







 本文深入探讨了注意力机制,包括自注意力和多头自注意力在Transformer模型中的应用。自注意力允许模型关注输入序列的不同部分,而多头自注意力则通过在多个子空间中并行处理信息来增强这种能力。Transformer利用这些机制进行序列建模,适用于自然语言处理任务。此外,还介绍了如何通过softmax和归一化来计算注意力权重,并分析了不同类型的注意力机制之间的区别。
本文深入探讨了注意力机制,包括自注意力和多头自注意力在Transformer模型中的应用。自注意力允许模型关注输入序列的不同部分,而多头自注意力则通过在多个子空间中并行处理信息来增强这种能力。Transformer利用这些机制进行序列建模,适用于自然语言处理任务。此外,还介绍了如何通过softmax和归一化来计算注意力权重,并分析了不同类型的注意力机制之间的区别。
目录
Attention 和 Self-Attention 的区别
多头自注意力机制multi-head self-attention
-
什么是注意力机制
10 Transformer 之 Self-Attention(自注意力机制)_哔哩哔哩_bilibili
对于不同模块/部分,重要的信息可能不一样,怎么聚焦在更重要的信息上。
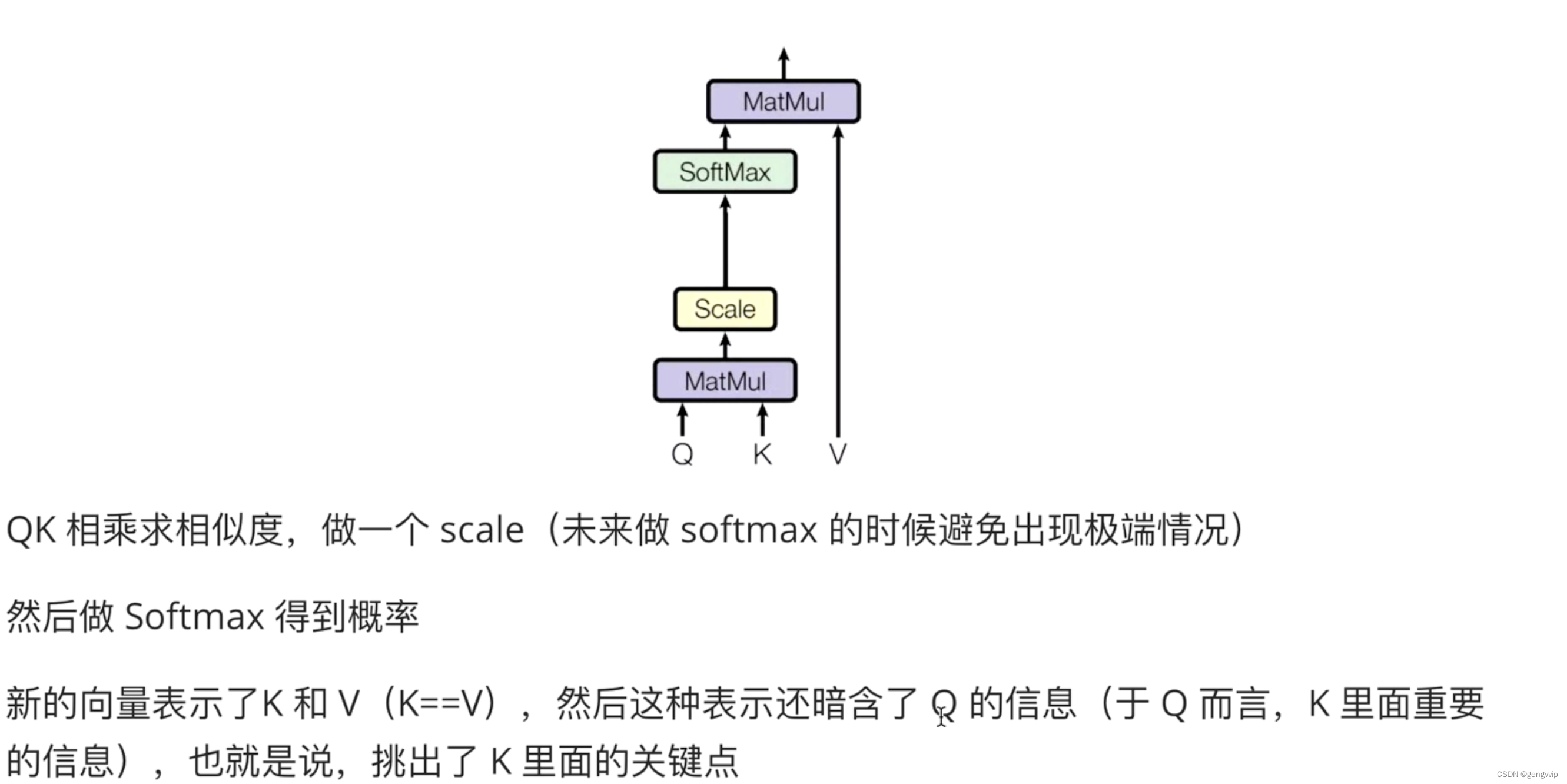
