




 本文深入剖析HashMap在JDK1.7中的底层架构,包括数组加链表的实现、头插法、哈希算法、负载因子与resize方法。解释了为何使用0.75的负载因子以及头插法可能导致的问题,强调在并发环境下可能出现的数据安全性问题。
本文深入剖析HashMap在JDK1.7中的底层架构,包括数组加链表的实现、头插法、哈希算法、负载因子与resize方法。解释了为何使用0.75的负载因子以及头插法可能导致的问题,强调在并发环境下可能出现的数据安全性问题。
hashmap的1.7的底层架构
从jdk1.6和jdk1.7开始,hashmap的底层结构是数组加链表实现的 .将key的hash值进行取模获取index 既即将存放的元素的数组的位置.然后到对应的链表中进行put和get操作.
这里说明下为什么要加上链表.因为对数组进行取模的时候可能会遇到获取index的位置是一样的,所以可能会遇到hash碰撞冲突.此时
为了将元素存放进去,采用链表的方式进行存储数据,既在同一个index位置加了一个链表,该链表存放了若干个key的hash值取模后的index值一样的元素.然后在put和get的时候也通过取模获取index ,然后获取链表,再对链表进行遍历获取到链表中的某一个key值和原始的key值相同,则返回该值(这样不好,效率不高,每次都得遍历.时间复杂度为o(n),所以jdk1.8做了优化,下面会说.)
链表的原理
下面新建一个测试节点 第一次new一个链表, 然后next属性为空. 然后在加入新的节点的时候 将链表第一个节点既头结点的next属性指向新节点的对象.
header.next = new Node(new Object() ,null);
如果此时又加入一个节点.想将新的节点加在链表的头部,此时需要将新节点的next属性设置为原先头结点的对象然后赋值给头节点原先的对象.这样始终就保持头结点就是最新插入的数据.

jdk1.7 头插法.
Put的方法里面的这行代码table[index] = new Entry(key,value,table[index]); 就是上面头插法的一个方式
既在new一个entry节点的时候将老节点作为新节点的下一个节点.然后赋值给新节点.始终保证头结点的数据是新插入的数据.

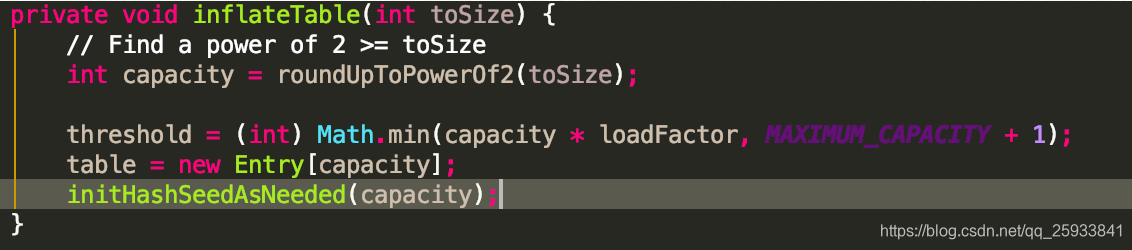
观察hashmap源码的put方法 thresold 就是传入数组的长度.不传的时候默认是16.

会发现当table为空的时候调用了inflateTable方法对map进行了初始化. roundUpToPowerOf2(toSize) 方法就是获取比size大的2的n次方的数返回. 既tosize为10 就返回16 tosize为5就返回8
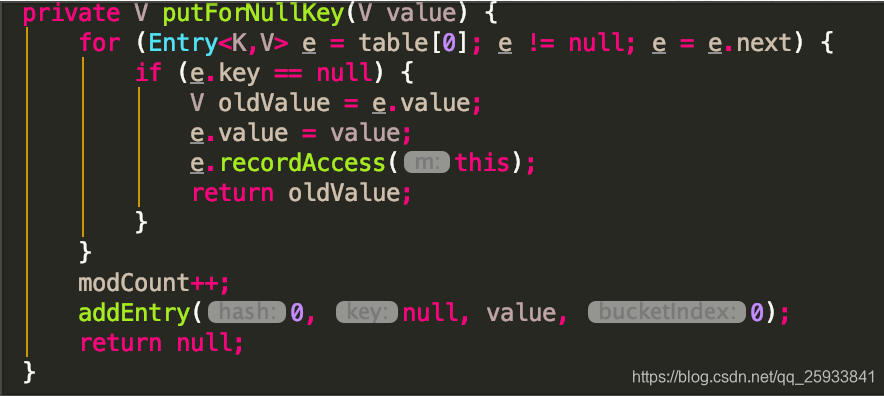
然后当key为null的时候会直接返回null的值回去. 具体方法为putForNullKey(key) 所以首先遍历table表的next链表.从头开始.获取到null的value后返回.这里的addEntry方法稍后解释.其实跟put方法的addEntry是一个道理.
