




一、Job数据存储
Quartz中,相关的Job、Trigger和Scheduler必须先被存储起来之后才可以使用,Quartz提供了两种存储机制,分别是RAMJobStore(内存存储)和JDBCJobStore(持久化存储)
1.RAMJobStore(内存存储)
Quartz中默认使用RAMJobStore存储机制,RAMJobStore将相关的Job、Trigger和Scheduler存储到内存中,读写速度快、效率高,但也因此存在致命缺点,当运行的系统被停止后所有的数据将会丢失,因此如果需要进行集群必须要使用JDBCJobStore存储机制。
另外需要注意的是,如果在给StdSchedulerFactory工厂进行配置没有使用quartz.properties配置文件,Quartz会序默认使用RAMJobStore存储机制,但如果使用了quartz.properties配置文件则需要在文件中配置清楚,具体配置如下
#============================================================================
# Configure Main Scheduler Properties
#============================================================================
org.quartz.scheduler.instanceName = TestScheduler
org.quartz.scheduler.instanceId = AUTO
#============================================================================
# Configure ThreadPool
#============================================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 3
org.quartz.threadPool.threadPriority = 5
#============================================================================
# Configure JobStore
#============================================================================
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore2.JDBCJobStore(持久化存储)
JDBCJobStore将相关的Job、Trigger和Scheduler等通过JDBC存储到数据库中,需要进行比较复杂的配置(基本属性配置、数据库的创建),且效率比RAMJobStore低,但是弥补了RAMJobStore存储机制的致命缺点,可以将Quartz的运行信息持久化,确保运行数据的安全。而且,利用JDBCJobStore可以使多个节点共用一个数据来实现集群。
- quartz.properties
#==============================================================
#Configure Main Scheduler Properties
#==============================================================
org.quartz.scheduler.instanceName = quartzScheduler
org.quartz.scheduler.instanceId = AUTO
#==============================================================
#Configure JobStore
#==============================================================
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.isClustered = true
org.quartz.jobStore.clusterCheckinInterval = 10000
org.quartz.jobStore.dataSource = myDS
#==============================================================
#Configure DataSource
#==============================================================
org.quartz.dataSource.myDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://127.0.0.1:3306/quartz?useUnicode=true&characterEncoding=UTF-8
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = root
org.quartz.dataSource.myDS.maxConnections = 30
#==============================================================
#Configure ThreadPool
#==============================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true- 数据库
1.X和2.x的数据库的建表脚本不一样,在第七章中有2.x的数据库建表脚本,共有11章表,这里学习一下这11章表各自的用途
| 表名 | 说明 |
|---|---|
| QRTZ_SCHEDULER_STATE | 存放调度器状态 |
| QRTZ_TRIGGERS | 触发器的基本信息 |
| QRTZ_SIMPLE_TRIGGERS | 简单触发器的信息 |
| QRTZ_CRON_TRIGGERS | 存放cron类型的触发器信息 |
| QRTZ_BLOB_TRIGGERS | 以Blob 类型存储的触发器信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的触发器的状态信息,以及相联任务的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存放暂停掉的触发器的信息 |
| QRTZ_SIMPROP_TRIGGERS | |
| QRTZ_JOB_DETAILS | 存放每一个已配置的Job详细信息 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息(如有使用) |
| QRTZ_CALENDARS | 存放日历信息 |
二、集群原理
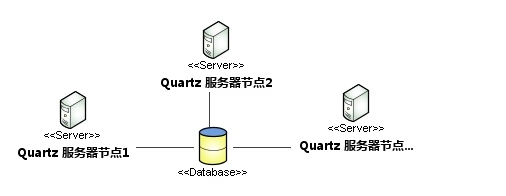
如图中所示,Quartz的集群架构中,每个节点都是一个单独的Quartz应用,他们相互之间并不通信,通过共用同一套数据库表来感知其他Quartz应用的变化。如果该任务正在执行,则其他应用不能调用该任务。
1.Quartz集群具有以下特点:
- 持久化:Quartz的集群必须使用JDBCJobStore存储机制,即将相关的数据都存储在数据库中,可以通过数据库中的信息进行恢复,确保了数据的安全性。
- 高可用性:多个节点通过数据库表来感知其他节点运行情况,一旦有节点挂掉了,其他节点则会继续执行相关任务。
- 易扩展性:随着项目需求的扩大,如果目前节点数不足导致任务无法即使触发 ,只需要将节点上的脚本及配置信息拷贝到新的服务器上进行部署就可以增加额外服务器节点来进行资源扩展。
- 负载均衡:Quartz使用随机的负载均衡算法,任务以随机的方式由不同的节点上Scheduler实例来执行。
2.Quartz集群的启动流程
在Quartz中,Scheduler是察觉不到被集群的,只有配置给Scheduler的JDBCJobStore才知道。当Scheduler启动时,它调用JobStore的schedulerStarted()方法来通知JobStore,Scheduler已经启动了。schedulerStarted()方法是在JobStoreSupport类中实现的。JobStoreSupport类会根据quartz.properties文件中的设置来确定Scheduler实例是否参与到集群中。假如配置了集群,一个新的ClusterManager类的实例就被创建、初始化并启动。
ClusterManager是在JobStoreSupport类中的一个内嵌类,继承了java.lang.Thread,它会定期运行,并对Scheduler实例执行检入的功能。Scheduler也要查看是否有任何一个别的集群节点失败了。检入操作执行周期在quartz.properties中配置。
3.集群实现
关于集群的实现整合在第四章《Quartz-集群实现中》

















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