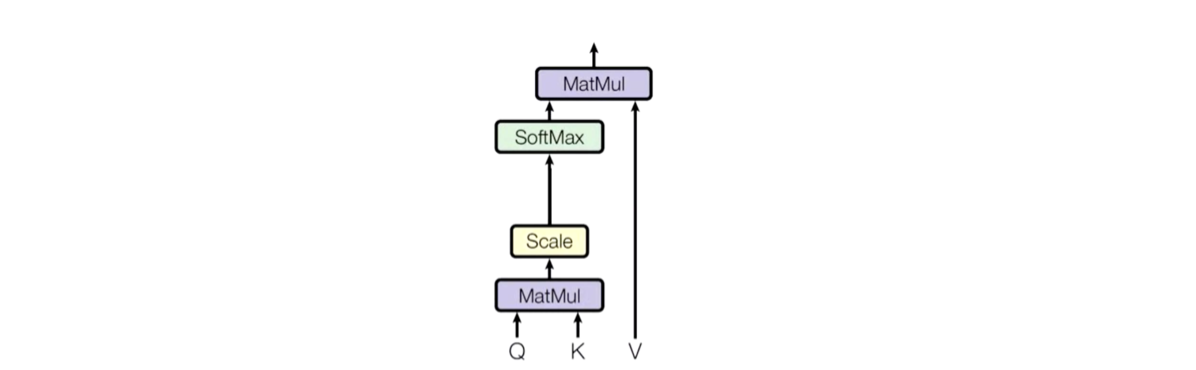
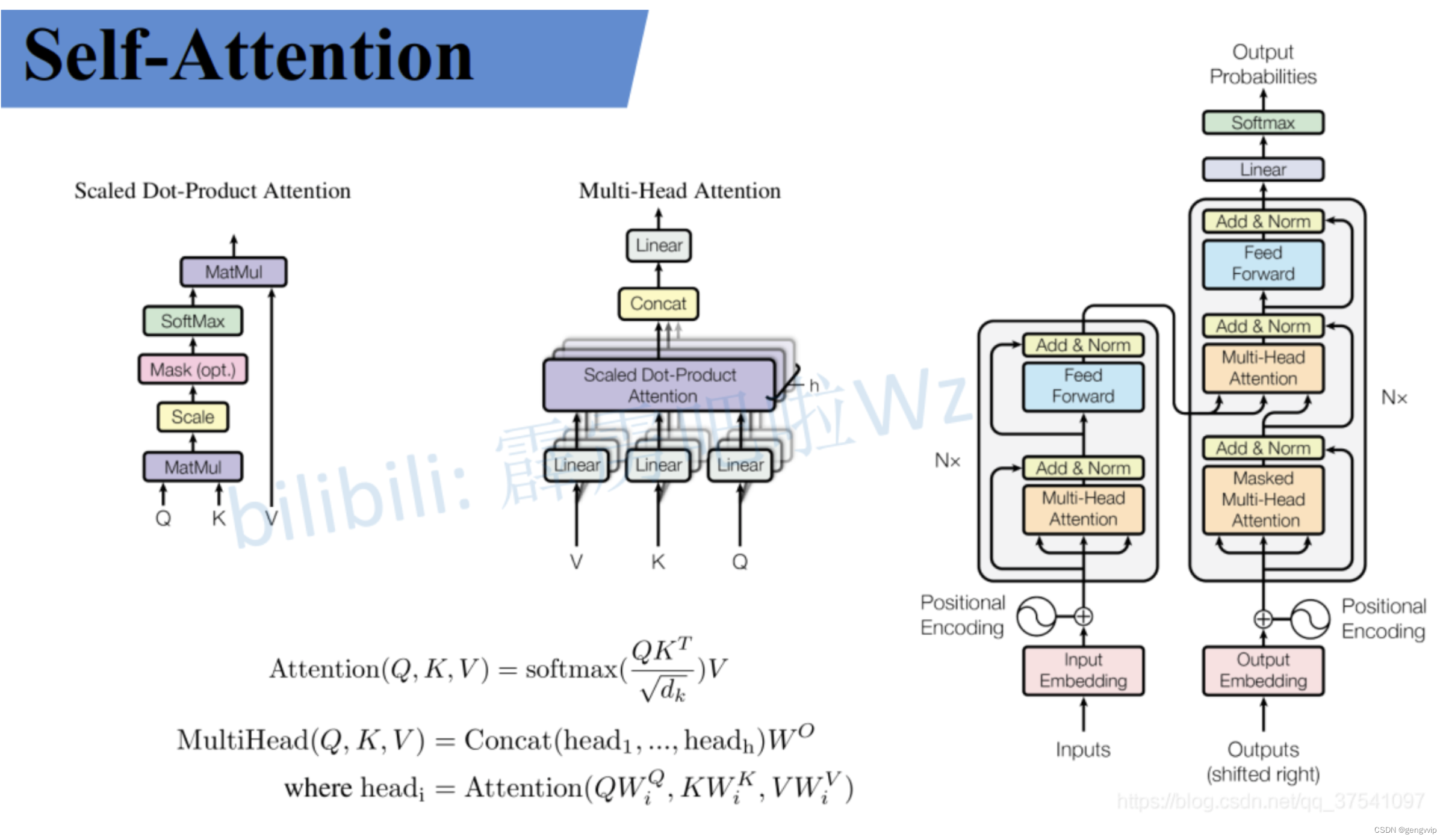
attention通常可以进行如下描述,表示为将Q和k-v pair(把Value拆分成了键值对的形式)映射到输出上。分为三个步骤:
-
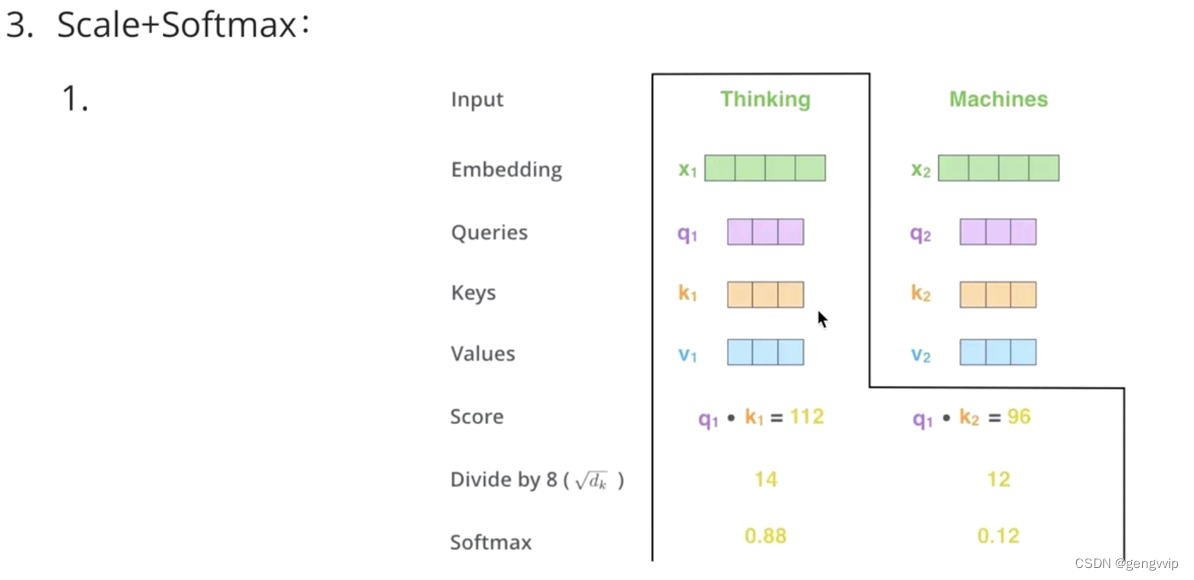
Q,K=k1,k2,...,kn 内积/点乘的方式,计算相似度a1,a2,...an。
-
做一个scale归一化,避免出现极端情况;做一层softmax,得到概率/注意力值,表示重要性
