 Linux中vmalloc的实现解析
Linux中vmalloc的实现解析








1.作用
vmalloc用于在内核中分配物理不连续、虚拟连续的内存空间。在虚拟空间中,通过vmalloc申请的内存都在vmalloc区。

2.函数说明
void * vmalloc(unsigned long size);
- size:要申请的内存的大小
- 返回:申请到的内存的虚拟地址。
3.代码实现
vmalloc定义在include/linux/vmalloc.h中:
![]()
调用栈:

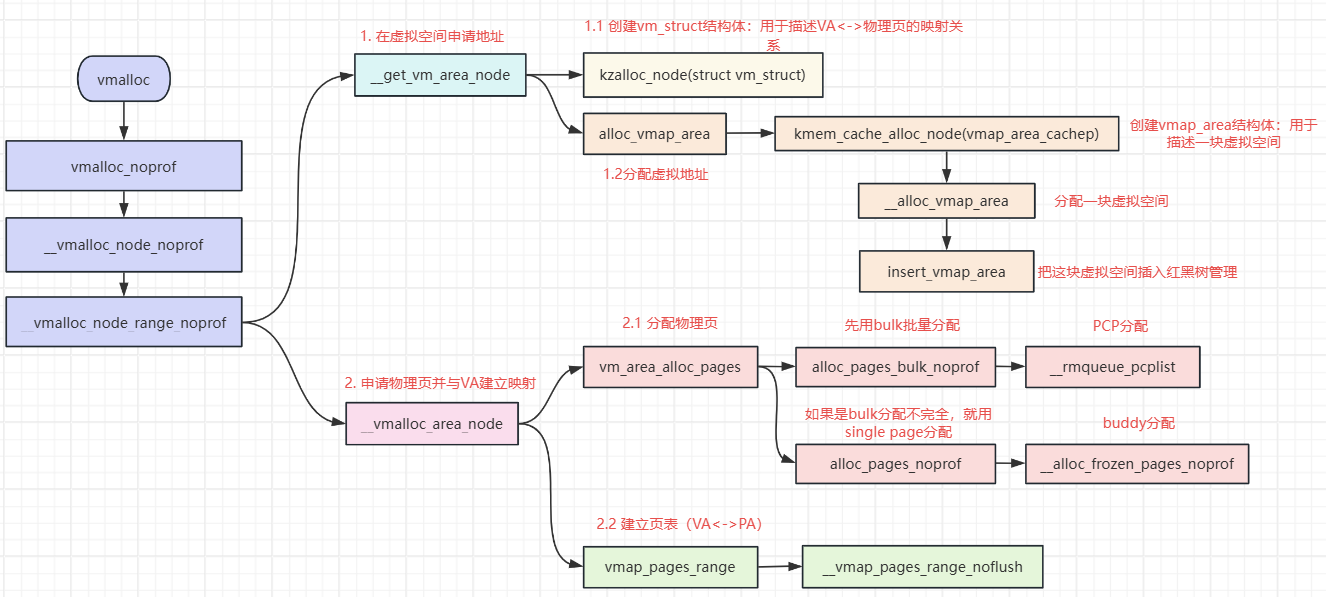
1. __vmalloc_node_range_noprof
定义在mm/vmalloc.c:

参数说明:
- size: 分配大小
- align: 期望的对齐方式,调用时填了1。
- start: 虚拟空间范围的起始地址。这里填了0xffffc90000000000,也就是虚拟空间vmalloc区域的起始地址。
- end: 虚拟空间范围的结束地址。这里填了0xffffe8ffffffffff = vmalloc区域的结束地址。
- gfp_mask: 这里填了GFP_KERNEL,从内核空间分配。
- prot: 分配page的保护页码,这里填了PAGE_KERNEL。
- vm_flags:额外的虚拟空间flag,这里填0表示没有。
- node:指定从哪个NUMA node分配,指定NUMA_NO_NODE,表示不指定。
