




接着上一篇文章《OkHttp源码解析(上)》继续分析缓存拦截器:
缓存拦截器
@Override public Response intercept(Chain chain) throws IOException {
// 通过url的md5数据 从文件缓存查找(GRT请求才有缓存)
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
// 缓存策略:根据各种请求头组成
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
if (cache != null) {
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// 没有网络请求也没有缓存
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
// 没有网络请求,使用缓存
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
Response networkResponse = null;
try {
// 交给下一个拦截器去处理
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
if (cacheResponse != null) {
// 更新缓存
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
// The cache cannot be written.
}
}
}
return response;
}
基本使用
如果使用缓存拦截器,则需要我们在创建OkHttpClient时配置一个缓存
OkHttpClient client = new OkHttpClient.Builder()
.cache(new Cache(new File(""), 1024))
.build();
缓存对象需要传缓存文件的存放目录以及文件最大的大小。
如果服务器返回的缓存响应可以持久化,我们可以把缓存保存在文件里,下次请求直接读取本地的文件,减少流量消耗,加快处理速度,这就是缓存拦截器存在的意义。
CacheInterceptor ,在发出请求前,判断是否命中缓存。如果命中则可以不请求,直接使用缓存的响应。 (只会存在Get请求的缓存)
步骤为:
-
从缓存中获得对应请求的响应缓存
-
创建
CacheStrategy,创建时会判断是否能够使用缓存,在CacheStrategy中存在两个成员:networkRequest与cacheResponse。他们的组合如下:networkRequest cacheResponse 说明 Null Not Null 直接使用缓存 Not Null Null 向服务器发起请求 Null Null 直接gg,okhttp直接返回504 Not Null Not Null 发起请求,若得到响应为304(无修改),则更新缓存响应并返回 即:networkRequest存在,则优先发起网络请求,否则使用cacheResponse缓存,若都不存在,则请求失败!
-
交给下一个责任链继续处理
-
后续工作,返回304则用缓存的响应;否则使用网络响应并缓存本次响应(只缓存Get请求的响应)
缓存拦截器的工作说起来比较简单,但是具体的实现,需要处理的内容很多,在缓存拦截器中判断是否可以使用缓存,或者是请求服务器都是通过CacheStrategy判断。看一下什么是缓存策略:
缓存策略
首先需要认识几个请求头与响应头:
| 响应头 | 说明 | 例子 |
|---|---|---|
| Date | 消息发送的时间 | Date: Sat, 18 Nov 2028 06:17:41 GMT |
| Expires | 资源过期的时间 | Expires: Sat, 18 Nov 2028 06:17:41 GMT |
| Last-Modified | 资源最后修改时间 | Last-Modified: Fri, 22 Jul 2016 02:57:17 GMT |