-
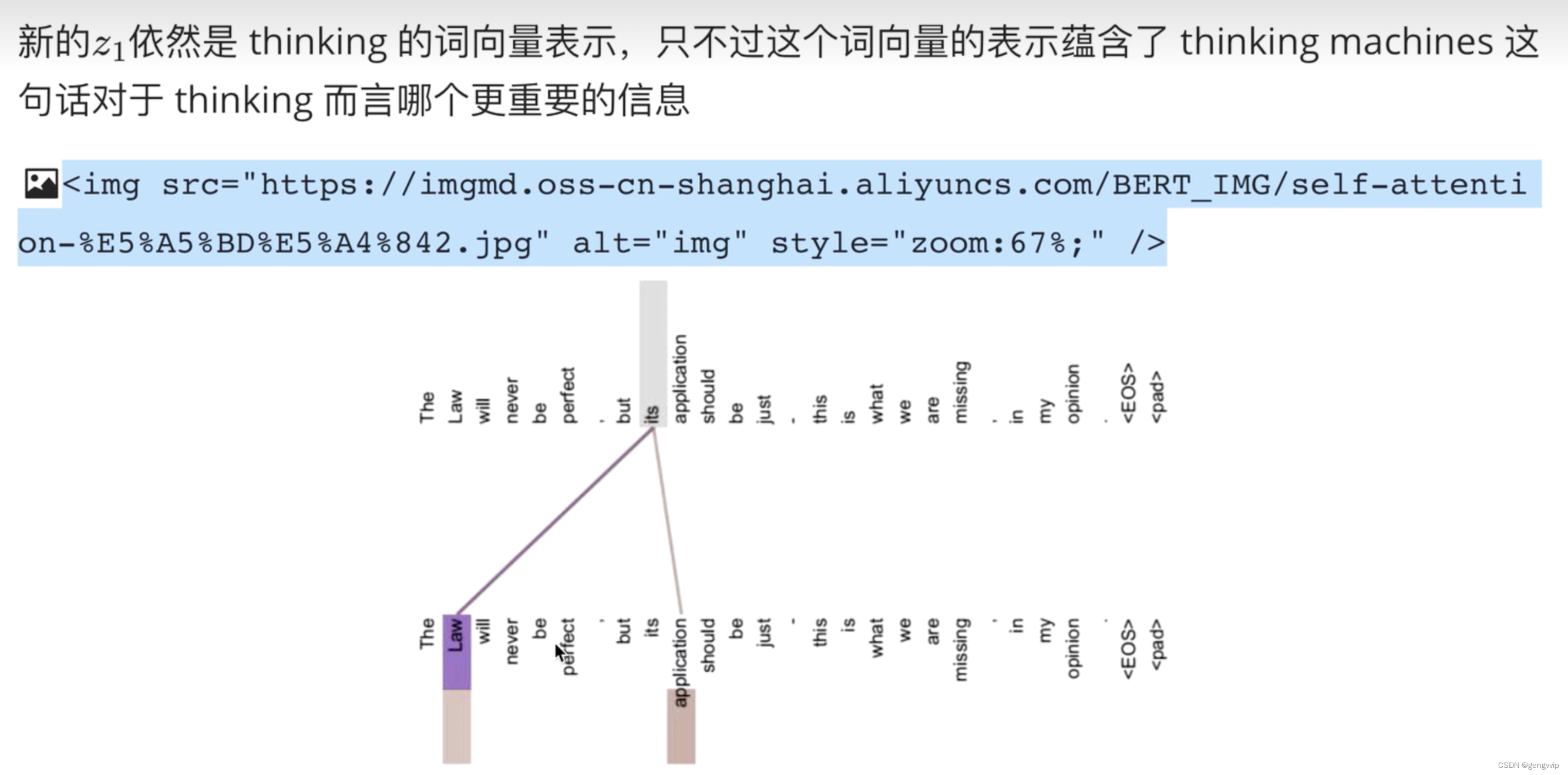
最后进行汇总,使用Q查询之后,Q已经失去了使用加值,最终还是要拿到最终输出,跟v点乘,得到最终输出(包含了哪些重要、不重要),最终的新向量表示,只不过蕴含了整个特征列表对于当前特征而言哪个更重要的信息。每一个单词都会包含整个句子中各个单词的重要性信息。
一般K=V,在transformer里面,K和V一定具有某种联系,这样QK点乘才能指导V哪些重要,哪些不重要。
-
自注意力机制self-attention
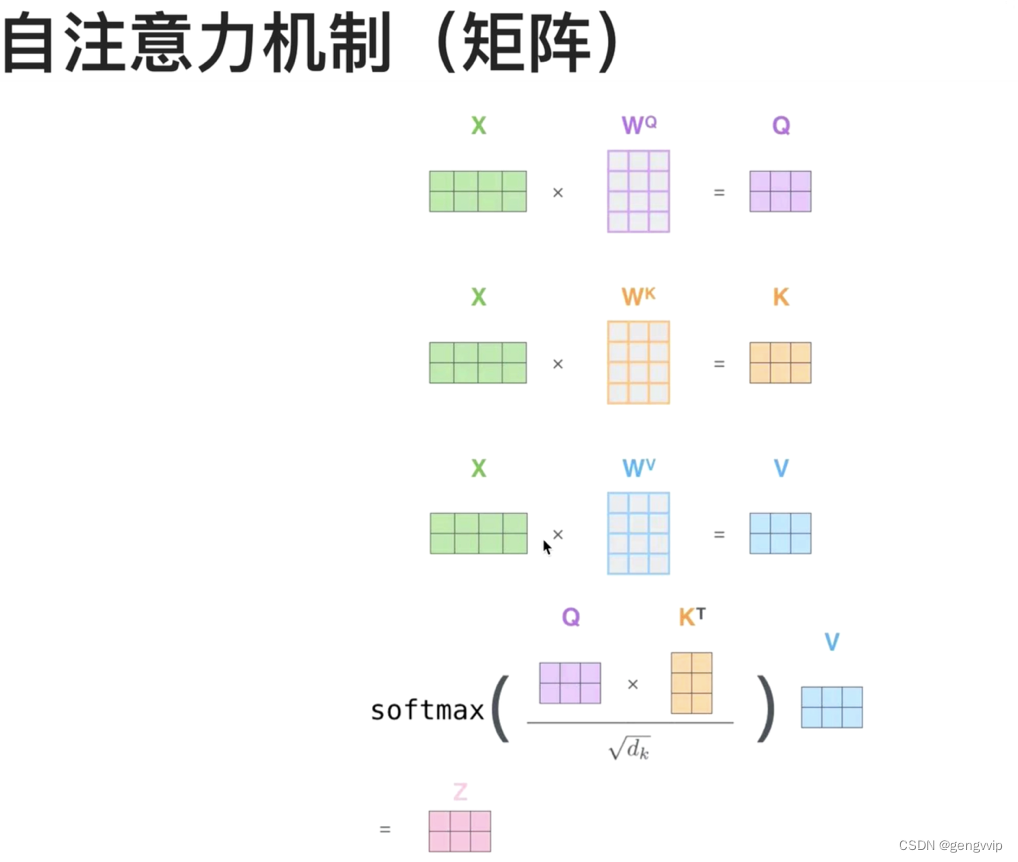
