 微博数据抓取与解析
微博数据抓取与解析





 本文介绍了如何使用Python抓取并解析新浪微博中的数据,重点分析了Ajax请求与响应,展示了如何提取微博内容、点赞数、评论数等关键信息。
本文介绍了如何使用Python抓取并解析新浪微博中的数据,重点分析了Ajax请求与响应,展示了如何提取微博内容、点赞数、评论数等关键信息。
新浪微博中的数据采用Ajax加载进行显示,ajax加载即由JavaScript向服务器发送了一个请求来获取新的微博数据,并将其解析,最终将其渲染在网页中。
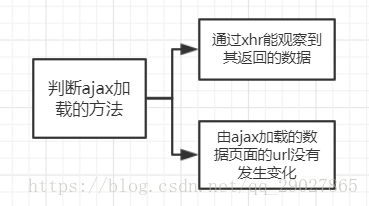
ajax的分析方法:
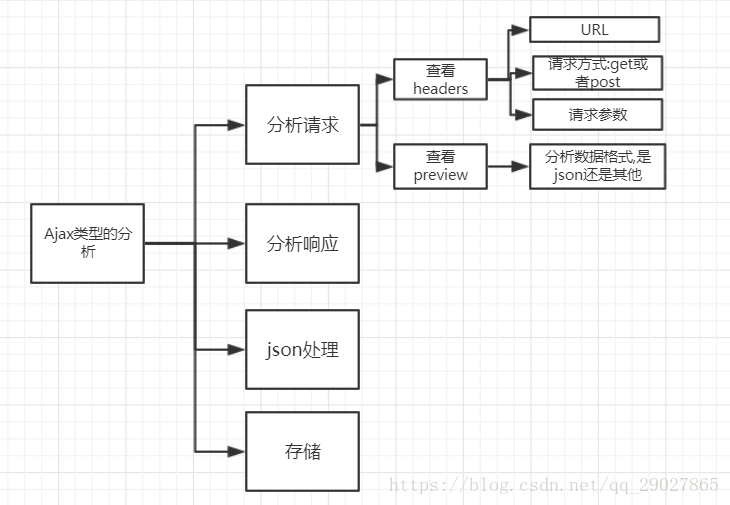
一.分析请求
对于考研张宇老师的微博数据来说,一般情况下,首先通过chrom浏览器的开发者工具将页面切换至手机页面的方式,查看network中的xhr请求,可以观察到request headers,response headers,url,请求参数params等信息,其中Request Headers中有一个信息为X-Requested-With:XMLHttpRequest,这标记着此请求为Ajax请求,通过查看其preview,可以得到其响应的内容为json格式的数据;
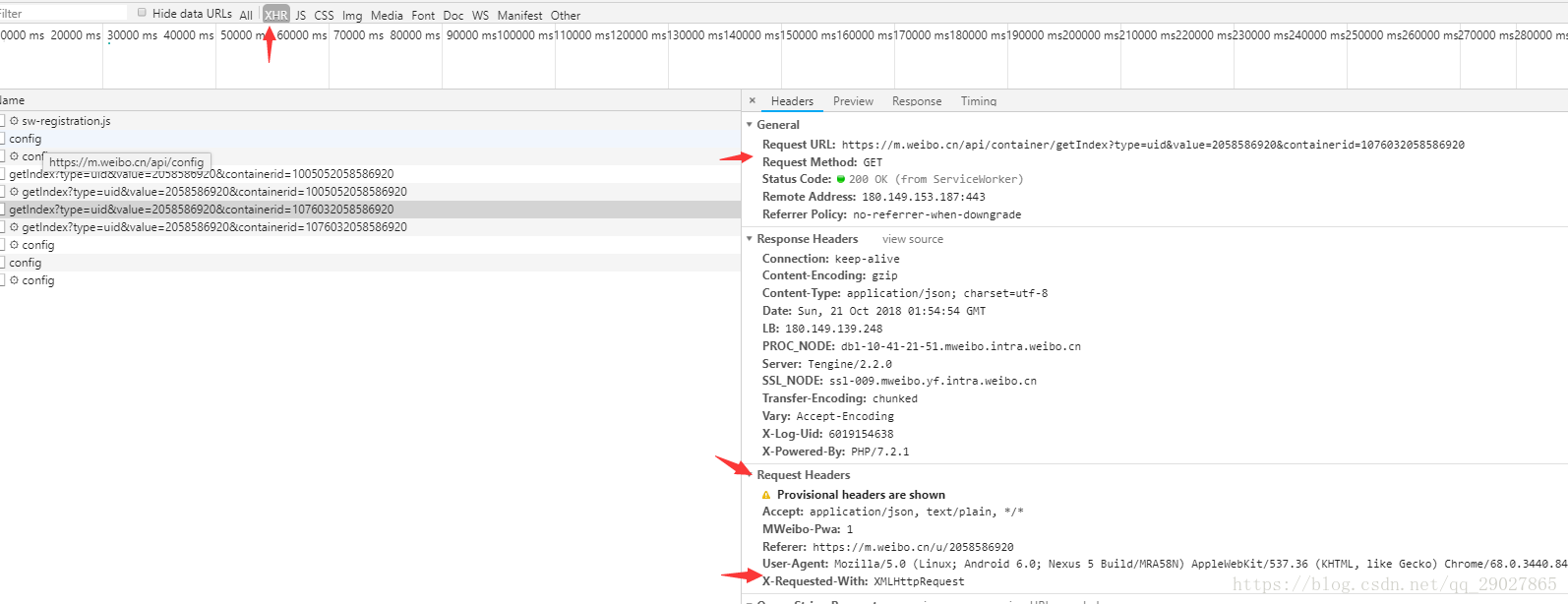
可以看出,这是一个get类型的请求,请求链接为:https://m.weibo.cn/api/container/getIndex?type=uid&value=2058586920&containerid=1076032058586920,请求参数目前有三个:type,value,containerid;
下拉翻页时,发现url会多加一个since_id的参数,但这个参数变化的没有找到规律,通过谷歌搜索发现也可以在其中加上page参数来进行对应微博的改变。于是最后的请求参数为:type,value,containerid,page;
二.分析响应
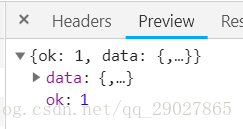
通过查看preview参数,可以得出其内容保存为json格式,可以观察到其最关键的两部分信息是:cardlistInfo和cards,而其中在mblog的字段中,其中有着包含着微博内容的信息,包括:atttitudes_count(点赞数目),comments_count(评论数目),reposts_count(转发书模),created_at(发布时间),text(微博正文)
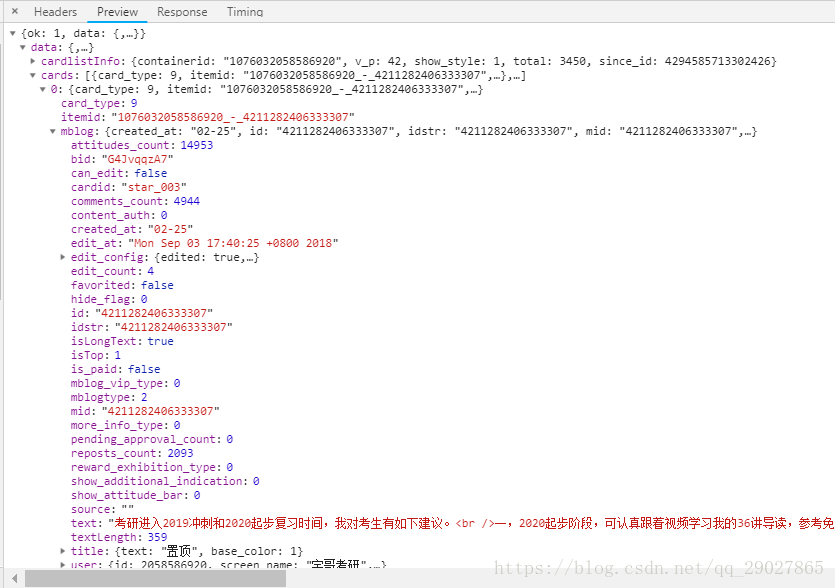
三.json处理
