




 本文探讨了如何通过扩大GAN规模提升图像生成的保真度和多样性。研究发现,增大批次大小、增加通道数、共享嵌入层、多层级潜在空间和截断技巧等方法能有效提升模型性能。同时,大型GAN存在不稳定性,通过正交正则化等技术可缓解。文章介绍了Inception Score和Fréchet Inception Distance作为评估指标。
本文探讨了如何通过扩大GAN规模提升图像生成的保真度和多样性。研究发现,增大批次大小、增加通道数、共享嵌入层、多层级潜在空间和截断技巧等方法能有效提升模型性能。同时,大型GAN存在不稳定性,通过正交正则化等技术可缓解。文章介绍了Inception Score和Fréchet Inception Distance作为评估指标。
ICLR2019在审文章,作者单位DeepMind
总述
文章希望既保证GAN生成图像的保真度又保证生成图像的多样性。对此,作者认为他们有三点贡献:
1、论证了GANs能通过scaling来提升性能。他们使用与原先技术相比,2~4倍的参数量和8倍的batch size,引入了两种简单的结构调整方法来提升网络的可扩展性,并修改一种正则化方案来提高conditioning。
2、上述修改产生的另一种影响是,模型非常适用于“trucation trick”,它是一种简单的采样技术,可以对样本多样性与保真性进行外部地细粒度地调节。
3、发现大型GAN特有的不稳定性,并从经验上对他们进行描述。经过分析表明通过现有技术与创新的技术的结合能够减少这种不稳定性,但是训练时完全的稳定性只能通过以较大地牺牲模型表现来实现。
作者训练的class-condition GAN在ImageNet上的表现很好(128X128分辨率),与state-of-art相比,Inception Score(IS)从52.52提升到166.3,Frechet Inception Distance(FID)从18.65下降到9.6.
Scaling up GANs
Baseline 模型
基于SA-GAN结构,使用hinge-loss作为GAN的目标函数。使用class-conditional BN向生成器G中加入类别信息,用projection向鉴别器D中加入类别信息。优化设置与原SA-GAN论文相同,但学习率减半,D每更新两次,G更新一次。对G的权重采用滑动平均(但文章发现progressive learning对模型并不必要)。不同于其他论文使用 N ( 0 , 0.02 I ) \mathcal{N}(0,0.02I) N(0,0.02I)或Xavier进行初始化,本文使用正交初始化。BN层的统计值是基于所有设备上的统计,不同于标准实现采用基于每个设备的统计。
A. 加大 BATCH SIZE
基于此模型,作者发现,将batch size提高为原来8倍,IS分数提升约46%.大的batchsize一方面提高模型表现,使模型更快收敛;另一方面,作者发现,这种scaling使得模型更不稳定,训练中很容易collapse。
B. 提高通道数
接着,作者尝试将模型中每层的通道数提高50%,参数量翻番,这使得IS分数进一步提升21%。
C. 共享嵌入层
作者还发现,条件BN中嵌入类别c占用了很多的权重,文章于是采用共享的嵌入来取代独立的层嵌入。这降低了内存与计算成本,模型训练速度提高37%。
D. 多层级潜在空间
此外,作者使用了多种hierarchical latent spaces,即将噪声向量 z z z输入到生成器的不同层中,而不是仅仅输入到第一层。这种做的直觉思路是用潜在空间来直接影响不同分辨率以及不同层次下的特征。hierarchical latents降低了计算量与内存占用,模型表现提升4%,训练速度提高18%。
E. 截断技巧
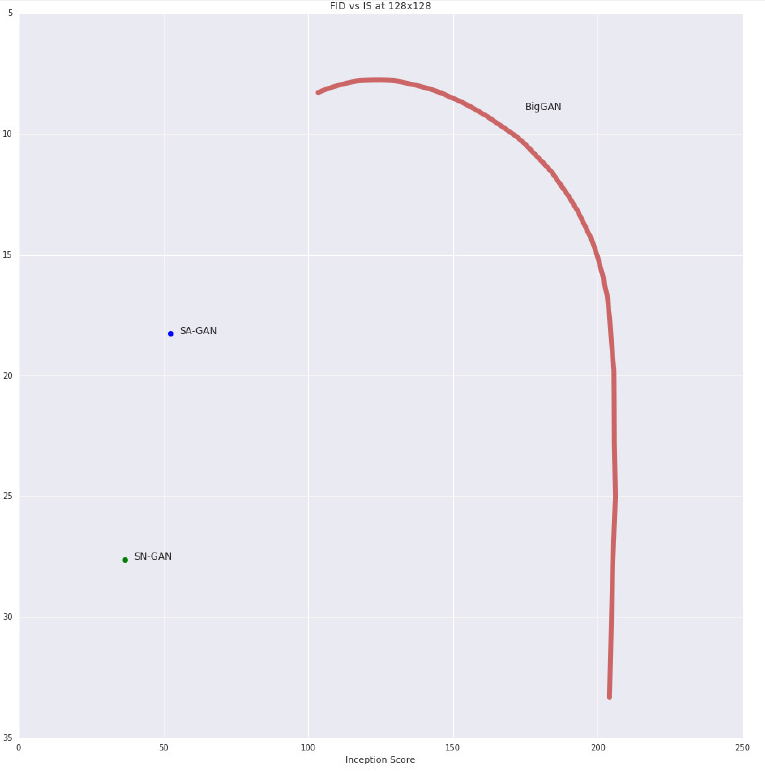
一般的噪声向量服从分布 z ∼ N ( 0 , I ) z\sim\mathcal{N}(0,I) z∼N(0,I),但该技巧为其采样设置一个阈值,当采样超过该阈值时,重新采样,以使得采样点落入阈值范围。减小该阈值会发现,GAN生成的图像多样性降低,质量提高。如下图所示,从左到右为逐渐降低阈值。

