



DJango笔记
DJango的配置:
1,工程的建立:
使用django-admin startproject 工程名来自动的生成工程项目
2,app的建立
进入创建好的工程目录使用python manage.py startapp app名字
3,setting文件的配置
静态文件的配置:在settings末尾添加STATICFILES_DIR = ( 静态文件夹位置, ) ,同样的静态文件的URL可以通过修改STATIC_URL来修改静态文件的网络访问路径(css,js,image,video都是静态文件)

App的注册在创建完app后app并不能直接添加到项目中运行,而是需要在settings中的INSTALLED_APPS选项中添加App的相对路径才可以使用
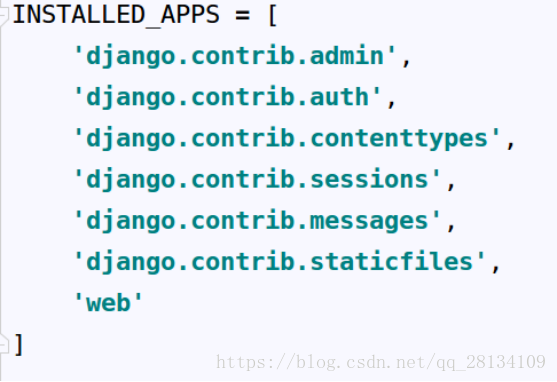
在上方添加app的相对路径
模板文件的配置:在settings的TEMPLATES中的DIRS选项中添加静态模板的文件夹位置
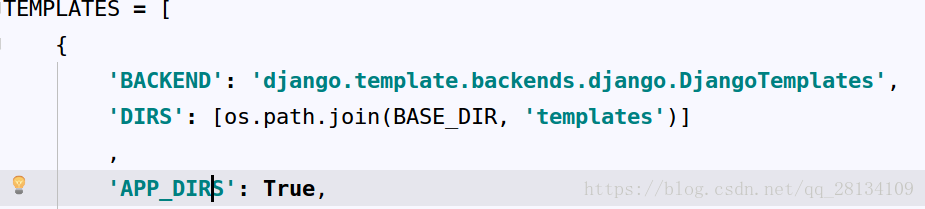
以上文件配置除了App的注册是相对路径,其他都是绝对路径,在settings文件中有BASE变量代表了项目的路径可以使用os.path.join()的方式来使用
配置admin页面中显示的语言与时间
将上方的LANGUAGE_CODE = ‘zh-hans’
TIME_ZONE = ‘Asia-Shanghai’
DJango的模型类
定义模型类:
定义普通的模型类
from django.db import models
class author(models.Model):
Id = models.AutoField(primary_key=True)
Author = models.CharFidld(max_length=30)
age = models.IntegerField()
以上代码定义了一个简单的模型类,定义完模型类之后需要生成迁移文件,后执行命令生成表
python manage.py makemigrations #生成迁移文件
在执行上方命令后会发现在App目录下生成了一个py文件,该py文件就是迁移文件,里面包含了表的结构详情如下
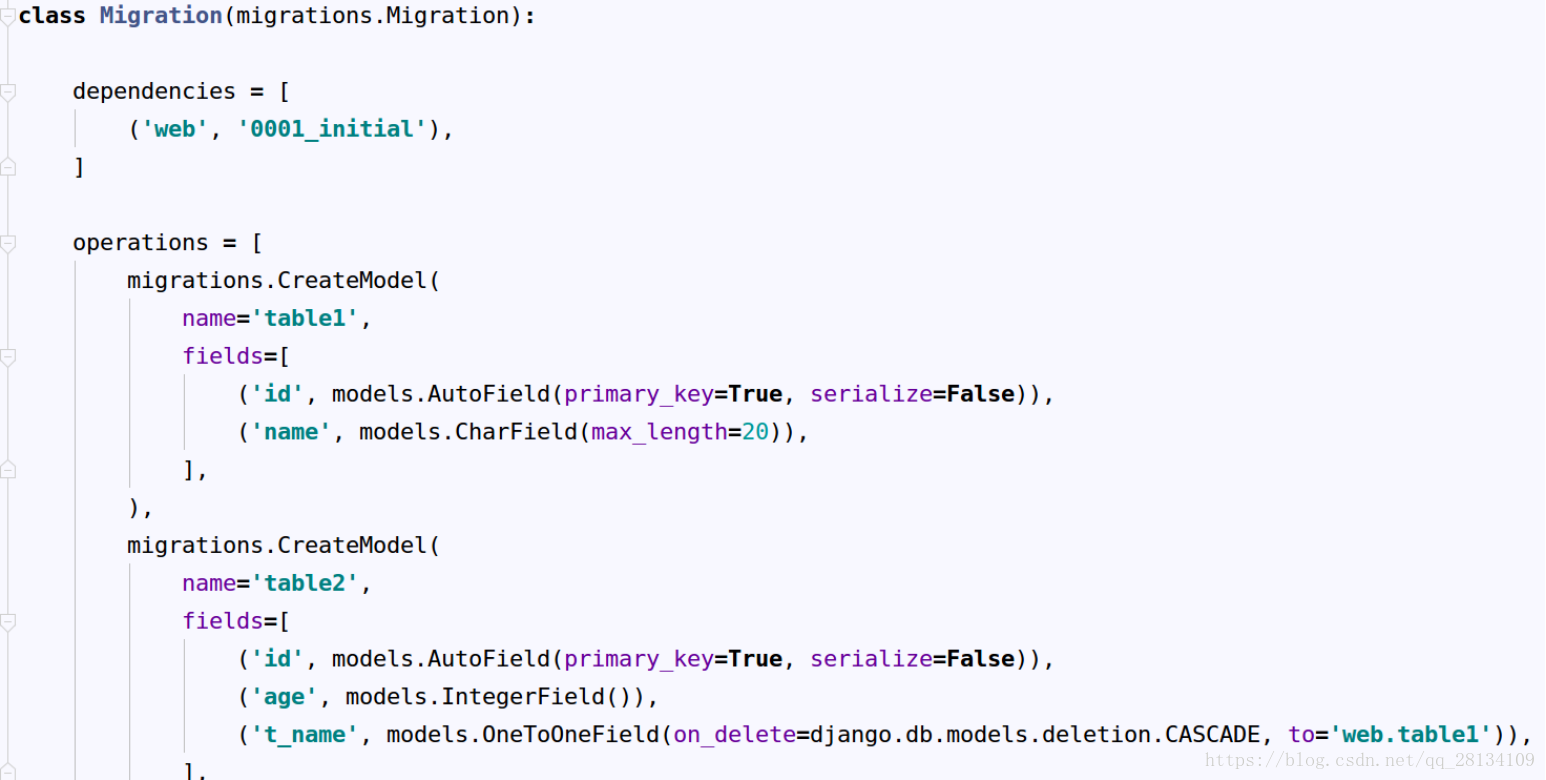
然后执行 python manage.py migrate来创建数据库中的表
Django默认使用的是sqlite3数据库,假设要将数据库改成mysql或其他数据库需要在DATABASES选项中配置数据的的类型以及连接参数,配置如下

Django的orm简单的操作:
增加一条记录:
author.objects.create(Author=’猫腻’)
同样的可以使用
Aut = author(AUthor=’猫腻’)
Aut.save()
查询记录:
author.objects.all() 查询全部记录
author.objects.get(id=1).Author #get方法查询的结果为Model对象可以直接通过字段名的方式直接查询值
