




 本文探讨了Seq2Seq模型及其局限性,特别是在翻译任务中无法灵活处理不同部分的源语句信息。为解决此问题,引入了Attention机制,使模型在翻译过程中能够对源语句的不同部分赋予不同的权重,从而提高翻译质量。
本文探讨了Seq2Seq模型及其局限性,特别是在翻译任务中无法灵活处理不同部分的源语句信息。为解决此问题,引入了Attention机制,使模型在翻译过程中能够对源语句的不同部分赋予不同的权重,从而提高翻译质量。
https://zhuanlan.zhihu.com/p/37290775 参考了这篇知乎。
Seq2Seq,即通过Encoder将输入语句进行编码得到固定长度的Context Vector向量,(这个编码过程实际上是一个信息有损压缩的过程,也就是说编码器里所有的信息都要压缩在一个Context Vector中),随后再将Context Vector传给Decoder进行翻译结果的生成,在Decoder端生成每个单词时,均参考来自Encoder端相同的Context Vector。
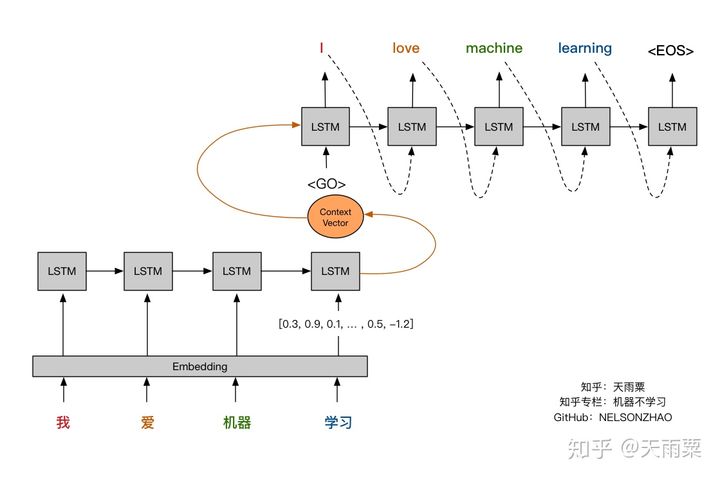
这种方式相对不够灵活,具体而言,当我们在翻译“机器学习”这的词的时候,并不关心这个词组前面的“我”和“爱”这两个字;而在翻译“我”的时候,也不关心“机器学习”这个词组。因此,一种更好的方式就是引入Attention机制,给予当前待翻译的词更多的权重,使得我们翻译每个词时会对源语句有不同的侧重,如下图所示。
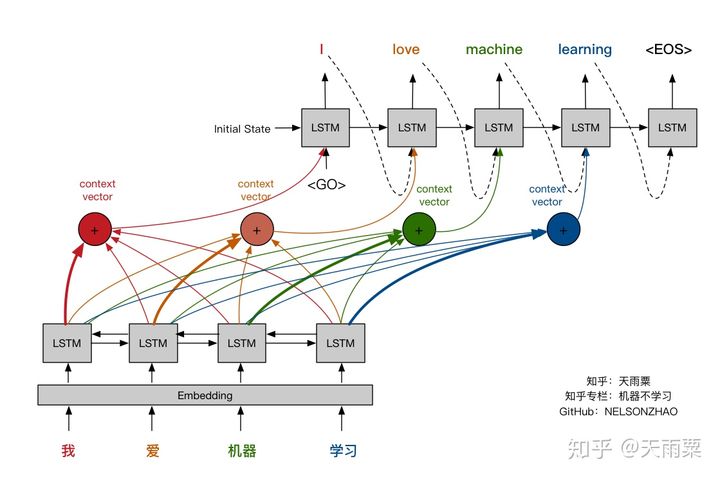

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









