







1.准备工作:
linux:spark2.2.1+scala2.11.12+java1.8+python3.6
windows:spark2.2.1+scala2.12.4+java1.8+python3.6
由于这些版本都是对应的,python,jdk,scala这三个都要安装,一个都不能少,所以我们需要配套安装。anaconda和jdk很好下载,我就不放百度云链接了,这里只有scala和spark(linux和windows都有):
链接:https://pan.baidu.com/s/1G-oapQdAOEK_kkH86QD_dw 密码:c4pu
我写神经网络是在spark上用python写的,所以要装python(anaconda),而spark使用scala写的,scala需要java支持,这就是为什么要装这么多的原因。我也不知道我解释清楚没.....
2.1安装(windows):
anaconda,java还有scala的安装网上一搜索大把都是,所以自行解决。记得路径还有环境变量。
这里先导入几个python包:分别是pyspark和py4j
pip install pyspark
pip install py4j
spark的安装(Windows):
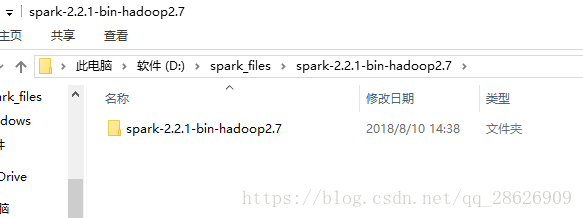
先解压,到目录:
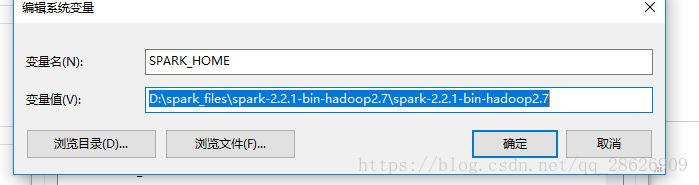
然后配置环境变量,和java他们很相似:
第一步:
第二步:(最后一行)
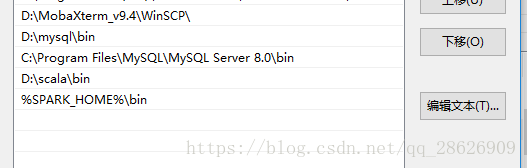
。到这里之后,spark就完了。我们测试一下:
dos下输入spark-shell(当出现下图时,就代表你ok啦)
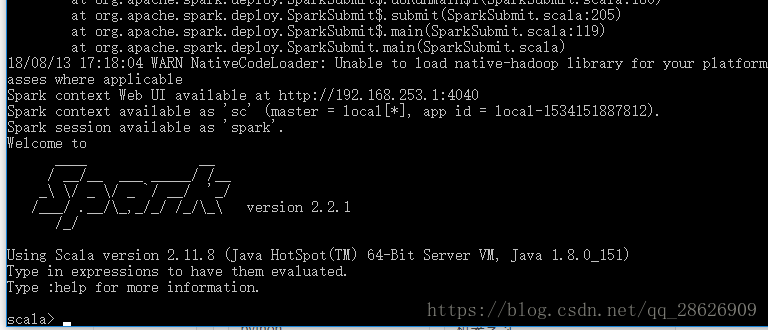
2.2安装(linux)
和2.1中的前提一样,安装好jdk,anaconda以及导入pyspark和py4j
解压到你的指定路径:

这里注意啊,我soft文件夹是所有权限都给了,以防权限问题
chmod 777 soft接下来配置环境变量:
在/etc目录下的 profile文件 ,我用的是
sudo nano /etc/profile我贴上我环境配置(注意自己的路径):
export PATH=$PATH:/usr/soft/nginx/nginx-1.8.0/sbin
#JAVA_HOME
export JAVA_HOME=/usr/soft/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#SCALA_HOME
export SCALA_HOME=/usr/soft/spark_files/scala-2.11.12
export PATH=$PATH:$JAVA_HOME/bin:${SCALA_HOME}/bin:$PATH
#SPARK HOME
export SPARK_HOME=/usr/soft/spark_files/spark-2.2.1-bin-hadoop2.7
#export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$FINGBUGS_HOME/bin:$HADOOP_HOME$
PATH=$PATH:${SPARK_HOME}/bin
#pythonpath
export PYTHONPATH=/usr/soft/spark_files/spark-2.2.1-bin-hadoop2.7/python
注意的spark_home和pythonpath。这两个都是给spark配置的,自己之前anaconda的不是这个。这个路径是spark里的
然后就可以测试了,命令行输入pyspark(python测试)或者spark-shell(scala测试)。等出现下图就ok了
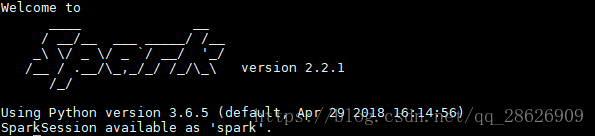
3.1代码测试(windows)
我自己用的是pycharm,我们先看配置
先新建一个自己的python测试文件,然后:
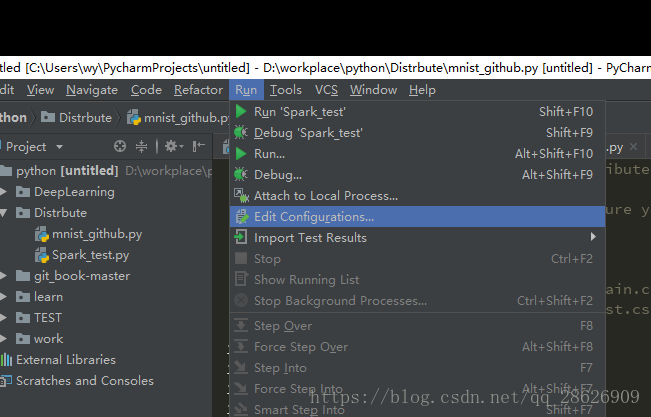
然后:(红色是自己新建的文件,代码我一会给,黄色是下图即将配置的路径)
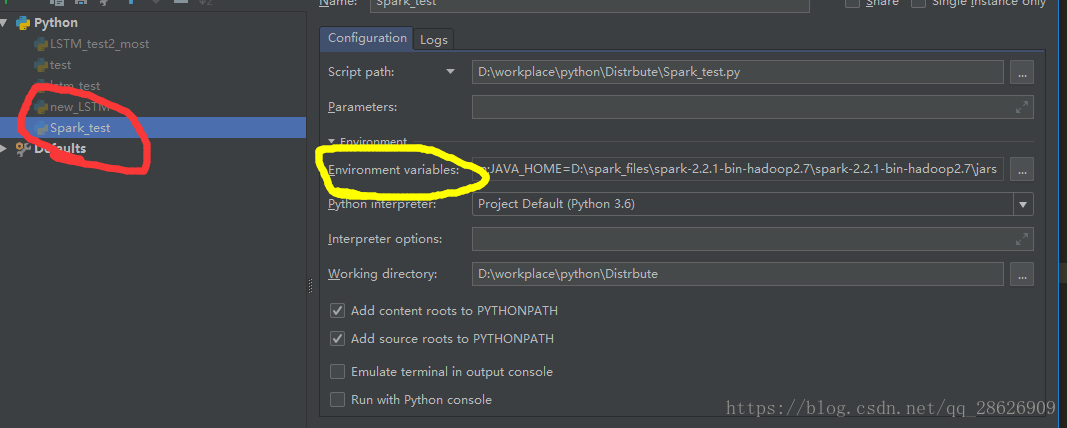
上图黄色内容(手动滑稽):
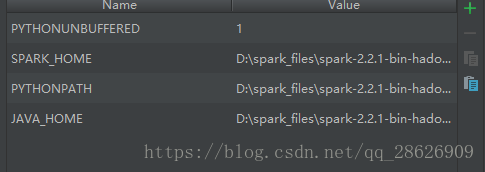
说明一下:spark路径,pythonpath,javahome都是在spark下的,而且变量名不能打错,比如,python_home就是不行的
如图:


,然后我给上测试代码:
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : Spark_test.py
# @Author: WangYe
# @Date : 2018/8/10
# @Software: PyCharm
# spark,伪分布式测试
import pymysql
import pyspark
import os
from pyspark import SparkConf, SparkContext
os.environ['JAVA_HOME']='D:\Java\jdk1.8'
conf = SparkConf().setMaster('local[*]').setAppName('word_count')
sc = SparkContext(conf=conf)
d = ['a b c d', 'b c d e', 'c d e f']
d_rdd = sc.parallelize(d)
rdd_res = d_rdd.flatMap(lambda x: x.split(' ')).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
print(rdd_res)
print(rdd_res.collect())运行结果:

3.2代码测试(linux)
我linux是centos的,在测试代码路径下直接
python spark_test.py
就可以啦
代码:
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : test.py
# @Author: WangYe
# @Date : 2018/8/13
# @Software: PyCharm
from pyspark import SparkConf,SparkContext
conf=SparkConf().setMaster('local').setAppName('word_count')
sc = SparkContext(conf=conf)
d = ['a b c d', 'b c d e', 'c d e f']
d_rdd = sc.parallelize(d)
rdd_res = d_rdd.flatMap(lambda x: x.split(' ')).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)
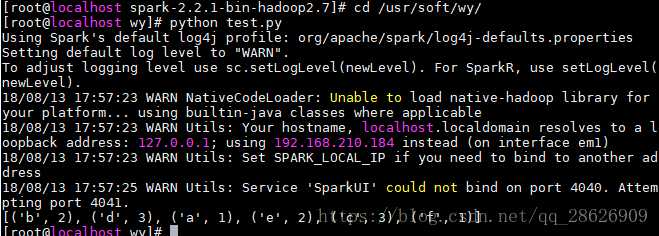
print(rdd_res.collect())
运行截图:
4.错误总结:
很多人在运行的时候会提示java端口号的问题,各种百度google没解决,然后我总结了一下。请大家在我的另一个博客中看看解决方案:(错误贴图) 链接问题地址
raise Exception("Java gateway process exited before sending the driver its port number")
Exception: Java gateway process exited before sending the driver its port number

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