| ETag | 资源在服务器的唯一标识 | ETag: “16df0-5383097a03d40” |
| Age | 服务器用缓存响应请求,该缓存从产生到现在经过 多长时间(秒) | Age: 3825683 |
| Cache-Control | - | - |
| 请求头 | 说明 | 例子 |
|---|---|---|
| If-Modified-Since | 服务器没有在指定的时间后修改请求对应资 源,返回304(无修改) | If-Modified-Since: Fri, 22 Jul 2016 02:57:17 GMT |
| If-None-Match | 服务器将其与请求对应资源的 Etag 值进行 比较,匹配返回304 | If-None-Match: “16df0- 5383097a03d40” |
| Cache-Control | - | - |
其中Cache-Control可以在请求头存在,也能在响应头存在,对应的value可以设置多组组合:
max-age=[秒]:资源最大有效时间public:表明该资源可以被任何用户缓存,比如客户端,代理服务器等都可以缓存资源private:表明该资源只能被单个用户缓存,默认是privateno-store:资源不允许被缓存no-cache:(请求)不使用缓存immutable:(响应)资源不会改变min-fresh=[秒]:(请求)缓存最小新鲜度(用户认为这个缓存有效的时长)must-revalidate:(响应)不允许使用过期缓存max-stale=[秒]:(请求)缓存过期后多久内仍然有效
假设存在max-age=100,min-fresh=20。这代表了用户认为这个缓存的响应,从服务器创建响应 到 能够缓
存使用的时间为100-20=80s。但是如果max-stale=100。这代表了缓存有效时间80s过后,仍然允许使用
100s,可以看成缓存有效时长为180s。
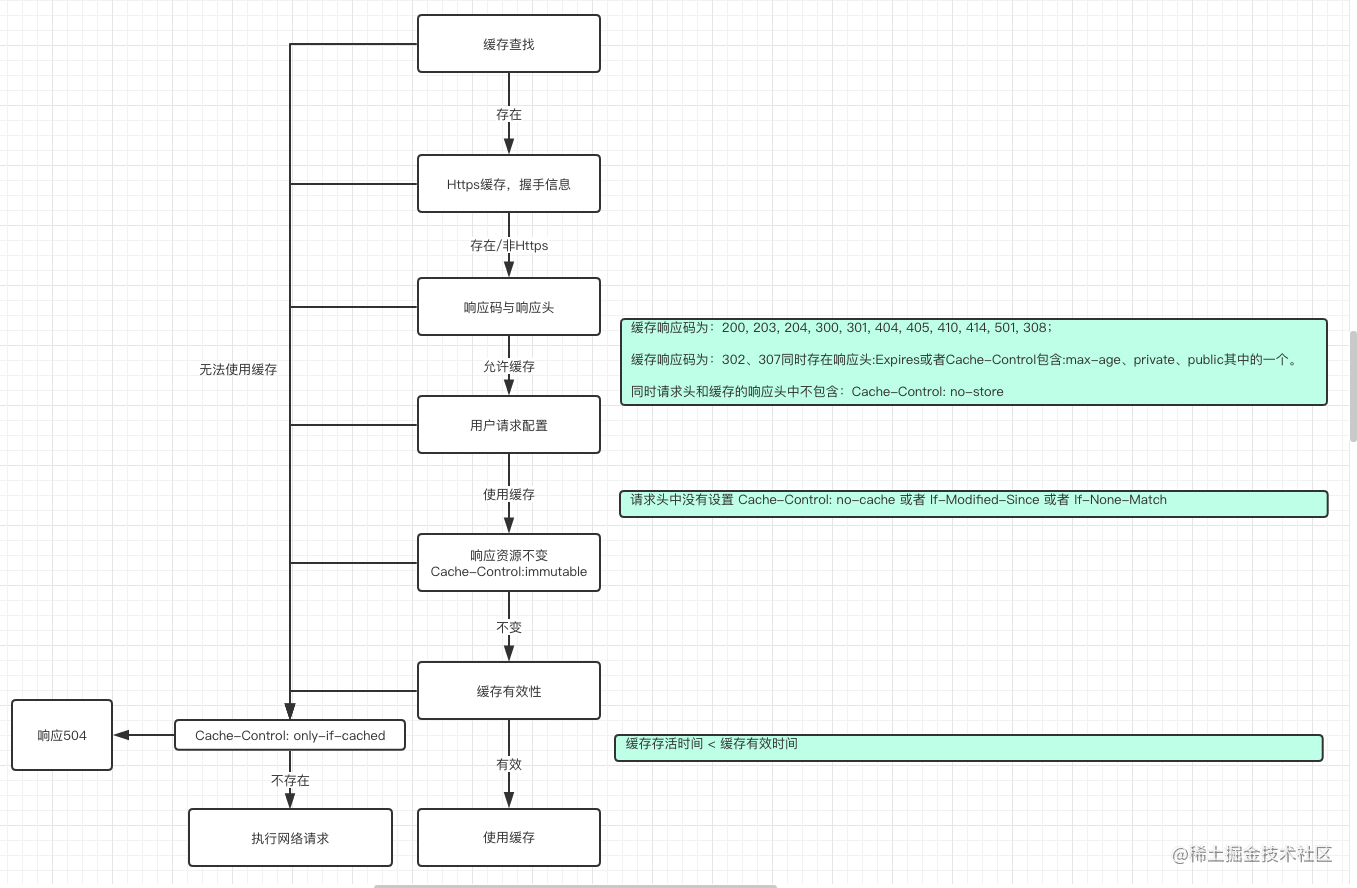
详细流程
能不能使用缓存的判断就在这一行代码里,我们看下这行代码:
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
如果从缓存中获得了本次请求URL对应的 Response ,首先会从响应中获得以上数据备用。
public Factory(long nowMillis, Request request, Response cacheResponse) {
this.nowMillis = nowMillis;
this.request = request;
this.cacheResponse = cacheResponse;
if (cacheResponse != null) {
this.sentRequestMillis = cacheResponse.sentRequestAtMillis();
this.receivedResponseMillis = cacheResponse.receivedResponseAtMillis();
Headers headers = cacheResponse.headers();
for (int i = 0, size = headers.size(); i < size; i++) {
String fieldName = headers.name(i);
String value = headers.value(i);
if ("Date".equalsIgnoreCase(fieldName)) {
servedDate = HttpDate.parse(value);
servedDateString = value;
} else if ("Expires".equalsIgnoreCase(fieldName)) {
expires = HttpDate.parse(value);
} else if ("Last-Modified".equalsIgnoreCase(fieldName)) {
lastModified = HttpDate.parse(value);