- caller:调用者的函数指针,这里填的是调用vmalloc的那个函数的指针。
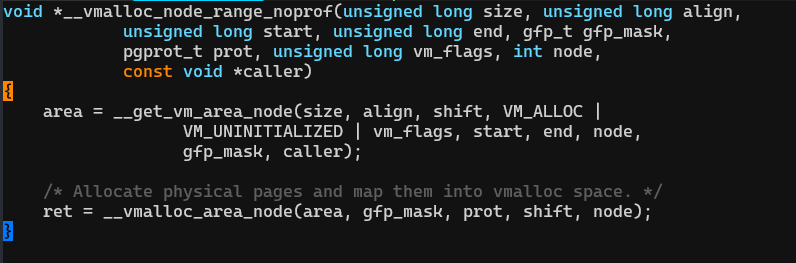
(1)通过__get_vm_area_node从vmalloc区域得到一段可用的虚拟地址。
VM_ALLOC表示是用vmalloc函数分配,ioremp也会调用这个函数,ioremp的标志是VM_IOREMAP。
VM_UNLIST表示vm_struct不在vmlist全局链表中(不懂)
(2)一页一页的分配物理页,并建立虚拟地址和物理地址之间的映射。创建并更新内核页表。
2. __get_vm_area_node:在虚拟空间的vmalloc区域寻找可用的虚拟地址
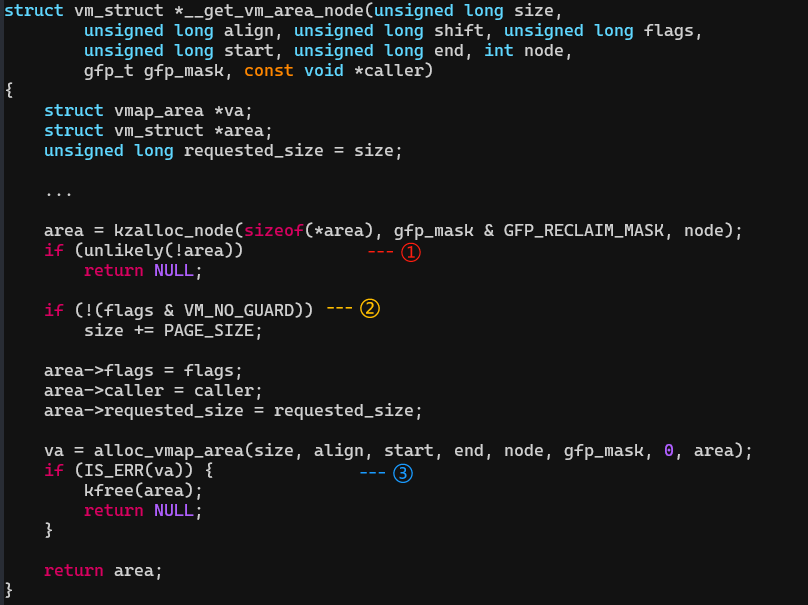
(1)用kmalloc分配一个struct vm_struct 结构体。
(2)分配一个guard page作为安全间隙.
(3)调用 kmalloc 分配 struct vmap_area 结构体,并将struct vmap_area 结构体添加到红黑树和链表中。
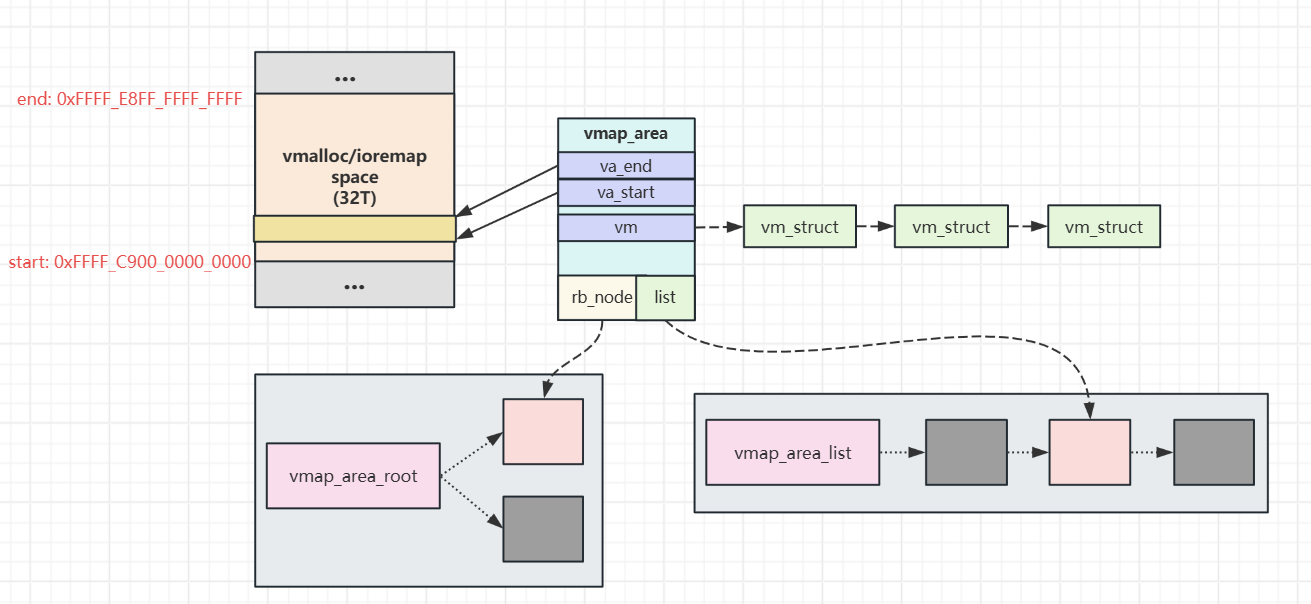
这里需要展开讲讲这两个结构体,内核通过这两个结构体描述一段虚拟空间以及这段虚拟空间到物理空间的映射。
定义在include/linux/vmalloc.h中:
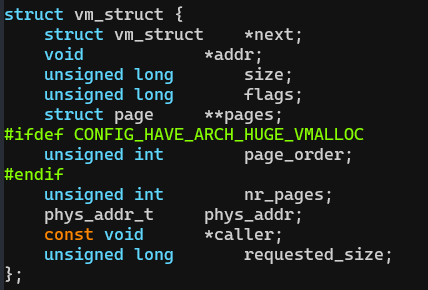
struct vm_struct:用于管理VA和PA之间的映射关系
struct vmap_area:用于描述一段虚拟地址的区域
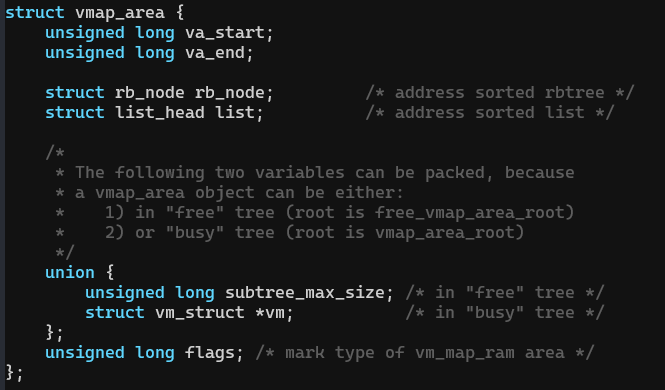
- 这个虚拟地址开始于va_start,结束于va_end。
- vm是一个struct vm_struct结构的链表,因为这段VA对应的PA可能不连续,所以需要多个struct vm_struct来描述各段PA到VA的映射。
- 通过rb_node把这个结构挂载红黑树上。由于内核会频繁的进行vmap_area的查找,红黑树的引入就是为了解决当查找数量非常多时效率低下的问题,在红黑树中,搜索元素,插入,删除等操作,都会变得非常高效。知道它的用途即可这里不再深入。
- 通过list把所有struct vmap_area连接在一起。
这个数据结构总结为:
alloc_vmap_area
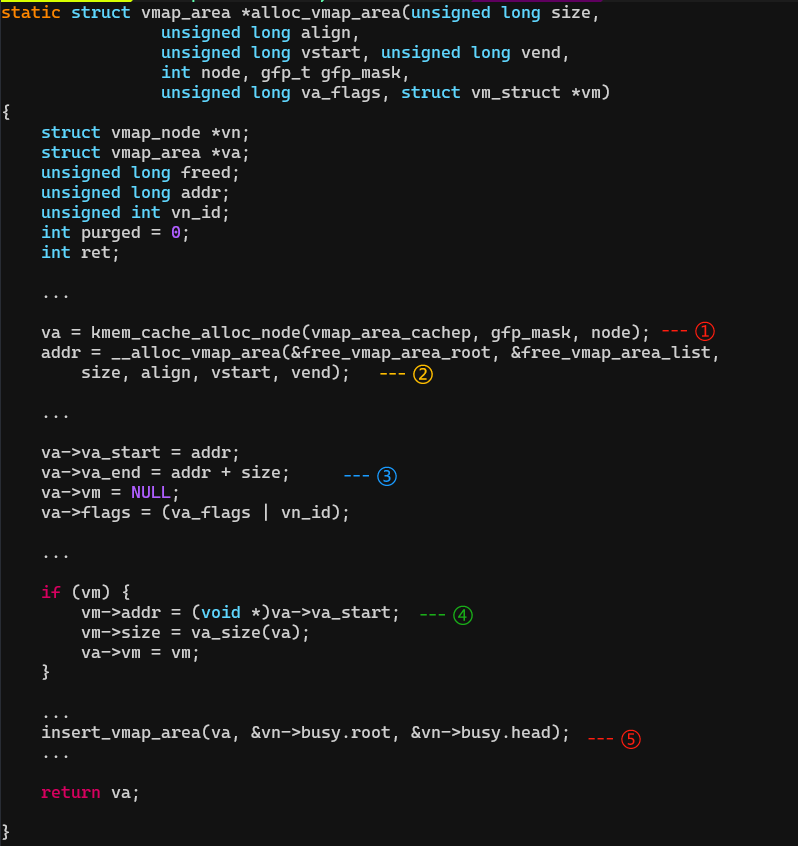
(1)从slab分配一个struct vmap_area。
(2)从虚拟空间的vmalloc区申请一块可用的虚存(查找红黑树),返回这块虚存的起始VA:addr。
查找的过程就不细说,大致描述一下:
从VMALLOC_START开始,从vmap_area_root这棵红黑树上查找,这个红黑树里存放着系统中所有正在使用的vmalloc区块。遍历左子叶节点找区间地址最小的区块。如果区块的开始地址等于VMALLOC_START,说明这区块是第一块vmalloc区域。
如果红黑树没有一个节点,说明整个vmalloc区间都是空的。
查找每个存在的vmalloc区块的缝隙hole能否容纳目前要分配内存的大小。
如果在已有vmalloc区块的缝隙中没能找到合适的hole。那么从最后一块vmalloc区块的结束地址开始一个新的vmalloc区域。
(3)填充vmap_area。
(4)并把vm_struct和vmap_area关联起来。
(5)把vmap_area插入红黑树。
3. __vmalloc_area_node:为VA一页一页分配PA
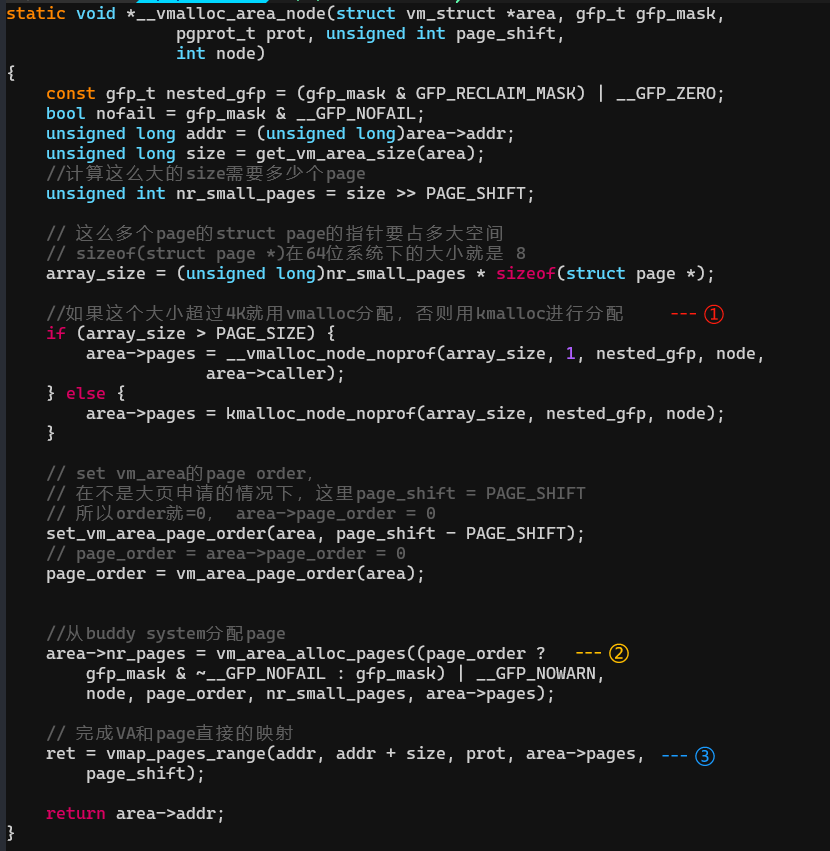
(1)根据size计算一共需要申请多少page,申请一块内存存放这些page的struct page指针,为了把这些page链接起来。
(2)计算好order以后,调用vm_area_alloc_pages从buddy分配page。
(3)调用vmap_pages_range建立物理page<->VA的映射。
4. vm_area_alloc_pages:从buddy申请page
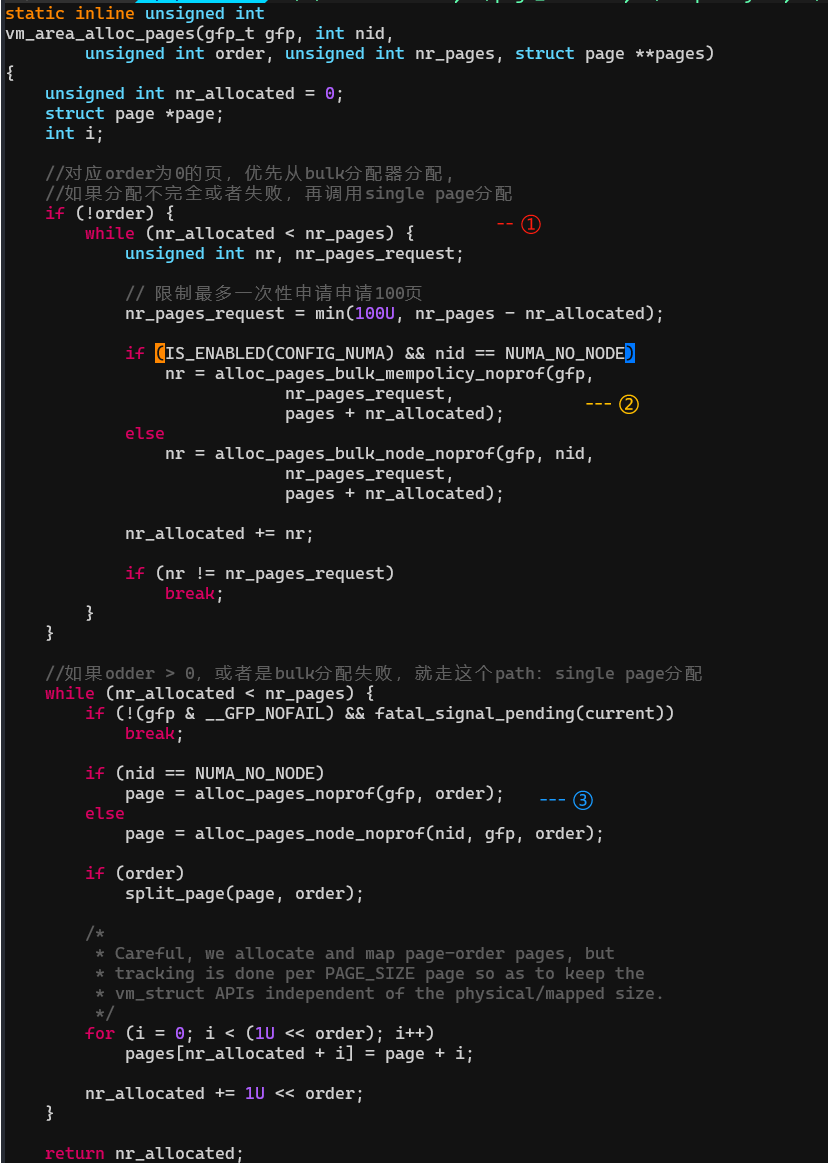
(1)如果order是0,优先使用bulk分配。order > 0或者bulk分配(只从PCP里尝试分配)失败再使用single page分配(尝试完整的buddy分配:先PCP,后buddy)