好,继续走put方法.会获取到要存放的key的hash值.jdk1.7在这里做的操作的是这样的.依次解析
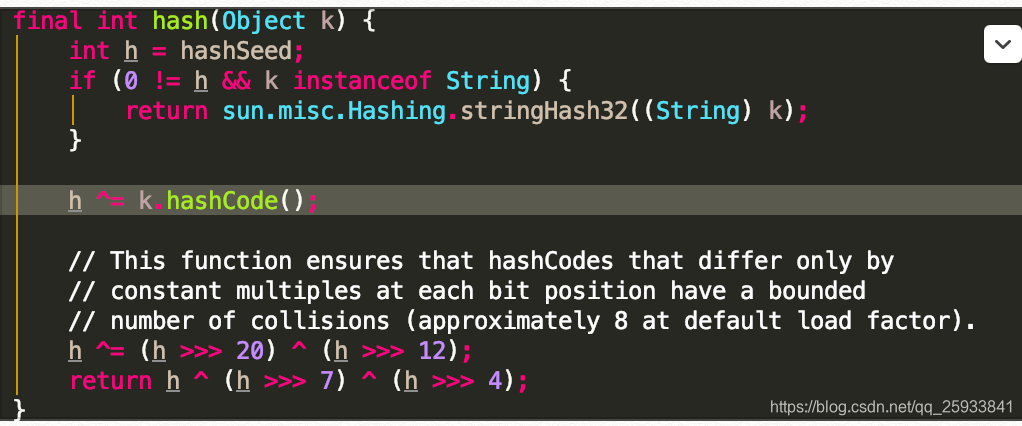
如果hashSeed哈希种子为0或非String对象的值 则将k的hashCode与h做异或操作. 其实在inflateTable方法就对哈希种子做了赋值.
最核心的点是下面的一个异或操作 此函数可确保在每个位位置仅恒定倍数变化的hashCode具有有限的冲突次数(默认情况下,加载次数约为8)
用了很多的异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
hash算法
继续走indexFor方法.该方法的目的就是为了通过hash值和数组长度获取一个比较均匀分布于数组和链表中的下标索引.尽量使每个数组位置都能分配到元素.这就是hash算法.
通过hash 与数组的长度进行数组下标索引的获取.获取方式很简单.hash值和length-1进行与操作. 本来通过hash值对数组长度进行取模也是可以获取同样的效果,但是模运算的效率比直接的二进制的位运算效率要更低.故采用了可以达到同样效果的与运算.

为什么数组的长度采用16比较合适呢.也就是2的n次方,这是因为16的减一后与hashcode进行与运算可以更好的减少hash碰撞.而对于其他的值.可能会让某一个位置产生位置冲突.
导致该位置的链表长度变长.所以当数组长度为2的n次方的时候,不同的key计算index的时候能够的让一个萝卜一个坑.查询效率比较高.
这也就是为什么jdk1.7的时候在存储大容量的时候,在初始化方法就预先指定了数组的容量.为大于指定数组长度的2的n次方作为实际数组的长度.(虽然你指定了 长度,但内部还是给你变为大于你指定的值的2的n次方的值了)
![]()
上面也有提到该方法.
哈希码相同则他们不一定相同,对象一致则哈希码一定相同
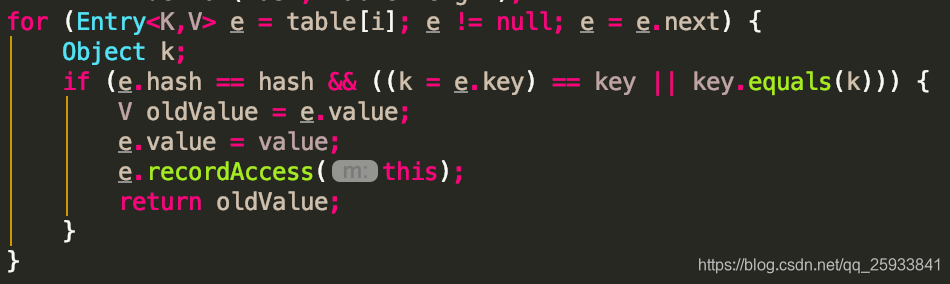
接下来走put方法的for循环,可见对table数组的next对应的entry对象进行了遍历. 然后if中判断是否是同一个hash 然后在判断key是否相同.