autho.objects.filter(id__lt=1) #filter方法会返回一个queryset类型的对象。该对象并不能直接使用字段名的方式来获取值,可以通过values(),values_list()的方式来获取内部的值,values()返回的是列表嵌套字典,而values_list()返回的是列表嵌套元组,同样的values方法也可以进行分组操作,
filter中的参数详解:
__lt 小于 __gt 大于 __lte 小于等于 __gte 大于等于 __range() 相当于python中的in range() __in= 后面跟列表或者集合等序列类型,于python中的in相同
filter中可以使用Q对象来筛选记录使用方式入下
from django.models import Q
all = Q()
#实例化一个Q对象
all.connentor = ‘OR’
#指定条件之间的连接符号同样可以使用AND来连接
all.children.append(Q(id=4))
all.children.append(Q(id=5))
author.objects.filter(all)
同样的也可以直接实例化Q对象
author.objects.filter(Q(id=3) | Q(id =4))
|表示或 ,但是在Q对象中使用表示根据前面的结果过滤值
聚合操作
from django.db.models improt *
values(字段名).anotate(Count(字段名))
除了Count annotate同样的支持Max Min Sum 等聚合函数的操作
更新一条记录
author.objects.get(id=1).update(author=’金庸’)
update语句格式
模型类名.objects.get(‘条件’).update(字段名=‘值’)
当进行自加操作的时候需要使用F来获取当前表的值 比如我要将表中所有的作者年龄全部加2
from django.db.models import F
#F的导入
author.objects.all().update(F(‘age’)+1)
#F的使用通过F(‘字段名来获取当前表的名字’)
删除一条记录
author.objects.get(id=3).delete() #删除一条记录
一对一 OneToOneFileld()字段的使用及查询
from django.db.models import *
#导入工具/(ㄒoㄒ)/~~ 假设有两张表一张表为husband(丈夫) (妻子)wife
class Husband(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
wife_id = OneToOneField(to=’Wife’,to_fileld=’id’,ondelete=CASCADE)
class Wife(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
以上两张表的关系为一对一 即一个丈夫只能对应一个妻子,本质上的原理就是在wife_id 上加上了unique 与 not null
一对一的查询
Husband.objects.get(id=1).Wife.name 使用该方式来查询一对一的对应表的内容