lastModifiedString = value;
} else if ("ETag".equalsIgnoreCase(fieldName)) {
etag = value;
} else if ("Age".equalsIgnoreCase(fieldName)) {
ageSeconds = HttpHeaders.parseSeconds(value, -1);
}
}
}
}
判断缓存的命中会使用 get() 方法。
public CacheStrategy get() {
CacheStrategy candidate = getCandidate();
// 如果可以使用缓存,那networkRequest必定为null
if (candidate.networkRequest != null && request.cacheControl().onlyIfCached()) {
// We're forbidden from using the network and the cache is insufficient.
return new CacheStrategy(null, null);
}
return candidate;
}
get方法中调用 getCandidate() 方法来完成真正的缓存判断。
1. 缓存是否存在
整个方法中的第一个判断是缓存是不是存在
if (cacheResponse == null) {
return new CacheStrategy(request, null);
}
cacheResponse 是从缓存中找到的响应,如果为null,那就表示没有找到对应的缓存,创建的 CacheStrategy 实例对象只存在 networkRequest ,这代表了需要发起网络请求。
2. https请求的缓存
if (request.isHttps() && cacheResponse.handshake() == null) {
return new CacheStrategy(request, null);
}
如果本次请求是HTTPS,但是缓存中没有对应的握手信息,那么缓存无效。
3. 响应码以及响应头
if (!isCacheable(cacheResponse, request)) {
return new CacheStrategy(request, null);
}
调用了isCacheable方法,如果这个方法返回false,则不使用缓存,进行网络请求,看下这个方法:
public static boolean isCacheable(Response response, Request request) {
// Always go to network for uncacheable response codes (RFC 7231 section 6.1),
// This implementation doesn't support caching partial content.
switch (response.code()) {
case HTTP_OK:
case HTTP_NOT_AUTHORITATIVE:
case HTTP_NO_CONTENT:
case HTTP_MULT_CHOICE:
case HTTP_MOVED_PERM:
case HTTP_NOT_FOUND:
case HTTP_BAD_METHOD:
case HTTP_GONE:
case HTTP_REQ_TOO_LONG:
case HTTP_NOT_IMPLEMENTED:
case StatusLine.HTTP_PERM_REDIRECT:
// These codes can be cached unless headers forbid it.
break;
case HTTP_MOVED_TEMP:
case StatusLine.HTTP_TEMP_REDIRECT:
// These codes can only be cached with the right response headers.