为什么要先判断hash呢?这是因为key的哈希码相同则他们不一定相同,key对象一致则哈希码一定相同.
Equals方法如果数据量大的时候比较过于频繁效率比较低.先比较hash值就可以过滤掉大部分数据.
,所以先进行hash的比较. 如果hash不相同,key直接就不用比较了.
接下来获取到相同情况下的老数据,一但获取到,证明该地方的key是有值的.将新传过来的值跟老值替换.然后返回老值…..所以put方法时如果key已经存在,这个时候返回的值是老值.而不是新值.
继续走put方法的

我们走到定义的位置,发现该字段有解释.翻译如下. 简而言之就是为了记录hashmap的结构修改的次数(rehash的次数).进行叠加.具体用处在hashmap中用不到,但是在其他地方用的到.跟一个异常有关系ConcurentModificationException.
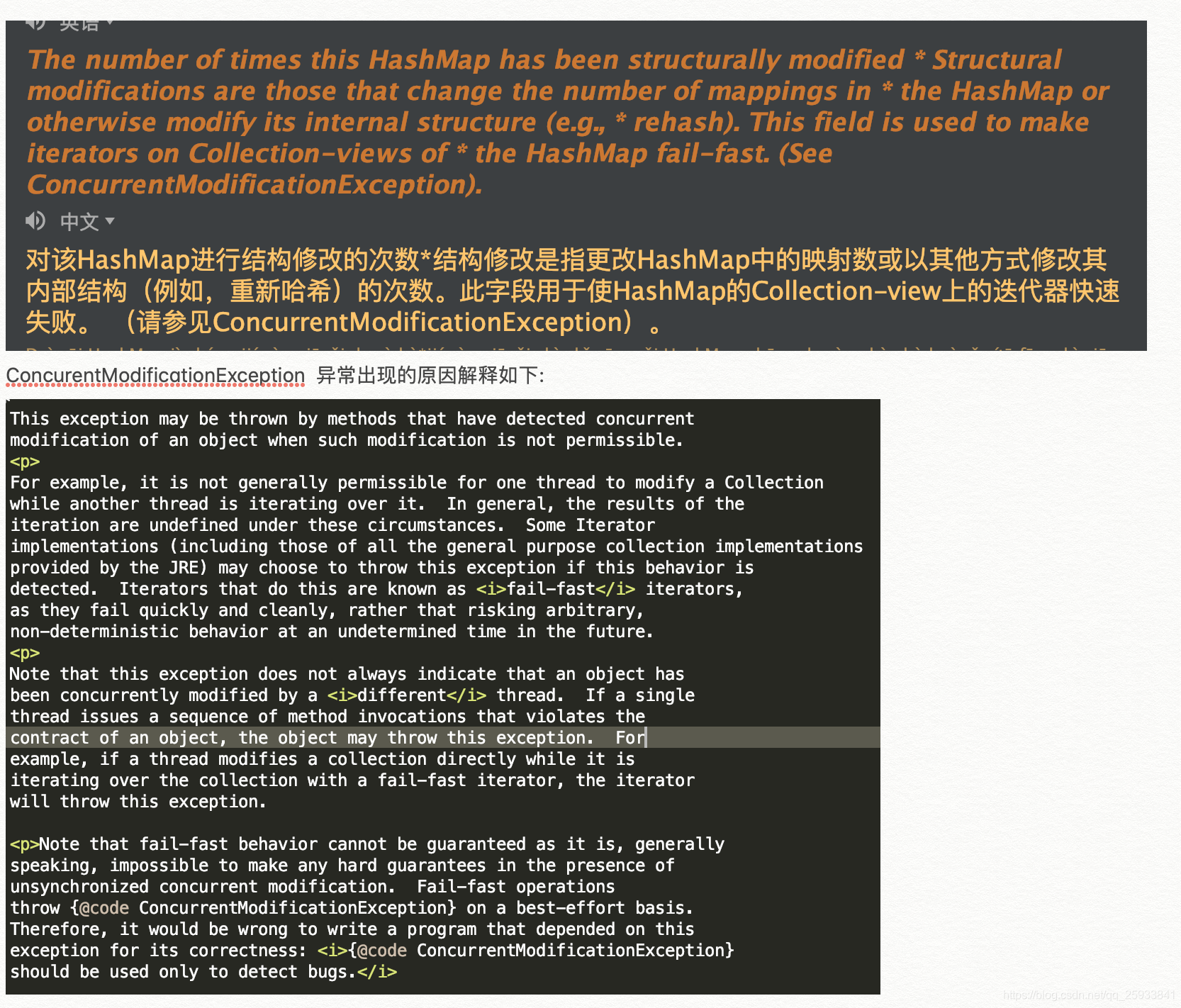
翻译:
当不允许对对象进行并发修改时,检测到该对象并发修改的方法可能会抛出该异常。 例如,通常不允许一个线程修改Collection ,而另一个线程对其进行迭代。通常,在这些情况下*迭代的结果是不确定的。如果*检测到此行为,则某些Iterator *实现(包括JRE提供的所有通用集合实现*的实现)可能会选择抛出此异常。这样做的迭代器称为<i> fail-fast </ i>迭代器,因为它们快速干净地失败,而不是冒着在不确定的将来冒任意,不确定行为的风险。 * <p> *请注意,此异常并不总是表示对象已被<i>不同</ i>线程同时修改。如果单个*线程发出违反对象*合同的方法调用序列,则该对象可能会抛出此异常。例如,如果线程在使用快速失败迭代器迭代集合时直接修改集合,则迭代器将抛出此异常。 * * <p>请注意,不能保证快速故障行为,通常来说,在存在*不同步的并发修改的情况下,不可能做出任何严格的保证。快速失败的操作*尽最大努力抛出{@code ConcurrentModificationException}。 *因此,编写依赖于此*异常的程序的错误性是错误的:<i> {@ code ConcurrentModificationException} *仅应用于检测错误。</ i>