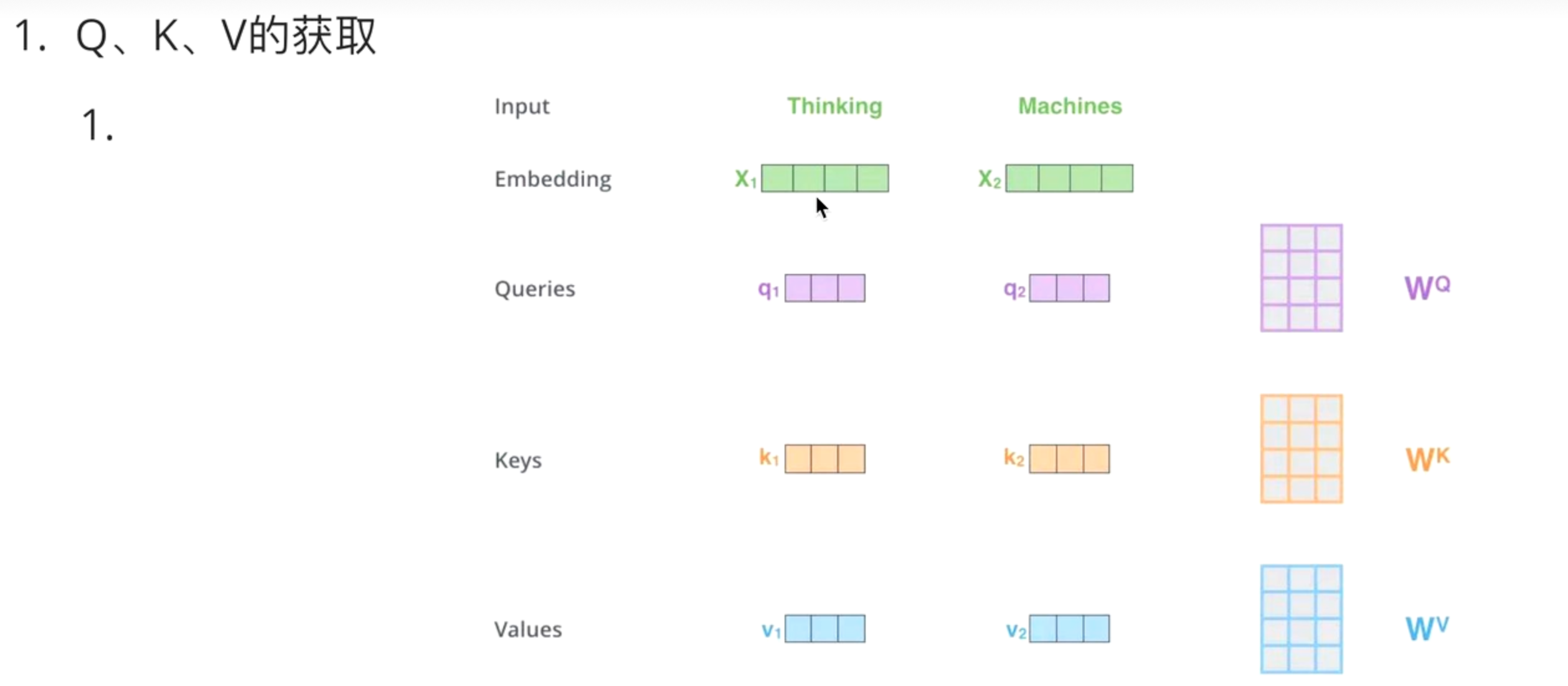
K$approx$=V=Q,来源于同一个X,三者同源。
QKV,是X通过一个矩阵的线性变换,分别得到的中间表示。


-
Attention 和 Self-Attention 的区别
attention没有规定QKV 怎么来,只规定QKV怎么做。
self-attention规定了,QKV必须要同源,来源于同一个输入源的空间上的线性变换/矩阵计算。对于一个词向量(不一定准确),做的是空间上的对应,乘了参数矩阵,依然代表X。
-
交叉注意力机制:QK不同源,但是KV同源
-