// http://tools.ietf.org/html/rfc7234#section-3
// s-maxage is not checked because OkHttp is a private cache that should ignore s-maxage.
if (response.header("Expires") != null
|| response.cacheControl().maxAgeSeconds() != -1
|| response.cacheControl().isPublic()
|| response.cacheControl().isPrivate()) {
break;
}
// Fall-through.
default:
// All other codes cannot be cached.
return false;
}
// A 'no-store' directive on request or response prevents the response from being cached.
return !response.cacheControl().noStore() && !request.cacheControl().noStore();
}
缓存响应中的响应码为00, 203, 204, 300, 301, 404, 405, 410, 414, 501, 308 的情况下,只判断服务器是不是给了Cache-Control: no-store (资源不能被缓存),所以,如果服务器给到了这个响应头,那就和前面两个判定一致(缓存不可用)。否则继续进一步判断缓存是否可用。
而如果响应码是302/307(重定向),则需要进一步判断是不是存在一些允许缓存的响应头。根据注解中的给到的文档 http://tools.ietf.org/html/rfc7234#section-3 中的描述,如果存在 Expires 或者 Cache-Control 的值为:
max-age=[秒]:资源最大有效时间public:表明该资源可以被任何用户缓存,比如客户端,代理服务器等都可以缓存资源private:表明该资源只能被单个用户缓存,默认是private。
同时不存在 Cache-Control: no-store ,那就可以继续进一步判断缓存是否可用。
所以综合来看判定优先级如下:
- 响应码不为 200, 203, 204, 300, 301, 404, 405, 410, 414, 501, 308,302,307 缓存不可用;
- 当响应码为302或者307时,未包含某些响应头,则缓存不可用;
- 当存在 Cache-Control: no-store 响应头则缓存不可用。
如果响应缓存可用,进一步再判断缓存有效性。
4. 用户的请求配置
CacheControl requestCaching = request.cacheControl();
if (requestCaching.noCache() || hasConditions(request)) {
return new CacheStrategy(request, null);
}
private static boolean hasConditions(Request request) {
return request.header("If-Modified-Since") != null || request.header("If-None-Match") != null;
}
走到这一步,OkHttp需要先对用户本次发起的 Request 进行判定,如果用户指定了 Cache-Control: no-cache (不使用缓存)的请求头,或者请求头包含
If-Modified-Since或If-None-Match,那么就不允许使用缓存。
| 请求头 | 说明 |
|---|---|
| Cache-Control: no-cache | 忽略缓存 |
| If-Modified-Since:时间 | 值一般为 Data 或 lastModified ,服务器没有在指定的时间后修改请求对应资源,返回304(无修改) |
| If-None-Match:标记 | 值一般为 Etag ,将其与请求对应资源的 Etag 值进行比较;如果匹配,返回304 |
这意味着如果用户请求头中包含这些内容,那么就必须向服务器发起请求。但是需要注意的是:OkHttp不会缓存304的响应,如果是这种情况,即用户主动要求与服务器发起请求,服务器返回的304(无响应体),则直接把304的响应返回给用户:“既然你主动要求,我就只告知你本次请求结果”。而如果不包含这些请求头,那继续判定缓存有效性。
5. 资源是否不变
CacheControl responseCaching = cacheResponse.cacheControl();
if (responseCaching.immutable()) {
return new CacheStrategy(null, cacheResponse);
}
如果缓存的响应中包含: Cache-Control: immutable, 这意味着对应请求的响应内容将一直不会改变。此时就可以直接使用缓存。否则继续判断缓存是否可用。
6. 响应的缓存有效期
这一步为进一步根据缓存响应中的一些信息判定缓存是否处于有效期内。如果满足:
缓存存活时间 < 缓存新鲜度 - 缓存最小新鲜度 + 过期后继续使用时长
代表可以使用缓存。其中新鲜度可以理解为有效时间,而这里的 “缓存新鲜度-缓存最小新鲜度” 就代表了缓存真正有效的时间。
7. 收尾
至此,缓存的判定结束,拦截器中只需要判断 CacheStrategy 中 networkRequest 与 cacheResponse 的不同组合就能够判断是否允许使用缓存。
但是值得注意的是:如果用户在创建请求时,配置了onlyIfCached,这意味着用户这次希望这个请求只从缓存获得,不需要发起请求。那如果生成的 CacheStrategy 存在 networkRequest ,这意味着肯定会发起请求,此时出现冲突,那么直接给到拦截器一个既没有 networkRequest 又没有 cacheResponse 的对象,拦截器直接返回给用户504!