通过调用请求响应的response的json方法来将内容解析至JSON返回,这里通过格式化json的工具来对其json字典的内容进行查看:
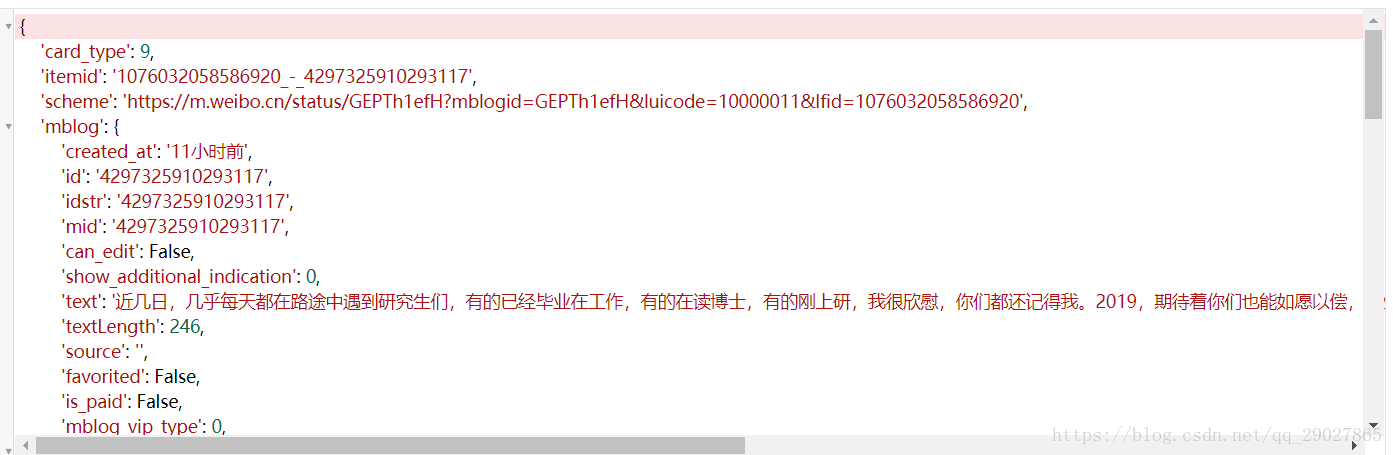
在对字典形式的内容进行提取时,因为不排除中间的一些参数没有而返回为None,故使用get的方法来获取value值,当键不存在时通过get方法能够返回默认值,(返回None或者用户定义的默认值);
根据获取到的text值中,其中带有html的标签,故我们可以借助pyquery将正文中的html标签去掉;
四.保存为json文件
保存json出现AttributeError: 'dict' object has no attribute 'dumps'错误,原因正在探究...
最终代码如下:
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
import json
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2058586920',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Mobile Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
max_page = 5
def get_page(page):
params = {
'type': 'uid',
'value': '2058586920',
'containerid': '1076032058586920',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
if item != None:
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
def save_to_json(result):
for i in result:
with open('data.json', 'w') as f:
f.write(json.dumps(i))
if __name__ == '__main__':
for page in range(1, max_page + 1):
json = get_page(page)
results = parse_page(json)
results = list(results)
print(results)
# save_to_json(results)


















 7407
7407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