cyd注意力机制:QV同源,QK不同源
-
其他:Q必须为1,KV不同源
重点是跟其他特征的交叉
多头自注意力机制multi-head self-attention
详解Transformer中Self-Attention以及Multi-Head Attention_太阳花的小绿豆的博客-优快云博客
机器学习
机器学习的本质是什么:y=Q(wx+b),在做一件什么事情,非线性变换(把一个看起来不合理的东西,通过某个手段(训练模型),让这个东西变得合理)
非线性变换的本质又是什么?改变空间上的位置坐标,任何一个点都可以在维度空间上找到,通过某个手段,让一个不合理的点(位置不合理),变得合理
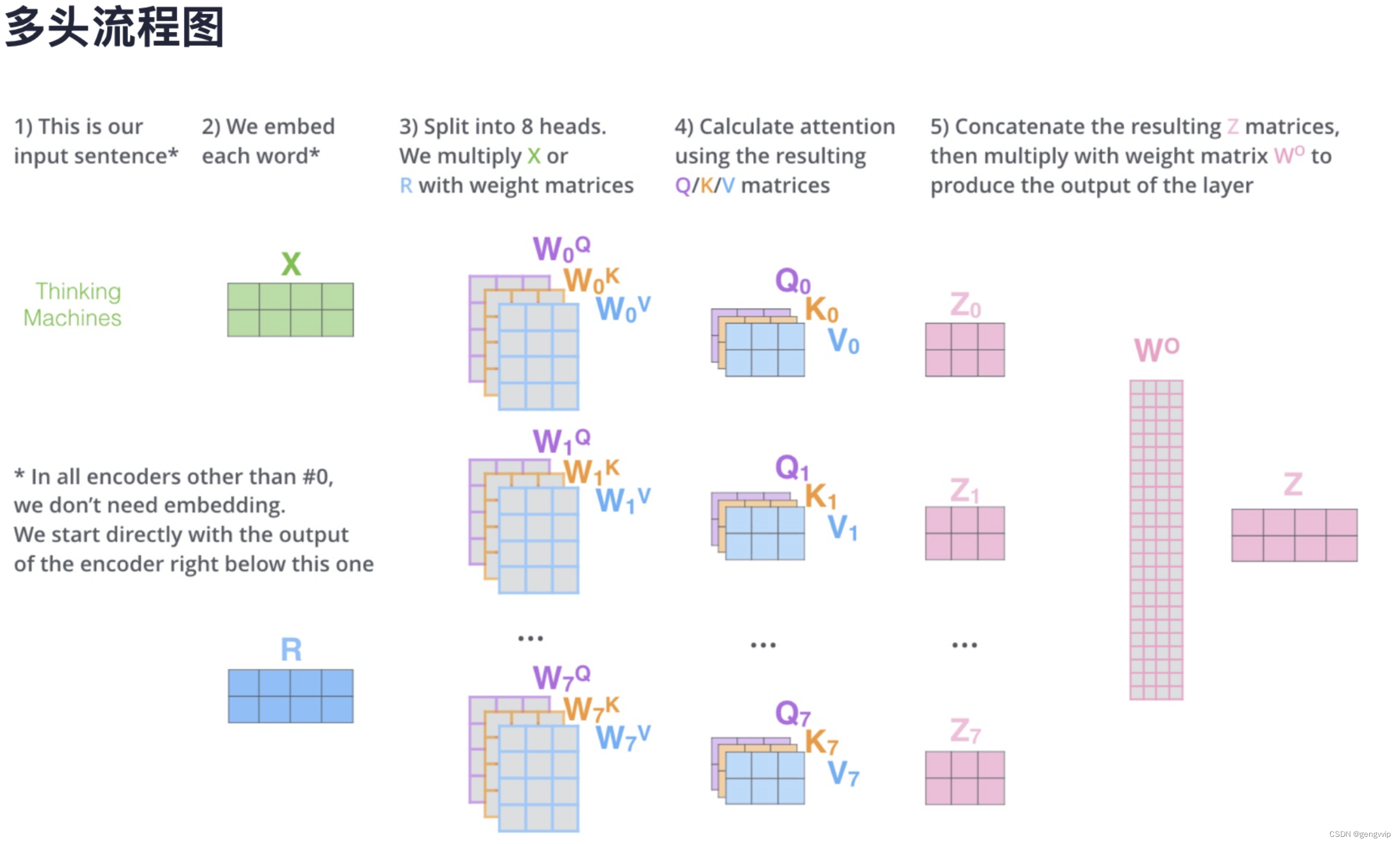
多头的个数用 h 表示,一般ℎ=8h=8,
multi-head attention,把X切分成8块(8个子空间),这样一个原先在一个位置上的X,去了空间上8个位置,通过对8个点进行寻找,找到更合适的位置。
使用多头注意力机制能够联合来自不同head部分学习到的信息。
Self-Attention与Multi-Head Attention计算量对比:两者的计算量其实差不多
-
之前讨论的,机器学习和人工经验结合的方案,现在重新拿出来评估呢?
Transformer
