




 这篇博客探讨了XML在文档处理中的重要性,特别是将PDF转换为XML以进行信息提取。文中推荐了DOM4J库进行XML解析,并提供了个人代码示例,强调Adobe转换工具或福昕SDK在PDF转XML中的高效性。
这篇博客探讨了XML在文档处理中的重要性,特别是将PDF转换为XML以进行信息提取。文中推荐了DOM4J库进行XML解析,并提供了个人代码示例,强调Adobe转换工具或福昕SDK在PDF转XML中的高效性。
背景知识:
- 我们所熟知的办公软件,如word、excel、pdf、PPT等底层都是XML结构语言写的
- 所以将文档转化为xml语言,尤其是PDF向xml转换,再进行xml信息的提取尤为重要
- 本文重点讲xml文件中信息的提取,以及PDF向XML文件的转换
参考资料:
最全的xml操作技术![]() https://www.bilibili.com/video/BV15T4y1P7nM?p=2&vd_source=97411b9a8288d7869f5363f72b0d7613
https://www.bilibili.com/video/BV15T4y1P7nM?p=2&vd_source=97411b9a8288d7869f5363f72b0d7613
个人demo及官方demo ![]() https://github.com/860277630/xml
https://github.com/860277630/xml
下面是一个比较有参考价值的网站,希望对你的xml信息提取有所帮助,个人推荐dom4j进行开发
一些说明:
- PDF提取表格信息 最好使用这个技术,本人做开发很多年,先后使用pdfbox,itext,tabula,pageOffice,以及python的camelot等等等等,无论是收费的还是免费的技术,发现这个才是最好用的
- 先将PDF转为xml文件,可以用java代码转,也可以用另存为*.xml的方式转,然后进行如论是表格还是其他标签,都可以提取到
- 当然,其他办公软件,只要是能转为xml(代码转或者是另存为*.xml方式),都可以进行信息的提取
- 最好使用adobe转XML,实在不行用福昕地SDK转
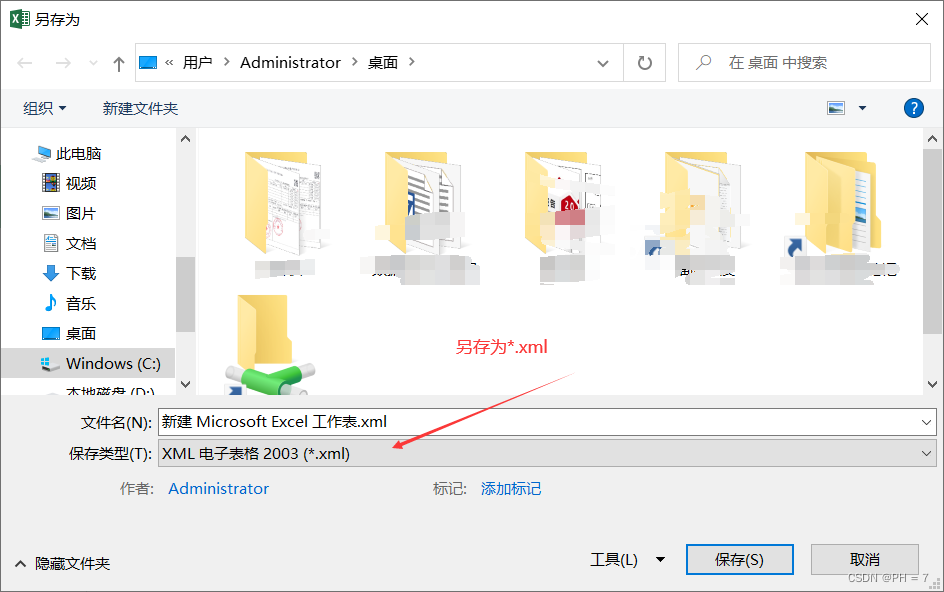
例子:
下面是本人用dom4j提取PDF的部分代码,具体参照参考资料中的个人demo
//然后现在需要 读取xml文件 进行解析
//仅对table 部分进行转换 而且是最内层table
public String parseXml(String save_path) throws Exception {
//加载xml文件
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File(save_path));
//获取PDF的长宽
Element rootElement = document.getRootElement(); // 获取根节点
//然后得到 table 节点
//然后先输出
List<Element> tableList = new ArrayList<>();
analysisList(tableList, rootElement);
//遍历 然后输出
//最小单位为TD 内部的自动合并 进行输出
//每一个table 对应一个 sheet
for (int num = 0; num < tableList.size(); num++) {
//创建sheet
//然后这里获取数据
List<List<CellInfo>> lists = takeApartElement(tableList.get(num));
}
return "";
} //递推函数
private static void analysisList(List<Element> tables, Element element) {
Integer tableNum = StringUtils.countMatches(element.asXML(), "<Table>");
if (element.getName().equals("Table") && tableNum == 1) {
tables.add(element);
} else if (tableNum >= 1) {
//最后一种情况就是 含有多个<Table>标签 就需要进行分解 递归
for (Element ele : element.elements()) {
//递归调用
analysisList(tables, ele);
}
} else {
}
} //将table 元素进行分解 td为最小单元 tr为一个list
private static List<List<CellInfo>> takeApartElement(Element element) {
List<List<CellInfo>> result = new ArrayList<>();
if (StringUtils.equalsAny(element.getName(), PRIMARY_LABEL)) {
List<Element> trList = new ArrayList<>();
//如果是Table标签的话 才可以进行 分解
//因为上面已经筛选过,这个是最小的Table 单元 不需要担心表格的嵌套现象
toTrTd(trList, element, SECONDARY_LABEL);
//填充完后 就再进行遍历 进行内层的填充
for (Element ele : trList) {
List<CellInfo> trStrs = new ArrayList<>();
List<Element> tdList = new ArrayList<>();
//每个tr行的 td集合
toTrTd(tdList, ele, TERTIARY_LABEL);
//然后我们把每个td都进行转化
for (int num = 0; num < tdList.size(); num++) {
List<String> strList = new ArrayList<>();
//2022/7/20 增加 如果是单独的</TH> 就不进入统计
Element trEle = tdList.get(num);
if(!trEle.asXML().equals("<TH/>")){
collectTd(strList, trEle);
//然后将 StringList 转为字符串
String str = StringUtils.join(strList, StringUtils.EMPTY);
if (!StringUtils.containsAny(str, IGNORE_WORD)) {
trStrs.add(new CellInfo(str, Float.valueOf(num), null, null,Boolean.FALSE));
}
}
}
result.add(trStrs);
}
}
return result;
}


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