作者在此处将IS类比为precision,FID类比为recall,通过改变截断的阈值,做出FID-IS曲线如下。阈值减小,多样性下降,质量提高,IS对多样性并不敏感,而FID对多样性和质量都敏感。所以可以看到,最初FID会有提高,但当阈值越来越小时,模型多样性下降,FID急剧下降。
直接使用截断技巧对很多模型来说是有问题的,会导致saturation artifacts,如下图所示:

为解决这个问题,作者希望通过限制G变得更平滑来使得 z z z的全部空间能投射到好的输出样本上。作者尝试使用正交正则化,即直接应用正交条件:
R β ( W ) = β ∣ ∣ W T W − I ∣ ∣ F 2 R_\beta(W)=\beta||W^TW-I||_F^2 Rβ(W)=β∣∣WTW−I∣∣F2
其中 W W W是权值矩阵, β \beta β是超参数。但是这个正则化被认为太过于limiting,因此作者使用了该正则化的改进形式:
R β ( W ) = β ∣ ∣ W T W ⊙ ( 1 − I ) ∣ ∣ F 2 R_\beta(W)=\beta||W^TW\odot(1-I)||_F^2 Rβ(W)=β∣∣WTW⊙(1−I)∣∣F2
其中 1 1 1表示元素全为1的矩阵。
作者发现,不使用正交正则化,仅有16%的模型可以截断;使用正交正则化后,60%的模型可以被截断。
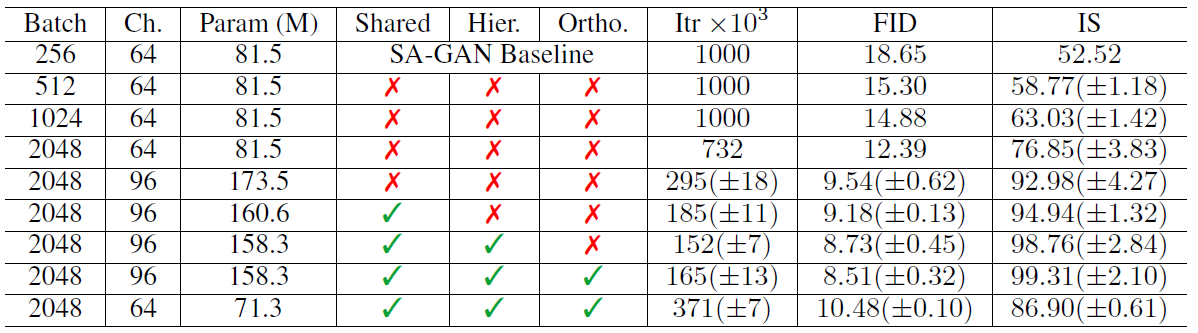
上述各种改进的效果对比如下表所示:
从左到右依次是Batch size,通道数,参数量,共享嵌入层,多层级潜在空间,正交正则,迭代次数,FID,IS分数。
Scaling导致的模型不稳定性分析
生成器G
鉴别器D
评价指标
常用评价指标,用来判断GAN生成的图片的质量好坏。下面给出其定义,计算方式以及代码。
Inception Score (IS)
最初在Improved Techniques for Training GANs (2016)一文中提出。将GAN生成的图像输出到Inception模型中,得到条件标签分布 p ( y ∣ x ) p(y|x) p(y∣x)。包含有意义目标的图像的 p ( y ∣ x ) p(y|x) p(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