同样的Wife表也可以使用该方式来查询
ForeignKey的使用与查询
class Husband(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
class Wife(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
husband = ForeignKey(to=’Husband’,to_fileld=’id’,ondelete=CASCADE)
同样是两张表这次Husband关练Wife表的多个内容
通过Husband查询Wife表(反向查询)
在django建表的时候会建立一个隐藏的字段,隐藏字段为 被关联表名小写_set
Husband.objects.get(id=1).wife_set.all()
由于一个丈夫可能被多个妻子所关联,所以返回结果将是一个queryset类型的查询结果,并不能直接获取字段值
Wife.objects.get(id=4).husband.name
通过Wife查询Husband 由于一个妻子只能关联一个丈夫所以返回结果为模型类对象 可以直接获取字段值
Foreignkey的字段的添加形式
- 通过对象来添加
hus = Husband.objects.get(id=3)
Wife.ojects.create(name=’xxx’,husband=hus)
2.直接通过字段值来添加
由于在建立表的时候指定了Husband的id 实际上在表中的字段 该外键的字段名早被改成husband_id
因此在修改添加记录的时候需要将关键字参数husband改为husband_id
Wife.ojects.create(name=’xxx’,husband_id=1)
MoneyToMoney字段的使用与查询
MoneyToMoney字段建立
同样的还是丈夫与妻子表
class Husband(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
class Wife(Model):
id = AutoField(primary_key=True)
name = CharField(max_length=30)
husband = MoneyToMoney(to=’Husband’,to_fileld=’id’,ondelete=CASCADE)
多对多添加关系的时候需要使用 对象.add() 的形式来添加关系如下实例
Wife.objects.get(id=3).husband.add()
Husband.objects.get(id=3).wife_set.add()
查询
Wife.objects.get(id=3).husband.all()
Husband.objects.get(id=3).wife_set.all()
更新
Wife.objects.get(id=3).husband.update()
Husband.objects.get(id=3).wife_set.update()
删除
