




 本文详细解析了HashMap、HashTable及ConcurrentHashMap的工作原理与性能差异,深入探讨了它们的内部结构、锁机制以及在不同场景下的应用。通过对比分析,帮助读者理解如何选择合适的集合类型以提高程序效率。
本文详细解析了HashMap、HashTable及ConcurrentHashMap的工作原理与性能差异,深入探讨了它们的内部结构、锁机制以及在不同场景下的应用。通过对比分析,帮助读者理解如何选择合适的集合类型以提高程序效率。
1、HashMap和HashTable的区别
1、HashMap线程不安全,HashTable线程安全
2、因为线程安全,HashTable效率比HashMap低
3、HashTable的key和value都不能为空,HashMap只能有一个key为null,多个value值为null
4、HashMap默认初始数组大小是16,HashTable默认是11,HashMap扩容2倍,HashTable扩大两倍+1
5、HashMap需要重新计算hash值,而HashTable直接使用兑现过的hashCode
2、ConcurrentHashMap和HashTable在线程同步上有什么区别?
HashTable直接使用的synchronized关键字
ConcurrentHashMap在jdk7中采用了Segment分段锁,在jdk8中采用了CAS+synchronized,也采用了分段锁的方式大大缩小了锁的粒度,所有ConcurrentHashMap效率比HashTable高
3、hashMap和ConcurrentHashMap的区别
1、ConcurrentHashMap是线程安全的
2、HashMap的key和value都可以为null,ConcurrentHashMap的key和value都不能为null
3、红黑树相关的节点类,数据结构不同
4、为什么 ConcurrentHashMap 比 HashTable 效率要高?
1、HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
2、ConcurrentHashMap 在JDK 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry),相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于 Segment,包含多个 HashEntry。
JDK 1.8 中使用 CAS + synchronized + Node + 红黑树。锁粒度:Node(首结点)(实现 Map.Entry<K,V>)。锁粒度降低了。
5、针对 ConcurrentHashMap 锁机制具体分析(JDK 1.7 VS JDK 1.8)?
在1.7中,采用分段锁机制,底层采用数组+链表结构
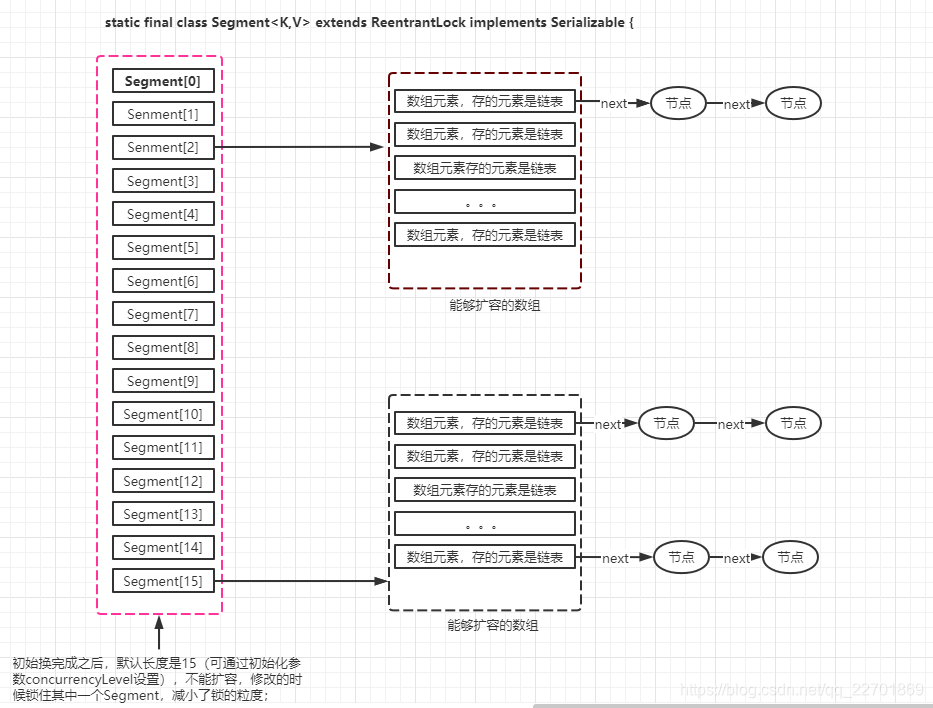
JDK 1.8 中,采用Node + CAS + Synchronized来保证并发安全。取消类 Segment,直接用 table 数组存储键值对;当链表长度》=8,链表转换为红黑树,提升性能。底层变更为数组 + 链表 + 红黑树。当红黑树<=6,降级为链表
6、ConcurrentHashMap 在 JDK 1.8 中,为什么要使用内置锁 synchronized 来代替重入锁 ReentrantLock?
1、因为jdk8对synchronized进行了大量优化,效率提升了
2、在大量的数据操作下,对于 JVM 的内存压力,基于 API 的 ReentrantLock 会开销更多的内存。
7、ConcurrentHashMap 简单介绍?
重要的常量:
private transient volatile int sizeCtl;
| 负数 | 正在初始化或者扩容操作 |
| -1 | 正在初始化 |
| -N | 代表有N-1个线程正在进行扩容操作 |
| 0默认值 | 代表还没有被初始化 |
| 正数 | 表示初始化大小或者Map中的元素叨叨这个数量是,需要进行扩容了 |
数据结构:
Node 是存储结构的基本单元,继承 HashMap 中的 Entry,用于存储数据;
TreeNode 继承 Node,但是数据结构换成了二叉树结构,是红黑树的存储结构,用于红黑树中存储数据;
TreeBin 是封装 TreeNode 的容器,提供转换红黑树的一些条件和锁的控制。
存储对象时(put() 方法):
1.如果没有初始化,就调用 initTable() 方法来进行初始化;
2.如果没有 hash 冲突就直接 CAS 无锁插入;
3.如果需要扩容,就先进行扩容;
4.如果存在 hash 冲突,就加锁来保证线程安全,两种情况:一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入;
5.如果该链表的数量大于阀值 8,就要先转换成红黑树的结构,break 再一次进入循环
6.如果添加成功就调用 addCount() 方法统计 size,并且检查是否需要扩容。
扩容方法 transfer():
默认容量为 16,扩容时,容量变为原来的两倍。
获取对象时(get()方法):
1.计算 hash 值,定位到该 table 索引位置,如果是首结点符合就返回;
2.如果遇到扩容时,会调用标记正在扩容结点 ForwardingNode.find()方法,查找该结点,匹配就返回;
3.以上都不符合的话,就往下遍历结点,匹配就返回,否则最后就返回 null。
8、ConcurrentHashMap 的并发度是什么?
1.7中程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数。即Segment数组的长度,默认为 16,且可以在构造函数中设置。当用户设置并发度时,ConcurrentHashMap 会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)。
1.8中并发度则无太大的实际意义了,主要用处就是当设置的初始容量小于并发度,将初始容量提升至并发度大小。

















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