//缓存策略 get 方法
if (candidate.networkRequest != null && request.cacheControl().onlyIfCached()) {
// We're forbidden from using the network and the cache is insufficient.
return new CacheStrategy(null, null);
}
//缓存拦截器
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
总结
- 如果从缓存获取的
Response是null,那就需要使用网络请求获取响应。 - 如果是Https请求,但是又丢失了握手信息,那也不能使用缓存,需要进行网络请求
- 如果判断响应码不能缓存且响应头有
no-store标识,那就需要进行网络请求 - 如果请求头有
no-cache标识或者有If-Modified-Since/If-None-Match,那么需要进行网络请求 - 如果响应头没有
no-cache标识,且缓存时间没有超过极限时间,那么可以使用缓存,不需要进行网络请求 - 如果缓存过期了,判断响应头是否设置
Etag/Last-Modified/Date,没有那就直接使用网络请求,否则需要考虑服务器返回304;
并且,只要需要进行网络请求,请求头中就不能包含 only-if-cached ,否则框架直接返回504!
缓存拦截器本身主要逻辑其实都在缓存策略中,拦截器本身逻辑非常简单,如果确定需要发起网络请求,则下一个拦截器为 ConnectInterceptor。
连接拦截器
ConnectInterceptor,打开与目标服务器的连接,并继续下一个拦截器,代码量不多:
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
虽然代码里很少,实际上大部分功能都封装到其他类去了,这里只是调用而已。
首先我们看到的 StreamAllocation 这个对象是在第一个拦截器:重试重定向拦截器创建的,但是真正使用的地方却在这里。
StreamAllocation对象 主要用来管理两个关键角色:
- RealConnection:真正建立连接的对象,利用Socket建立连接
- ConnectionPool:连接池,用来管理和复用连接。
首先看第一个角色,StreamAllocation是如何创建socket连接的。
创建连接
StreamAllocation.newStream()最终调用findConnection()方法来建立连接。
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
boolean foundPooledConnection = false;
RealConnection result = null;
Route selectedRoute = null;
Connection releasedConnection;
Socket toClose;
synchronized (connectionPool) {
if (released) throw new IllegalStateException("released");
if (codec != null) throw new IllegalStateException("codec != null");
if (canceled) throw new IOException("Canceled");
// Attempt to use an already-allocated connection. We need to be careful here because our
// already-allocated connection may have been restricted from creating new streams.
releasedConnection = this.connection;
toClose = releaseIfNoNewStreams();
// 1 查看是否有完好的连接
if (this.connection != null) {
// We had an already-allocated connection and it's good.
result = this.connection;
releasedConnection = null;
}
if (!reportedAcquired) {
// If the connection was never reported acquired, don't report it as released!
releasedConnection = null;
}
if (result == null) {
// 2 连接池中是否用可用的连接,有则使用
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
foundPooledConnection = true;
result = connection;
} else {
selectedRoute = route;
}
}
}
closeQuietly(toClose);
if (releasedConnection != null) {
eventListener.connectionReleased(call, releasedConnection);
}
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
}
if (result != null) {
// If we found an already-allocated or pooled connection, we're done.
return result;
}
// If we need a route selection, make one. This is a blocking operation.
boolean newRouteSelection = false;
//线程的选择,多IP操作
if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext())) {
newRouteSelection = true;
routeSelection = routeSelector.next();
}
//3 如果没有可用连接,则自己创建一个
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
if (newRouteSelection) {
// Now that we have a set of IP addresses, make another attempt at getting a connection from
// the pool. This could match due to connection coalescing.
