




 本文介绍使用Python爬取壁纸网站https://tu.enterdesk.com/的方法。按分类分别爬取,分析页面异步请求的URL规律。还发现缩略图与高清图地址仅目录不同,可直接从缩略图地址获取高清图地址,最后给出了完整代码。
本文介绍使用Python爬取壁纸网站https://tu.enterdesk.com/的方法。按分类分别爬取,分析页面异步请求的URL规律。还发现缩略图与高清图地址仅目录不同,可直接从缩略图地址获取高清图地址,最后给出了完整代码。
今天我们爬取另一个壁纸网站https://tu.enterdesk.com/
进入首页后:
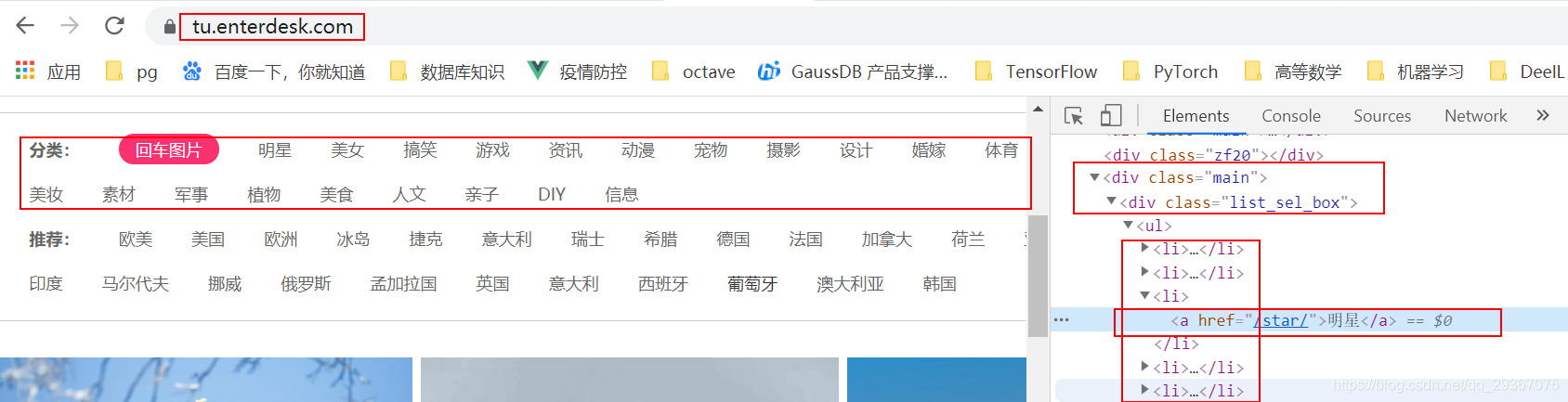
可以发现有很多的分类,我们直接按照分类来分别爬取。
比如点击一个分类【美女】。https://tu.enterdesk.com/meinv/
会有很多的照片条目。然后不断往下翻的时候也是不断在刷新更新,经观察network的XHR会发现,每一次的异步请求都是一个html页面哈。分析url如下:
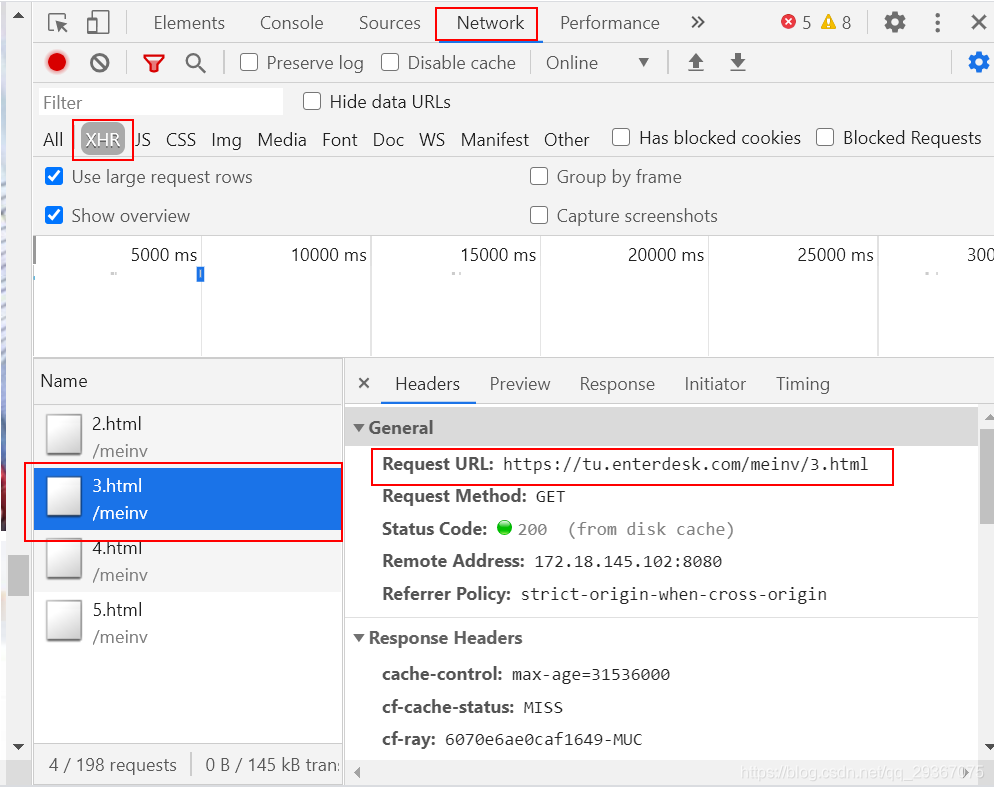
https://tu.enterdesk.com/meinv/
https://tu.enterdesk.com/meinv/2.html