所以该对象是为了并发情况下进行线程集合的迭代,对集合中的对象进行修改时抛出此异常.但是不能依赖此异常的程序进行操作其他业务逻辑.因为该异常抛出不能做出任何严格保证.尽最大努力抛出而已.
好,不纠结这个.
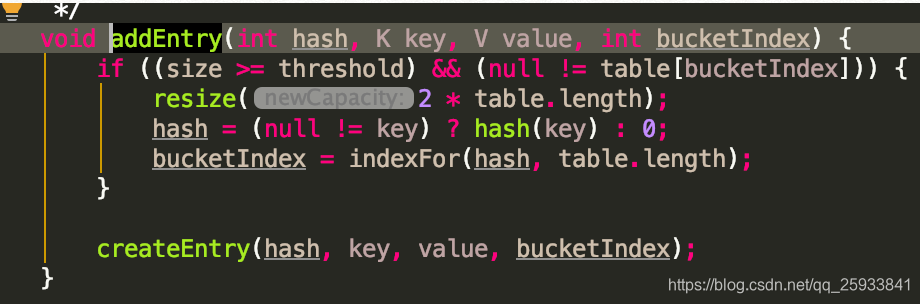
继续走put方法. addEntry方法.核心点.
![]()
我们走进该方法: 先看if方法中的判断,当数组容量大小大于通过负载因子0.75算出来的大小的时候.(既16的负载因子是12).并且该表的hash值对应的value不为null的时候.对数组进行扩容操作.
resize方法.
为什么负载因子的大小默认为0.75而不是1呢.
这涉及到一个数学运算.
根据HashMap的扩容机制,他会保证capacity的值永远都是2的幂。
那么,为了保证负载因子(loadFactor) * 容量(capacity)的结果是一个整数,这个值是0.75(3/4)比较合理,因为这个数和任何2的幂乘积结果都是整数。
Jdk官方文档有如下解释
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put).
翻译:一般来说,默认的负载因子(.75)在时间和空间成本之间提供了很好的权衡。更高的值减少了空间开销,但增加了查找成本(反映在HashMap类的大多数操作中,包括get和put)。
如果我们把负载因子设置成1,容量使用默认初始值16,那么表示一个HashMap需要在"满了"之后才会进行扩容,显然会发生更多的 hash碰撞.
resize方法
1.传入新的容量,
2.引用扩容前的数组.
3.获取数组的原始长度.如果原始长度就已经到达了2的32次方 ,修改阈值为2的32次方减一.以后就不会进行扩容了
4.新建一个新的entry数组.
5.传入transfer方法,对新书组进行了扩容操作.
6.将新书组赋值给全局table.
7.修改新的阈值.