List<Route> routes = routeSelection.getAll();
for (int i = 0, size = routes.size(); i < size; i++) {
Route route = routes.get(i);
Internal.instance.get(connectionPool, address, this, route);
if (connection != null) {
foundPooledConnection = true;
result = connection;
this.route = route;
break;
}
}
}
if (!foundPooledConnection) {
if (selectedRoute == null) {
selectedRoute = routeSelection.next();
}
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
route = selectedRoute;
refusedStreamCount = 0;
result = new RealConnection(connectionPool, selectedRoute);
acquire(result, false);
}
}
// If we found a pooled connection on the 2nd time around, we're done.
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
return result;
}
//4 开始TCP以及TLS握手操作
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
routeDatabase().connected(result.route());
//5 将新创建的连接,放在连接池中
Socket socket = null;
synchronized (connectionPool) {
reportedAcquired = true;
// Pool the connection.
Internal.instance.put(connectionPool, result);
// If another multiplexed connection to the same address was created concurrently, then
// release this connection and acquire that one.
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
eventListener.connectionAcquired(call, result);
return result;
}
整个流程如下:
- 查找是否有完整的连接可用。
- Socket没有关闭
- 输入流没有关闭
- 输出流没有关闭
- Http2连接没有关闭
- 连接池中是否有可用的连接,如果有,则可用。
- 如果没有可用连接,则自己创建一个
- 开始TCP连接以及TLS握手操作
- 将新创建的连接加入连接池
上面的方法完成后,会创建一个RealConnection对象,然后调用该方法的connect()方法建立连接。
连接池
我们知道在负责的网络环境下,频繁地进行建立Socket连接(TCP三次握手)和断开Socket连接(TCP四次挥手)是非常消耗网络资源和浪费时间地,HTTP中的keepalive连接对于 降低延迟和提升速度有非常重要的作用。
复用连接就需要对连接进行管理,这里就引入了连接池的概念。
连接拦截器里面,主要用到了一个Socket连接池,在ConnectionPool内部维护了一个线程池,来清理连接。我们重点看下这个连接池:
顾名思义,连接池就是一个存放socket的池子,我们知道,每个socket都会绑定一个IP和端口,那么连接池里会有多个socket,当我与某一台服务器建立连接时,我先从连接池中去找,有没有已经建立好的socket,有的话,直接使用这个socket。
public ConnectionPool() {
this(5, 5, TimeUnit.MINUTES);
}
这个连接池我们是可以配置的,默认配置就是上面这段代码,最大闲置连接数为5个,每个闲置socket的存活时间为5分钟。
当我们往这个连接池增加一个新的连接时,调用put方法:
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
// 如果清理任务未启动就启动它,然后把连接加入队列。
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
在添加之前,有一个判断,这个里面的意思是:如果清理任务没有启动,那么就启动它。再把新连接加入队列。
//清理连接,在线程池executor里调用。
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
//执行清理,并返回下次需要清理的时间。
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
//在timeout时间内释放锁
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
这个清理任务一直在执行,调用cleanup()方法,把当前时间传进去。
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// 检查连接是否正在被使用
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
// 否则记录闲置连接数
idleConnectionCount++;
// 获得这个连接的闲置时间
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
// 如果超过了存活时间(5分钟)或者池内连接数大于5个,立即移除当前池内闲置时间最长的那个连接
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
return keepAliveDurationNs;
} else {
// No connections, idle or in use.
