了清除多余的框,找到最佳的物体检测的位置。
四、速度
除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。当然要对比FPS,你需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。
参考博客:


















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