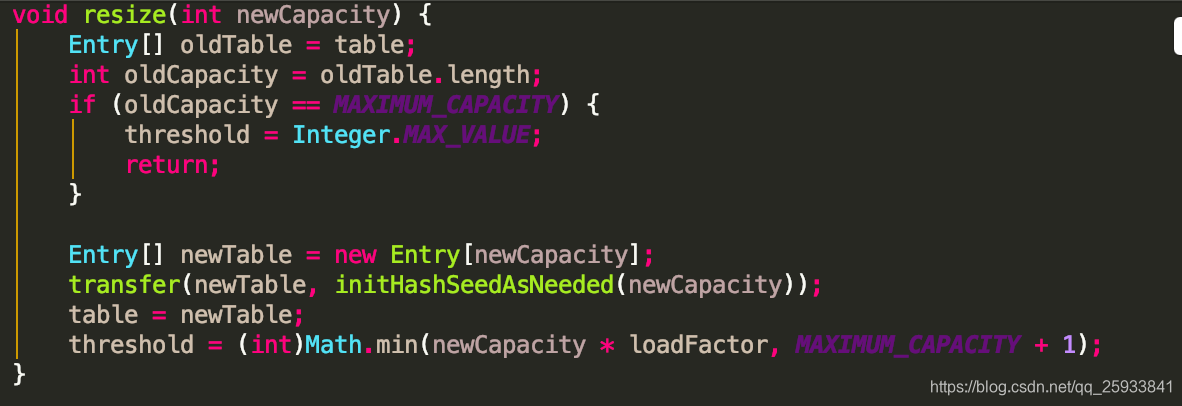
将此映射的内容重新映射到容量更大的新数组中。当此映射中的键数达到其阈值时,将自动调用此方法
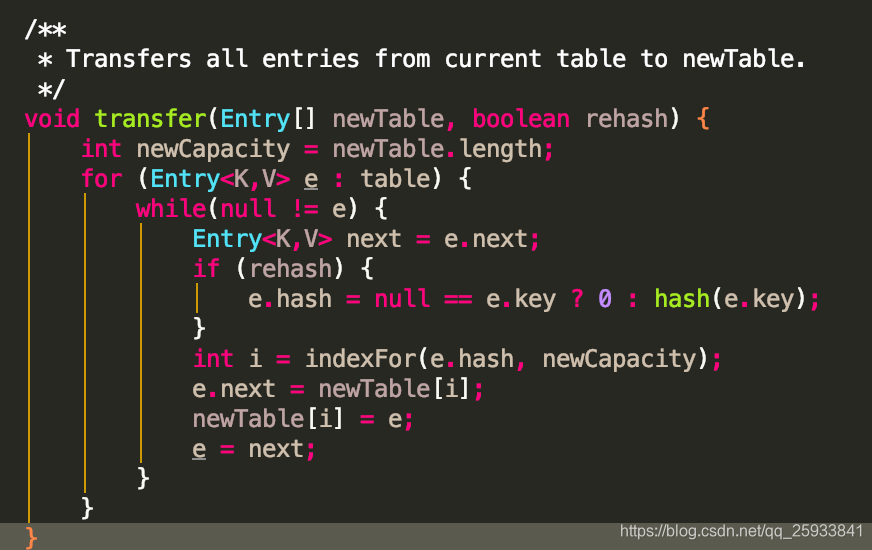
我们着重看transfer方法.
1.首先对原数组for遍历,
2.然后内部再此进行while循环. 只要不为null,就一直遍历.
3..保存下一次循环的entry节点对象. Entry<K,V> next = e.next;
4.如果rehash为true,就通过e的key值计算e的新hash值.
5.然后通过indexFor方法,将hash值和新的容量减一获取e的新下标.
6. e.next = newTable[i]; newTable[i] = e; 采用头插法将新表的i对应的老的entry节点赋值为next属性,然后e插入到i对应的位置成为新的头节点..
7.e=next; 将next节点既下一次要循环的节点赋值给e.开始新一轮的从1到7.直到e的值为null.既链表循环结束.
这里存在的问题.
首先for循环的数组如果数据很大.执行到Entry<K,V> next = e.next; 之后,既next的指针已经被记录,并在最后指向了下一次要循环的e.
突然.被阻塞.另一个线程过来.对同一个e对象进行了赋值.此时进行1到7步的操作.链表的数据都被插入到了新的索引下标.并且头插法将数据由原来的顺序变为倒序.
而原始指向的e.next对象已经有原来的头节点变为了尾节点.此时继续走1到7步.会产生原来的头结点和尾节点相互next指向.既发生死锁. 既自旋操作.
既有可能在下次get的时候出现死循环的问题.
因为没有加锁,所以在多个线程并发的时候,不能保证数据是安全的.就是我put进去的一个值,不能保证我get的时候还是原来的值.

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