cleanupRunning = false;
return -1;
}
}
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return 0;
}
首先遍历这个connections队列,如果当前连接正在被使用,则inUseConnectionCount ++,继续遍历下一个连接。最终得到当前池内的正在连接数和闲置连接数。如果池内闲置时间最长的那个连接超过了存活时间(5分钟)或者池内连接数大于5个,立即移除该连接。
如果我们从连接池获取一个连接,通过get方法:
@Nullable RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
return null;
}
同样是遍历connections队列,通过isEligible方法判断当前连接能否被复用。
public boolean isEligible(Address address, @Nullable Route route) {
// 如果连接池中的连接都在使用,那就不能复用
if (allocations.size() >= allocationLimit || noNewStreams) return false;
// If the non-host fields of the address don't overlap, we're done.
if (!Internal.instance.equalsNonHost(this.route.address(), address)) return false;
// If the host exactly matches, we're done: this connection can carry the address.
if (address.url().host().equals(this.route().address().url().host())) {
return true; // This connection is a perfect match.
}
// At this point we don't have a hostname match. But we still be able to carry the request if
// our connection coalescing requirements are met. See also:
// https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding
// https://daniel.haxx.se/blog/2016/08/18/http2-connection-coalescing/
// 1. This connection must be HTTP/2.
if (http2Connection == null) return false;
// 2. The routes must share an IP address. This requires us to have a DNS address for both
// hosts, which only happens after route planning. We can't coalesce connections that use a
// proxy, since proxies don't tell us the origin server's IP address.
if (route == null) return false;
if (route.proxy().type() != Proxy.Type.DIRECT) return false;
if (this.route.proxy().type() != Proxy.Type.DIRECT) return false;
if (!this.route.socketAddress().equals(route.socketAddress())) return false;
// 3. This connection's server certificate's must cover the new host.
if (route.address().hostnameVerifier() != OkHostnameVerifier.INSTANCE) return false;
if (!supportsUrl(address.url())) return false;
// 4. Certificate pinning must match the host.
try {
address.certificatePinner().check(address.url().host(), handshake().peerCertificates());
} catch (SSLPeerUnverifiedException e) {
return false;
}
return true; // The caller's address can be carried by this connection.
}
连接池的主要流程如下:
- 检查连接是否正在被使用,并标记正在被使用的连接。
- 标记空闲连接。
- 如果空闲连接超过5个或者keepalive时间大于5分钟,则将该连接清理掉。
- 返回此连接的到期时间,供下次进行清理。
- 全部都是活跃连接,5分钟时候再进行清理。
- 没有任何连接,跳出循环。
- 关闭连接,返回时间0,立即再次进行清理。
总结
这个拦截器中的所有实现都是为了获得一份与目标服务器的有效连接,在这个连接上进行HTTP数据的收发。
请求服务器拦截器
CallServerInterceptor, 利用 HttpCodec 发出请求到服务器并且解析生成 Response 。
首先调用 httpCodec.writeRequestHeaders(request); 将请求头写入到缓存中(直到调用 flushRequest() 才真正发
送给服务器)。然后马上进行第一个逻辑判断:
Response.Builder responseBuilder = null;
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return
// what we did get (such as a 4xx response) without ever transmitting the request body.
if ("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(true);
}
if (responseBuilder == null) {
// Write the request body if the "Expect: 100-continue" expectation was met.
realChain.eventListener().requestBodyStart(realChain.call());
long contentLength = request.body().contentLength();
CountingSink requestBodyOut =
new CountingSink(httpCodec.createRequestBody(request, contentLength));
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
realChain.eventListener()
.requestBodyEnd(realChain.call(), requestBodyOut.successfulCount);
} else if (!connection.isMultiplexed()) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection
// from being reused. Otherwise we're still obligated to transmit the request body to
// leave the connection in a consistent state.