https://tu.enterdesk.com/meinv/3.html
https://tu.enterdesk.com/meinv/4.html
………
所以https://tu.enterdesk.com/meinv/ 也等于https://tu.enterdesk.com/meinv/1.html
接着来看看图片,这里肯定显示的是缩略图。这里的图片条目点击进去不是组图,而是单张图片。
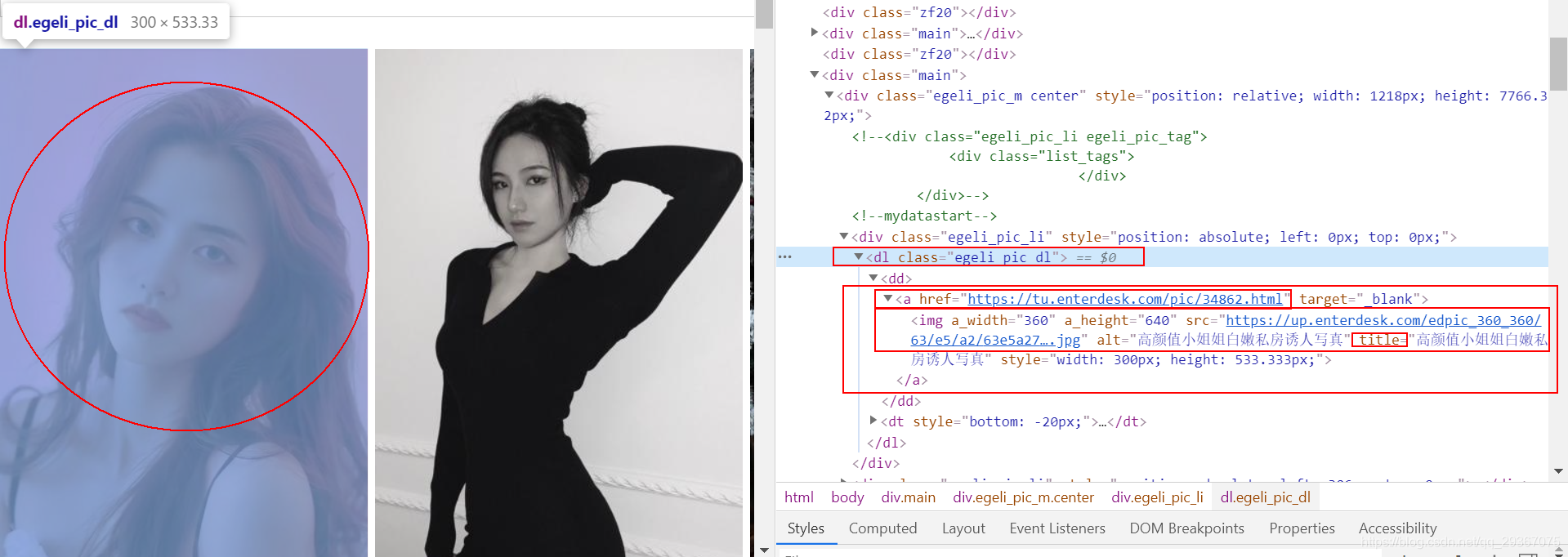
我们点击一张图片进去后发现,高清的原图如下:
我们看这个img的地址有点熟悉,对比下缩略图的高清图的地址:
缩略图:
https://up.enterdesk.com/edpic_360_360/63/e5/a2/63e5a27adfd808429e89e70ad55cdbbd.jpg
高清图:
https://up.enterdesk.com/edpic_source/63/e5/a2/63e5a27adfd808429e89e70ad55cdbbd.jpg
也就是一个目录的区别(edpic_360_360 和 edpic_source)
也就是说可以不用点击进去,直接从缩略图的地址就可以得到高清图的地址。
太简单了!