(2)如果没有指定node分配的话,不会默认选择从最近的node分配。而是会依据mempolicy的模式,选择分配方式。
调用alloc_pages_bulk_mempolicy_noprof,根据mempolicy->mode选择分配的方式。
如果mempolicy->mode是MPOL_INTERLEAVE,就从不同的node交替分配等等。
调用栈:
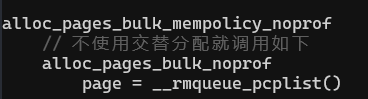
__alloc_pages_bulk就是Bulk分配的api,定义在 mm/page_alloc.c中。它会根据入参选择合适的node的zone的pcp_listd的order 0的migratetype的page list。调用__rmqueue_pcplist从该pcp_list中尽可能多的申请page(假如要申请16页,申请不到16页,也不算失败,把实际申请到的page和实际的数量返回),最后把page放入page_array中,返回申请到的page数量。
(3)single page分配,调用栈:

最后就调到了buddy 的核心分配函数:__alloc_frozen_pages_noprof
5. vmap_pages_range:VA和物理page建立映射
为了解决内核空间同步问题,Linux 并不是直接对当前进程的内核空间映射的,而是对 init 进程的内核空间(init_mm)进行映射。
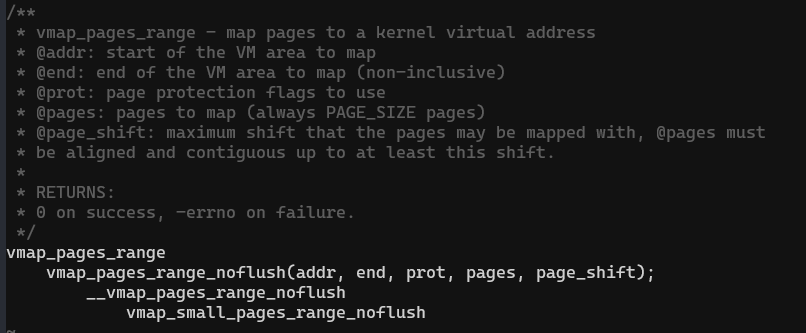
vmap_small_pages_range_noflush
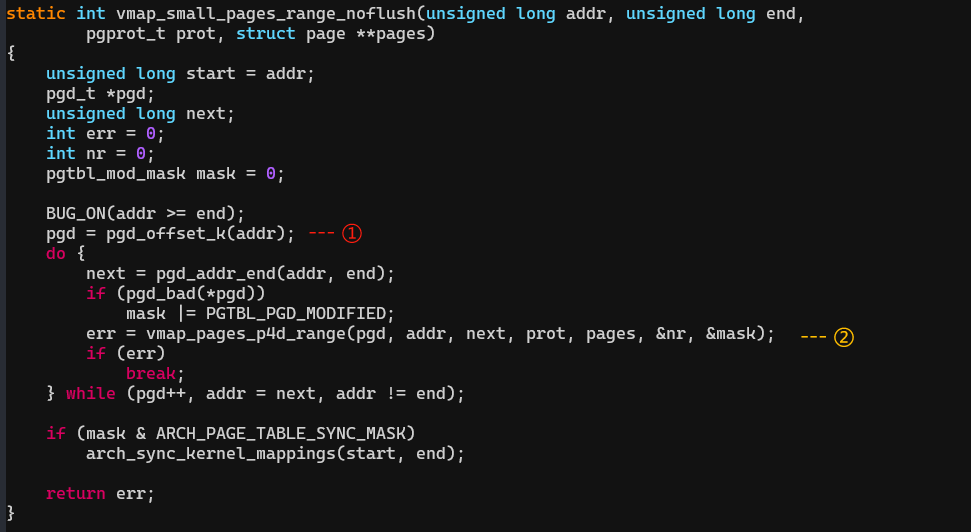
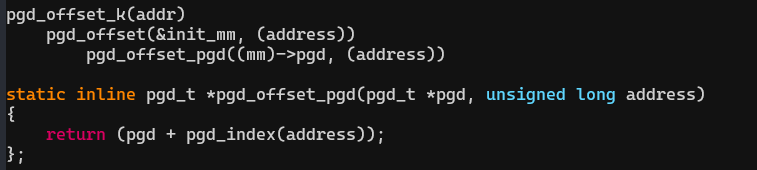
(1)从init_mm中找到内核的pgd,根据VA计算它所在的entry。
(2)然后page table walk找到这段addr对应的pte的entry,把对应的物理page的pfn填入pte的entry里。
在x86 64位系统中,内核页表和进程的页表是不同的pgd。内核初始化时创建全局页表 swapper_pg_dir(init_mm)。当新进程创建时(如 fork()),其页表(mm_struct->pgd)的 用户空间部分 从父进程复制(COW),而 内核空间部分 直接指向 swapper_pg_dir 的对应项因为映射的 init 进程的内存空间,从而进行了内核全局页表的共享。
而32位系统中内存4G,一个pgd可覆盖,在fork新进程的时候把内核全局页表 swapper_pg_dir的内核部分copy到进程的pgd。

vmalloc时把这块内存的页表写到了init_mm中,所以当前进程访问这块内存时,由于没有对VA进行映射,所以会发生缺页异常 而触发内核调用 do_page_fault():把 init 进程的页表项复制到当前进程的页表项中。
