




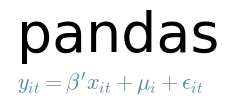
Pandas易于使用的数据结构和数据分析工具
使用前安装该模块:使用pycharm可以进入 Settings-> Project ->Project Interpreter -> 点击右侧,绿色加号
在出来的搜索框输入pandas-> 点击下面的Install Package 等待提示安装成功即可。
import numpy as np
import pandas as pd
s = pd.Series([i * 2 for i in range(1, 11)])
print(type(s))
dates = pd.date_range("20170301", periods=8) # 开始字符串 共生成8个时间段(8条记录)
df = pd.DataFrame(np.random.randn(8, 5), index=dates, columns=list("ABCDE")) # 生成8行5列 符合正态分布曲线的数值 索引(行头) 列头
print(df)
df2 = pd.DataFrame({"A": 1,
"B": pd.Timestamp("20170301"),
"C": pd.Series(1, index=list(range(4)), dtype="float"),
"D": np.array([3] * 4, dtype="float32"),
"E": pd.Categorical(["police", "student", "teacher", "doctor"])})
# 按照列进行赋值
print(df2)
# 基本操作
print("打印前三行\n", df.head(3)) # 打印前三行
print("打印后三行\n", df.tail(3)) # 打印后三行
print("打印索引\n", df.index) # 打印索引
print("打印值\n", df.values) # 打印值
print("打印矩阵转置\n", df.T) # 打印它的转置
# print(df.sort(columns="C"))
print("打印索引排序\n", df.sort_index(axis=1, ascending=False)) # 索引排序
print("打印相关信息\n", df.describe()) # 打印相关信息
# 选择 切片
print("打印A列\n", df["A"]) # 打印A列
print("打印类型\n", type(df["A"])) # 打印类型
print("打印前三条记录\n", df[:3])
print("打印1-4号\n", df["20170301":"20170304"]) # 打印1号到4号
print("打印第一天\n", df.loc[dates[0]]) # 打印第一天 也就是0301
print("打印B和D列\n", df.loc["20170301":"20170304", ["B", "D"]]) # 打印 这两天 第B 和 第D列的值
print("打印0301号C列\n", df.at[dates[0], "C"]) # 取第0301号 第C列的值
print("打印2-3行,C-D列\n", df.iloc[1:3, 2:4]) # 2,3号, C,D列
print("打印2行5列的值\n", df.iloc[1, 4]) # 打印2行5列的值
print("打印2行5列的值\n", df.iat[1, 4]) # 同iloc 打印2行5列的值
# print("打印\n", df[df.B > 0][df.A < 0]) # 同search 查找
print("打印大于0的值\n", df[df > 0]) # 查看大于0的值
print("打印E列属于1-2之间的值\n", df[df["E"].isin([1, 2])]) # 判断E列中属于1-2之间的值
# Set
sl = pd.Series(list(range(10, 18)), index=pd.date_range("20170301", periods=8)) # 添加一列F
df["F"] = sl
print("添加一列后\n", df)
df.at[dates[0], "A"] = 0 # 直接修改特定值 A列第1个值为0
print("修改特定值\n", df)
df.iat[1, 1] = 1 # 直接修改特定值
df.loc[:, "D"] = np.array([4] * len(df)) # D列全改为4
print("修改一列\n", df)
df2 = df.copy() # 复制 赋值为df2
df2[df2 > 0] = -df2 # 将其中的大于0的值全部改为负值
print("拷贝的修改为负值\n", df2)
# missing value 缺省值处理
df1 = df.reindex(index=dates[:4], columns=list("ABCD") + ["G"]) # 添加一列
df1.loc[dates[0]:dates[1], "G"] = 1 # 赋值为1
print("存在缺省值\n", df1) # 但是存在缺省值
print("处理方式一:\n", df1.dropna()) # 处理方式 直接丢弃
print("处理方式二:\n", df1.fillna(value=2)) # 处理方式 填充固定值
# 参考 http://www.cnblogs.com/zhoulixiansen/p/10533286.html
# Statistic 统计应用
# sum求和 mean算术平方 var方差 std标准差 sample系数矩阵 cov协方差矩阵 skew偏度 describe基本描述 kurt峰度系数 median中位数 quantile样本4分位
print("均值\n", df.mean()) # 均值
print("样本方差\n", df.var()) #
s = pd.Series([1, 2, 4, np.nan, 5, 7, 9, 10], index=dates) # np.nan 就是缺省值
print("新表\n", s)
print("移动2个位置\n", s.shift(2)) # 移动2个位置
print("差别(与原数据比较)\n", s.diff()) # 表示一阶 填了表示多阶
print(df.apply(np.cumsum)) # 累加结果 numpy(axis) axis=0按行累加 axis=1按列累加 apple()函数自由度特别高
print(df)
print("极值\n", df.apply(lambda x: x.max() - x.min())) # 求极差
# concat 拼接
pieces = [df[:3], df[-3:]] # 把前三行 和 后三行进行拼接
print("拼接\n", pd.concat(pieces))
# 定义两个列表
left = pd.DataFrame({"key": ["x", "y"], "value": [1, 2]})
right = pd.DataFrame({"key": ["x", "z"], "value": [3, 4]})