streamAllocation.noNewStreams();
}
}
httpCodec.finishRequest();
整个if都和一个请求头有关,Expect:100-continue。这个请求头代表了在发送请求体之前需要和服务器确定是否愿意接受客户端发送的请求体,所以permitsRequestBody判断为是否会携带请求体的方式(POST),如果if条件成立,则会先给服务器发起一次查询是否愿意接收请求体,这时候如果服务器愿意会响应100(没有响应体,responseBuilder 即为null),这时候才能够继续发送剩余请求数据。
但是如果服务器不同意接收请求体,那么我们就需要标记该连接不能再被复用,调用 noNewStreams() 关闭相关的Socket。
if (responseBuilder == null) {
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(false);
}
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
这时 responseBuilder 的情况即为:
- POST方式请求,请求头中包含
Expect,服务器允许接受请求体,并且已经发出了请求体,responseBuilder为null。 - POST方式请求,请求头中包含
Expect,服务器不允许接受请求体,responseBuilder不为null - POST方式请求,请求头中未包含
Expect,直接发出请求体,responseBuilder 为null - POST方式请求,没有请求体,
responseBuilder为null - GET方式请求,
responseBuilder为null
对应上面的5种情况,读取响应头并且组成响应 Response ,注意:此 Response 没有响应体。同时需要注意的是,如果服务器接受Expect: 100-continue 这是不是意味着我们发起了两次 Request ?那此时的响应头是第一次查询服务器是否支持接受请求体的,而不是真正的请求对应的结果响应。所以紧接着:
int code = response.code();
if (code == 100) {
// server sent a 100-continue even though we did not request one.
// try again to read the actual response
responseBuilder = httpCodec.readResponseHeaders(false);
response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
code = response.code();
}
如果响应是100,这代表了是请求 Expect: 100-continue 成功的响应,需要马上再次读取一份响应头,这才是真正的请求对应结果响应头。
然后收尾:
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
forWebSocket 代表websocket的请求,我们直接进入else,这里就是读取响应体数据。然后判断请求和服务器是不是都希望长连接,一旦有一方指明 close ,那么就需要关闭 socket 。而如果服务器返回204/205,一般情况而言不会存在这些返回码,但是一旦出现这意味着没有响应体,但是解析到的响应头中包含 Content-Lenght 且不为0,这表响应体的数据字节长度。此时出现了冲突,直接抛出协议异常!
总结
在这个拦截器中就是完成HTTP协议报文的封装与解析。
OkHttp总结
整个OkHttp功能的实现就在五个默认的拦截器中,所以先理解拦截器模式的工作机制是先决条件。这五大拦截器分别为:重试重定向拦截器、桥接拦截器、缓存拦截器、连接拦截器、请求服务器拦截器。每一个拦截器负责的工作不同,就像工厂流水线,最终经过这五道工序,完成了最终的产品。
但是与流水线不同的是,OkHttp中的拦截器每次发起请求都会在交给下一个拦截器之前干一些事情,在获得了结果之后又干一些事情。整个过程在请求向是顺序的,而响应向则是逆序。
当用户发起一个请求后,会由任务分发起 Dispatcher 将请求包装并交给重试拦截器处理。
- 重试重定向拦截器在交出(交给下一个拦截器)之前,负责判断用户是否取消了请求,在获得了结果之后,会根据响应码判断是否需要重定向,如果满足条件,那么就会重新执行所有拦截器。
- 桥接拦截器在交出之前,负责将HTTP协议必备的请求头加入其中(如:Host)并添加一些默认的行为(如:GZIP压缩);在获得了结果后,调用保存cookie接口并解析GZIP数据。
- 缓存拦截器顾名思义,交出之前读取并判断是否使用缓存;获得结果后判断是否缓存。
- 连接拦截器在交出之前,负责找到或者新建一个连接,并获得对应的socket流;在获得结果后不进行额外的处理。
- 请求服务器拦截器进行真正的与服务器的通信,向服务器发送数据,解析读取的响应数据。
在经过了这一系列的流程后,就完成了一次HTTP请求!
本人能力有限,在分析过程中,代码有所删减,如果文章中有写得不对的地方,欢迎在留言区留言大家一起讨论,共同学习进步。如果觉得我的文章给予你帮助,也请给我一个喜欢和关注。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