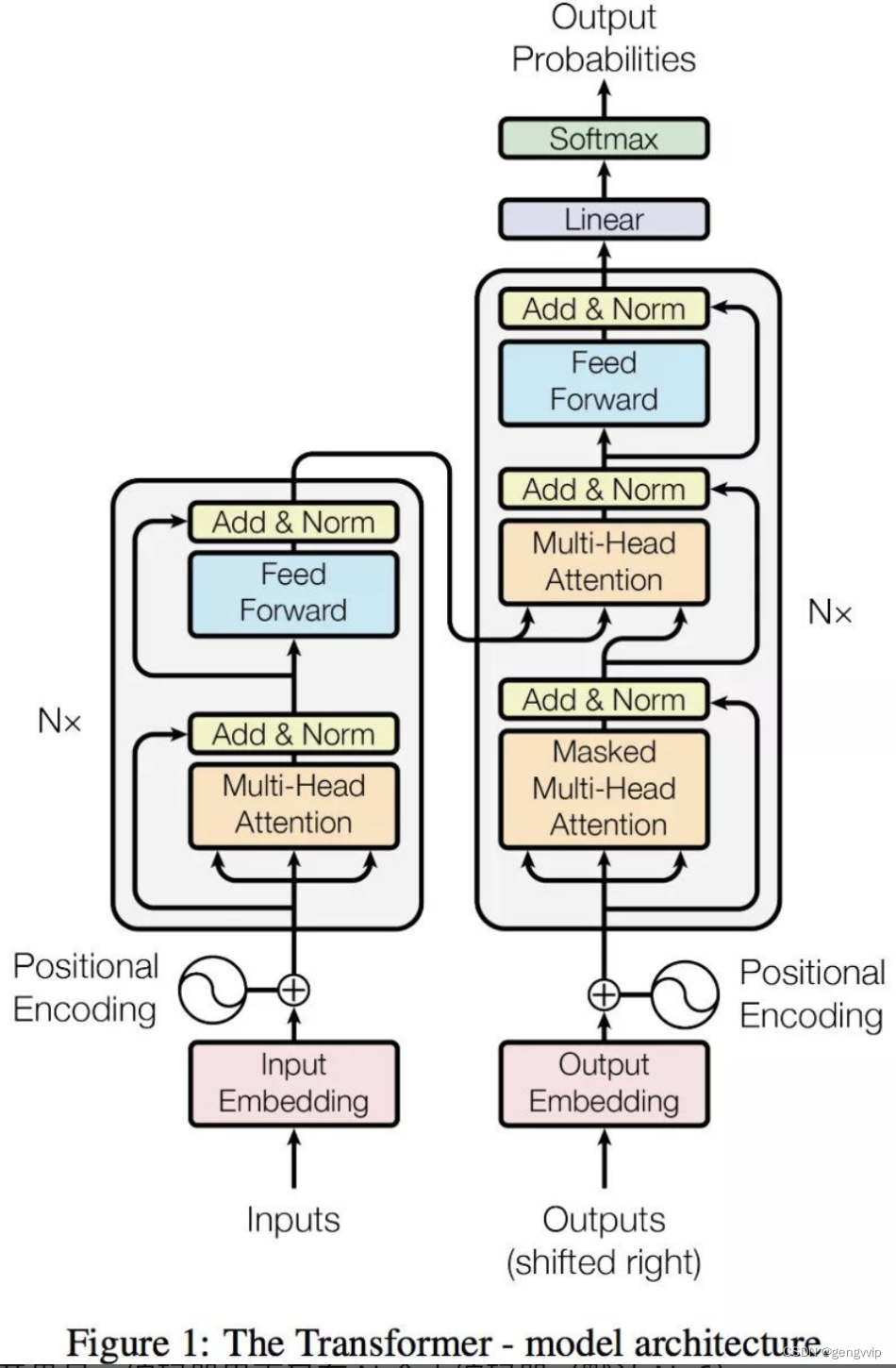
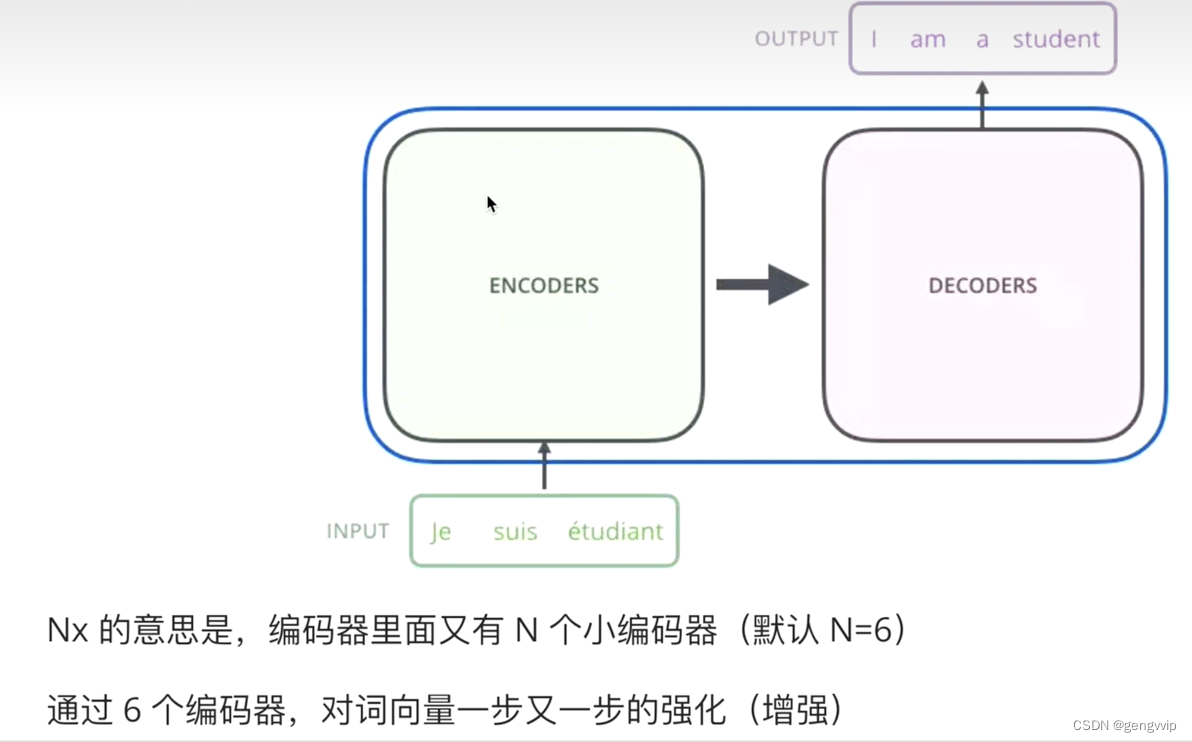
Transformer
Transformer 中self-attention以及mask操作的原理以及代码解析_南京天涯的博客-优快云博客_transformer attention mask
图解Transformer_adam-liu的博客-优快云博客_transformer adam

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