print("left:", left)
print("right:", right)
print("指明单个连接键\n", pd.merge(left, right, on="key")) # “inner”,“outer”,“left”,“right"其中之一,默认为"inner”
print("参与合并的左侧DataFrame\n", pd.merge(left, right, on="key", how="left"))
print("inner连接\n", pd.merge(left, right, on="key", how="inner"))
print("outer连接\n", pd.merge(left, right, on="key", how="outer"))
df3 = pd.DataFrame({"A": ['a', 'b', 'c', 'b'], "B": list(range(4))}) # a=0 b=1 c=2 b=3
print(df3)
print("分组(合并同类项)\n", df3.groupby("A").sum()) # b=1+3=4
# # resharp
import datetime
df4 = pd.DataFrame(
{"A": ['one', 'one', 'two', 'three'] * 6,
"B": ['a', 'b', 'c'] * 8,
"C": ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 4,
"D": np.random.randn(24),
"E": np.random.randn(24),
"F": [datetime.datetime(2017, i, 1) for i in range(1, 13)] +
[datetime.datetime(2017, i, 15) for i in range(1, 13)]})
print(df4)
print("透视表\n", pd.pivot_table(df4, values="D", index=["A", "B"], columns="C"))
# 通过透视表,以A,B为索引对象,以c作为列,把D作为值填充
# Time series
t_exam = pd.date_range("20170301", periods=10, freq="S") # 一共10个时间段 秒计数
print("时间列表\n", t_exam)
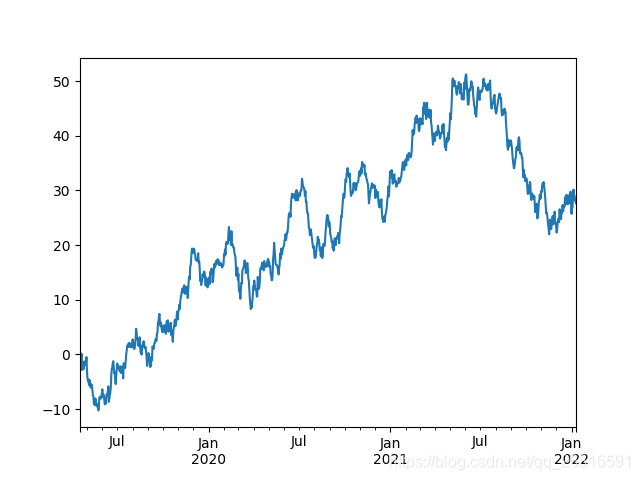
# 绘图
from pylab import *
ts = pd.Series(np.random.randn(1000), index=pd.date_range('20190417', periods=1000)) # 1-999随机数 1000个点 从20190417开始
ts = ts.cumsum()
ts.plot()
savefig("series")
show()
# 文件操作
df6 = pd.read_csv('1.csv')
print(df6)
df6.to_csv('test.csv') # 保存文件
# 读取Excel文件 先写文件路径及文件名 然后写sheet 几
df7 = pd.read_excel('2.xlsx', 'sheet1')
print(df7)
df7.to_excel('test.xlsx') # 保存文件
总结:
基本属性
- data=date_range("1",periods=10) 从1开始递增生成10个
- df=DataFrame(index=data,columns=list("ABCDE")) 行为data 列为'A''B''C''D''E'
- df.head(2) 前2行
- df.tail(2) 后2行
- df.index 获取索引
- df.values 获取值
- df.T 获取列表转置
- df.sort_index() 索引排序
- df.describe() 打印相关信息
- df['A'] 获取A列
- df[:3] 切片 获取前三条记录
- df["20190422":"20190428"] 获取20190422-20190428的所有值
- df.loc[dates[0]] 获取第一条记录
- df.at[dates[0],'C'] 获取第一行第C列的值
- df.iloc[1:3,2:4] 获取从1-3行 2-4列的值
- df.iat[1,4] 获取2行5列的值 同df.iloc[1,4]
- df[df>0] 获取大于0的值
- df[df["E"].isin([1,2]) 判断 E中属于1-2之间的值
列表操作
- 添加一列 直接写df["F"] 原数据中如果没有F则添加该列
- 修改特定值 df.at[dates[0],"A"] 修改第一行 第A列的值
- 修改一列 df.loc[:,"D"]=np.array([4]*len(df)) 将D列全改为4
- 复制列表 df2=df.copy()
缺省值处理
- 直接丢弃 df.dropna()
- 填充固定值 df.fillna(value=2) 将所有缺省值填充为2
统计应用
- df.sum() 求和
- df.mean() 求算术均值
- df.var() 求方差
- df.std() 求标准差
- df.sample() 求系数矩阵
- df.cov() 求协方差矩阵
- df.skew 偏度
- df.describe() 打印基本描述
- df.kurt 峰度系数
- df.median 中位数
- df.quantile() 样本4分位
连接列表
- pd.merge(df1,df2,on="key",how="left") 连接 包括指明单个连接键 inner outer left right
- df.groupby("A").sum() 分组 合并同类项
- pd.pivot_table(df1,values="D",index=["A","B"],columns="C") 以A,B为索引 C为列 D为值填充
绘图
-
ts = pd.Series(np.random.randn(1000), index=pd.date_range('20190417', periods=1000)) 生成1000个数据点 1-1000之间的数 从20190417开始
-
ts = ts.cumsum() 计算轴向元素累积加和,返回由中间结果组成的数组
-
savefig("series") 保存文件 一定要在show() 之间保存 不然容易保存成空白图
效果图:
文件操作
- pd.read_csv('1.csv') 读取csv数据
- df2.to_csv('2.csv') 文件另存为
- df.read_excel('2.xlsx','sheet1') 读取Excel文件 打开sheet1块
- df.to_excel('3.xlsx') 文件另存为

















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









