




 本文介绍了使用卷积网络从单张图像中预测离焦距离的快速自动对焦方法,探讨了空间域、频域、自相关特征及其组合对预测的影响。实验表明,对于不同照明条件,多域网络能有效提高自动对焦的准确性。
本文介绍了使用卷积网络从单张图像中预测离焦距离的快速自动对焦方法,探讨了空间域、频域、自相关特征及其组合对预测的影响。实验表明,对于不同照明条件,多域网络能有效提高自动对焦的准确性。
论文:Transform- and multi-domain deep learning for single-frame rapid autofocusing in whole slide imaging
作者的快速聚焦方法是使用卷积网络从单个成像图片中预测图片的离焦距。之前的聚焦方法大多需要测量多张成像图片的聚焦值来预测聚焦镜头的移动方向和移动距离,但是论文的方法可以直接预测出聚焦位置的方向和距离。
作者使用不同的图片特征,包括图片的空间域特征、频域特征、自相关特征及其组合。作者探讨这几种特征对预测图片的离焦距的影响。虽然不同的离焦距导致成像图片不同的空间特征,但是仅仅依赖空间特征会对聚焦过程产生不好的表现。因此,最好从其他域中(比如频域)提取离焦特征。论文的实验把载玻片成像系统关照条件分成3种:incoherent Kohler illumination, partially coherent illumination with two plane waves, and one-plane-wave illumination。大多数情况下都是使用第一种关照条件。对于incoherent illumination,傅里叶阶段频率直接与离焦距相关联。类似地,自相关峰值与双平面波照射的离焦距直接相关。
Archiecture
作者使用的网络架构是ResNet:
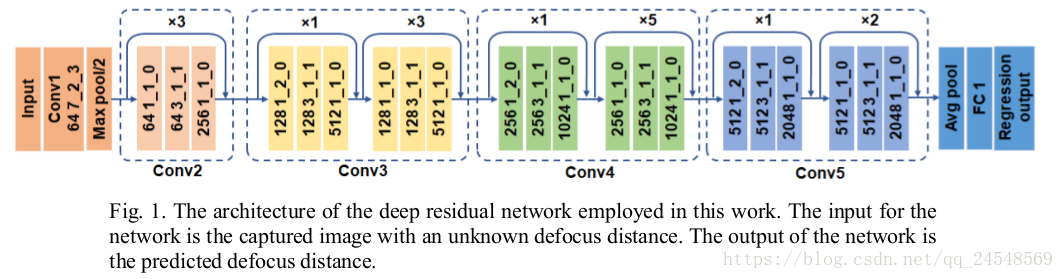
Trainset
作者从一次聚焦过程中采集一组图片,在离聚焦位置的-10μm到+10μm的范围内每隔0.5μm抓取一张图片,共41张成像图片,一些训练样本如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