完整代码如下:
import time
from concurrent.futures import ThreadPoolExecutor
import time
import os
import re
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
rootrurl = 'https://tu.enterdesk.com'
save_dir = 'D:/estimages/'
MAX_PAGES = 100
headers = {
"Referer": rootrurl,
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
} ###设置请求的头部,伪装成浏览器
def saveOneImg(dir, img_url, title):
new_headers = {
"Referer": img_url,
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
} ###设置请求的头部,伪装成浏览器,实时换成新的 header 是为了防止403 http code问题,防止反盗链,
try:
img = requests.get(img_url, headers=new_headers) # 请求图片的实际URL
if (str(img).find('200') > 1):
with open(
'{}/{}.{}'.format(dir, title, img_url.split('.')[-1]), 'wb') as jpg: # 请求图片并写进去到本地文件
jpg.write(img.content)
print(img_url)
jpg.close()
return True
else:
return False
except Exception as e:
print('exception occurs: ' + img_url)
print(e)
return False
def getSubTitleName(str):
cop = re.compile("[^\u4e00-\u9fa5^a-z^A-Z^0-9]") # 匹配不是中文、大小写、数字的其他字符
string1 = cop.sub('', str) # 将string1中匹配到的字符替换成空字符
return string1
def processOnePage(dir, smallImgs):
for img in smallImgs:
src = img.get('src').replace('edpic_360_360', 'edpic_source')
title = img.get('title')
saveOneImg(dir, src, getSubTitleName(title))
pass
def oneSpider(tag, url):
if not os.path.exists(tag):
os.makedirs(tag)
for i in range(1, (MAX_PAGES + 1)):
suburl = '{}{}.html'.format(url, i)
html = BeautifulSoup(requests.get(suburl, headers=headers).text, features="html.parser")
smallImgs = html.find('div', {'class': 'egeli_pic_m center'}).find_all('img')
processOnePage(tag, smallImgs)
pass
def getTagList():
taglist = {}
html = BeautifulSoup(requests.get(rootrurl, headers=headers).text, features="html.parser")
a_s = html.find('div', {'class': 'list_sel_box'}).find('ul').find_all('a')[1:]
for a in a_s:
taglist['{}{}/'.format(save_dir, a.get_text())] = '{}{}'.format(rootrurl, a.get('href'))
return taglist
if __name__ == '__main__':
tagList = getTagList()
print(tagList)
# 给每个标签配备一个线程
with ThreadPoolExecutor(max_workers=30) as t: # 创建一个最大容纳数量为20的线程池
for tag, url in tagList.items():
t.submit(oneSpider, tag, url)
# just for test
# oneSpider('D:/estimages/美女/', 'https://tu.enterdesk.com/meinv/')
# 等待所有线程都完成。
while 1:
print('-------------------')
time.sleep(1)
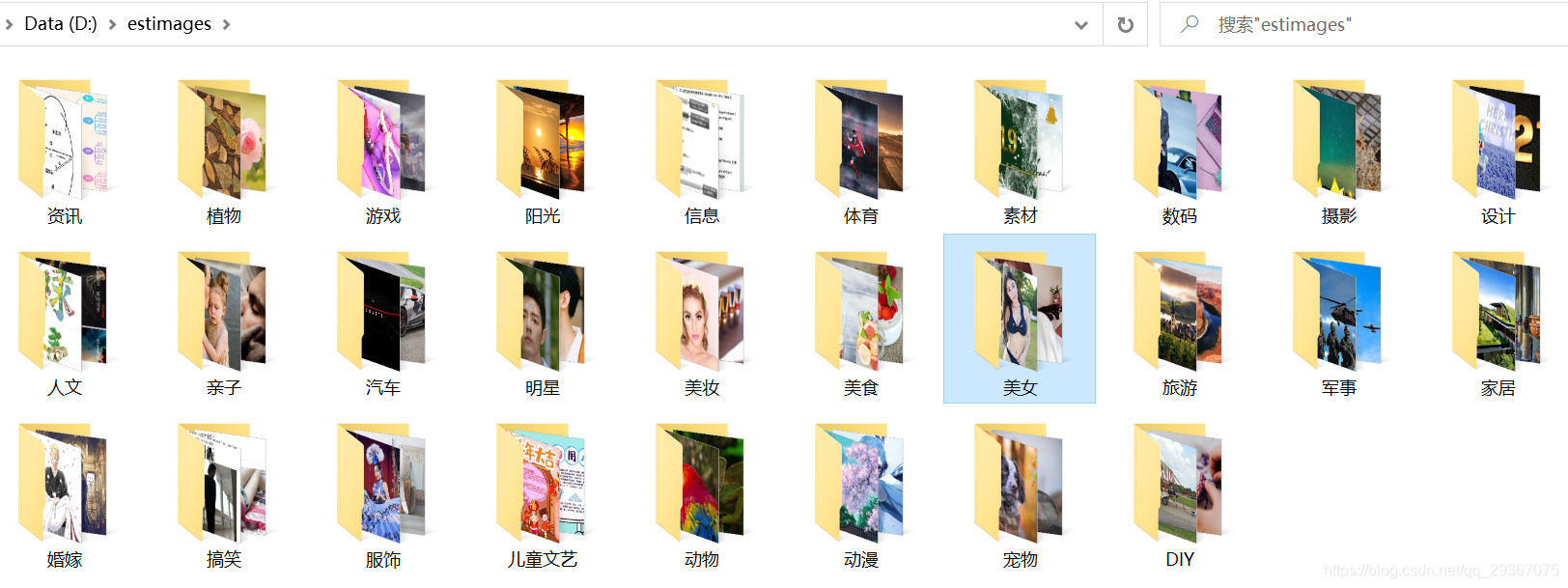
效果如下:

















 5910
5910




 到【灌水乐园】发言
到【灌水乐园】发言