6. do_page_fault()
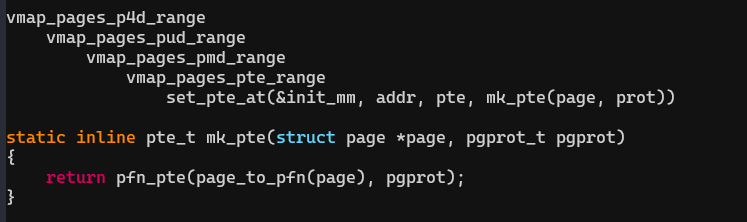
大多是架构跳转到do_page_fault(),而 x86 中断处理程序是由DEFINE_IDTENTRY_RAW_ERRORCODE 宏定义的,该宏调用 handle_page_fault,定义在arch/x86/mm/fault.c。
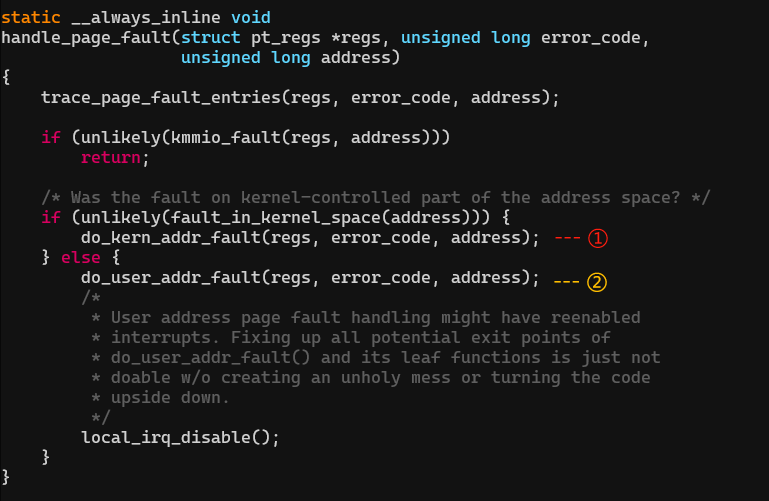
调用①处理内核空间的page fault,调用②解决用户空间的page fault。如果是32位系统,do_kern_addr_fault调用vmalloc_fault解决vmalloc映射空间的page fault。
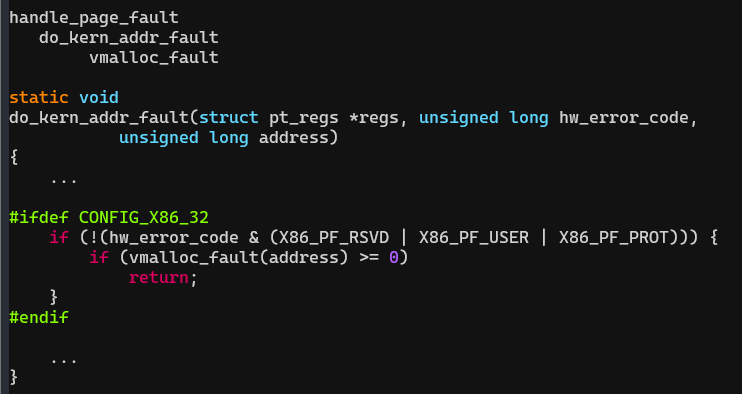
vmalloc_fault
主要的过程就是把 init 进程的页表项复制到当前进程的页表项中,这样就可以实现所有进程的内核内存地址空间同步。
定义在arch/x86/mm/fault.c中
https://zhuanlan.zhihu.com/p/502693077
总结:
vmalloc的分配过程为:
vfree


















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