Wife.objects.get(id=3).husband.all().delete()
Husband.objects.get(id=3).wife_set.all().delete()
删除关系
Wife.objects.get(id=3).husband.remove(关系)
Husband.objects.get(id=3).wife_set.remove(关系)
模型类的查询(sql语句)
1,使用extra()来查询
extra的介绍:

以上是extra的参数 同样的extra是属于queryset类的一个对象绑定方法因此当使用values与values_list 和 Model对象并不能调用
参数详解
select 参数:
select是向queryset中的对象添加一个新的查询的字段值
select参数是一个字典类型的参数,{‘重命名的字段名’:’sql语句’}实例如下
author.objects.all().extra(select={‘m’:’select count(id) from 表名字 where id= %s’},select_params=[3])
select_params同select一起使用,目的是将select中的sql语句中的占位符%s替换成相应的条件 但是select_params中的替代值并不能使用F 与 Q
where参数:
使用情况与Q大致相同。同样是数据过滤 该参数也是定义简单的筛选条件 同样的他也有一个占位符号的参数params = []
tables参数
tables参数是讲两张表联合查询并生成笛卡尔积形式的queryset,就是sql语句中的innerjoin 与 leftjoin rightjoin 以及 naturaljoin 自然连接一样重新生成一张虚拟表
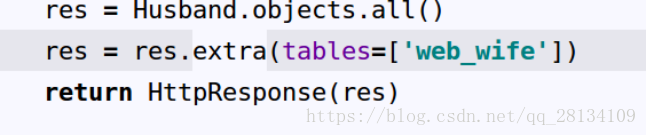
以上是orm操作
以下是网页返回内容
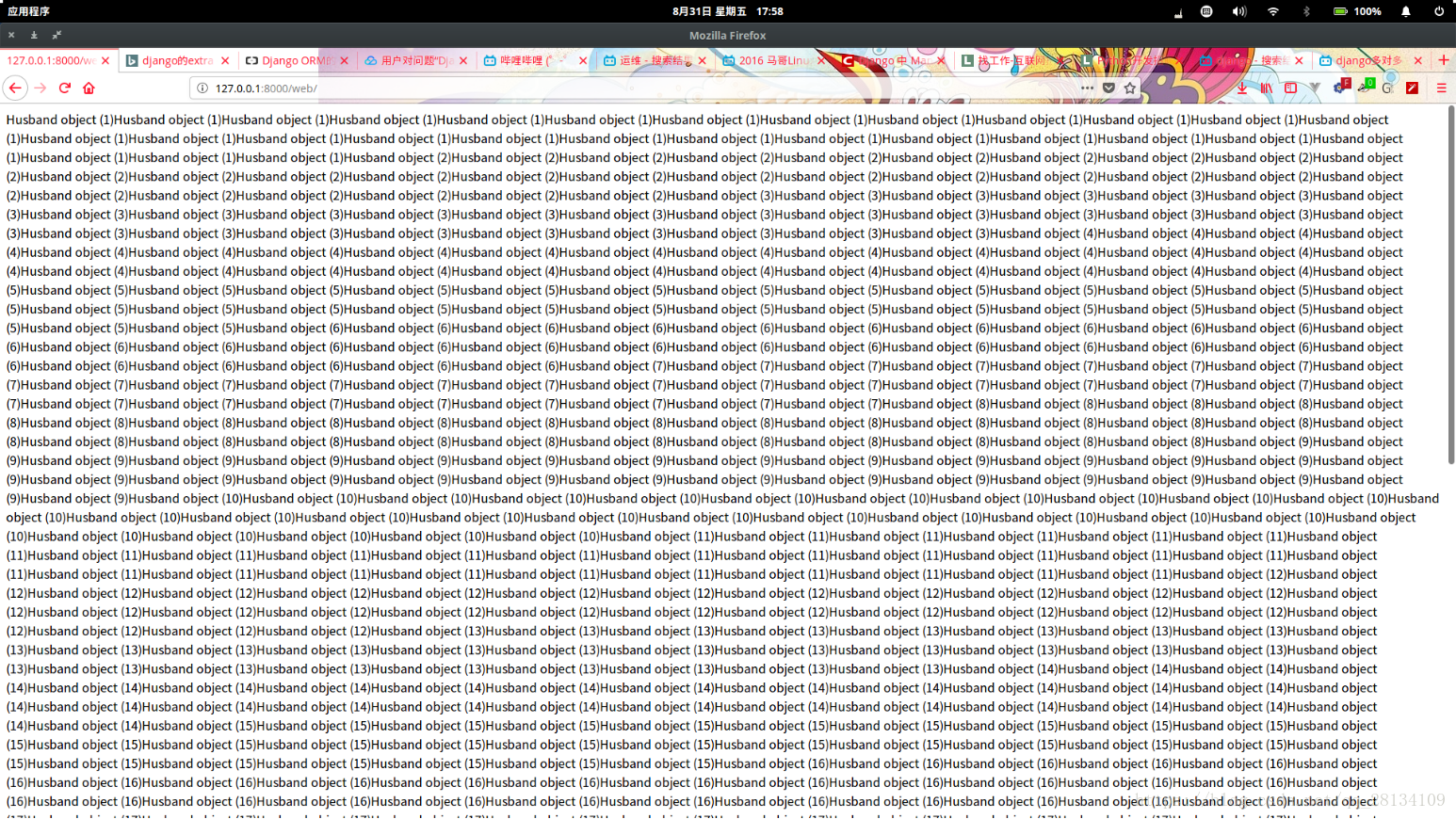
可以看出返回的是笛卡尔的queryset类型,内部且都是husband类型
使用query()方法来查看查询语句

发现查询语句并没有查询相关于web_wife的字段
因此使用tables完整的连表操作为
Husband.objects.all().extra(select={'wife_name':'web_wife.name'},tables=['web_wife'],where=['web_wife.id=web_husband.id'])
在进行完连表操作之后再进行筛选查询其他表的字段值才能查询到结果 结果如下
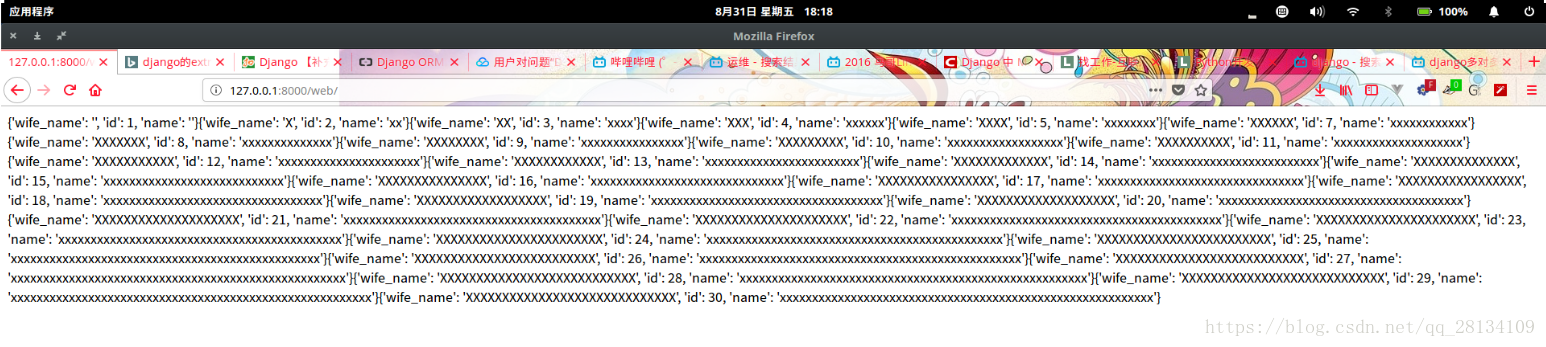
实际上extra的操作并不是真是的去写sql语句而是拼接sql语句
orm其他用法(以下都是拷贝与老师博客)
def all(self)
# 获取所有的数据对象
def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询,但是hi排除的,例如id=1,是除了id=1的其他的都要
# 条件可以是:参数,字典,Q
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related('外键字段')
model.tb.objects.all().select_related('外键字段__外键字段')
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type='Excused', then=1),
default=0,
output_field=models.IntegerField()
)))
def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct进行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
"""
def none(self):
# 空QuerySet对象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 获取个数
def get(self, *args, **kwargs):
# 获取单个对象
def create(self, **kwargs):
# 创建对象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 获取第一个
def last(self):
# 获取最后一个
def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 删除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有结果
Django的路由映射
include url 与 path
include()
from django.conf.urls improt *
urlpatterns = [
url(‘^/’,view=视图函数,name=‘url别名’,)
]
实际上url方法的参数有四个
1,正则表达式
正则表达式用来匹配url:
^匹配开头 $ 匹配结尾 但是在django中不建议在url开始直接使用 ^$的方式来匹配url 可以使用/代替$符号
(?P<参数名>\w+) 用来匹配url中传递的参数
^匹配开头
$匹配结尾
{}非贪婪模式匹配前面表达式限定个数
[]匹配多个
\w匹配数字字母下划线
\d数字
\s制表符号
\转义符号
2,viwefunction 视图函数
当url匹配成功之后会执行视图函数
3,为url起别名,方便后边制作权限和路由反转的时候使用
4,kwargs,向视图函数的传递值
include()方法路由分发实现url的分级处理,使管理大量的url更加快速方便,同样的也实现了url之间的结耦合,
include(urls模块)
运用场景,
假设有两条url为
www.quanshu.com/book/1055/4.html
www.quanshu.com/author/1.html
利用include可以讲两个url分给两个app来管理或者两个urls文件来管理,使url分级处理更加方便


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









