



仅仅是为了记录一下自己的学习过程,所有的代码和数据集均来自于互联网,也会放在我的Github上。
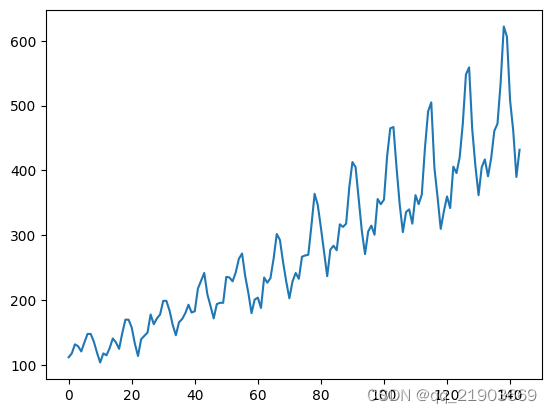
数据集采用的是飞机航班的数据集,对其进行读取之后可视化效果如图,可以看到有着一些周期性的规律,非常适合于RNN这样的来进行预测
1.导入相关的包
导入相关的包,其中最后一行的Variable感觉可有可无,我给注释掉之后也能正常的运行,不知道有没有大佬可以赐教一下,不甚感激。
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torch.autograd import Variable2.对于数据进行一些初步的预处理
其中包括丢掉Nan的数据以及进行归一化的处理
data_csv = data_csv.dropna()
dataset = data_csv.values
dataset = dataset.astype("float32")
scalar = np.max(dataset) - np.min(dataset)
dataset = list(map(lambda x: x.item() / scalar, dataset))最终可以得到有着144个数据,其中归一化的操作也可以使用sklearn进行归一化处理,但是会使得维度增加一个,需要在后期squeeze掉
from sklearn.preprocessing import MinMaxScaler
data_csv = data_csv.dropna()
dataset = data_csv.values
dataset = dataset.astype("float32")
scaler = MinMaxScaler()
dataset = scaler.fit_transform(dataset)3.划分测试集和训练集
look_back参数是代表用多少个数据来预测下一个的数据,比如设置是30,就代表用1至30天的流量数据来预测的第31天的流量数据,然后用2至31天的数据来预测第32天的数据等,以此类推,如果对模型进行修改,这是一个很重要的参数。
测试集和训练集的按0.7的比例进行划分,如果按照30个来预测一个的计算,那么训练集共有79个
look_back = 30
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back):
a = [dataset[i: (i + look_back)]]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
dataX, dataY = create_dataset(dataset, look_back)train_size = int(len(dataX) * 0.7)
test_size = len(dataX) - train_size
train_x = dataX[:train_size]
train_y = dataY[:train_size]
test_x = dataX[train_size:]
test_y = dataY[train_size:]其中注释掉的那一行是因为前面是sklearn处理多了一个维度
train_x = torch.from_numpy(train_x)
#train_x = train_x.squeeze(3)
train_y = torch.from_numpy(train_y)
test_x = torch.from_numpy(test_x)
test_y = torch.from_numpy(test_y)4.构建模型
根据Pytorch中RNN的官方文档,对于输入的数据进行一些解释。look_back设置为30,即根据30个数据来预测第31个数据,那么一组就是有30个数据,即input_size = 30;测试集有141×0.7取整后98个,所以sequence_leghth = 98;每次喂一组数据进去,所以bath_size = 1
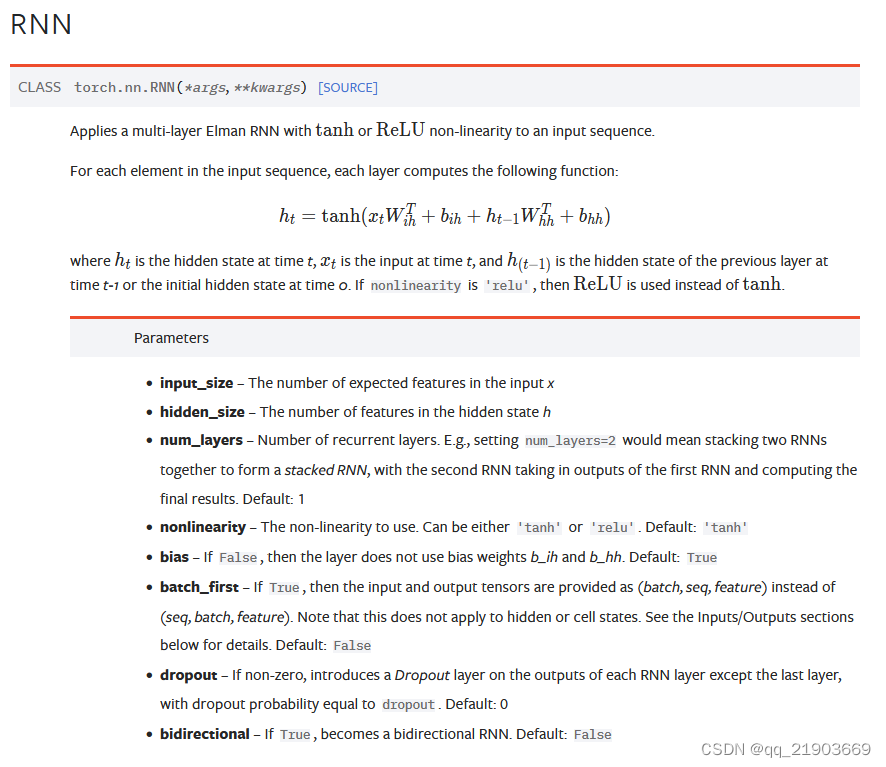

对于模型进行初始化的时候,要求的input_size和数据的大小是一样的(这里有点刻舟求剑了,应该是先有模型的尺寸大小,再去构造数据),hidden_size的大小是16,这个是自己设置的,可以设置其他的数字。
class rnn_reg(torch.nn.Module):
def __init__(self, input_size, hidden_size, out_size = 1,num_layers = 2) -> None:
super(rnn_reg, self).__init__()
self.rnn = torch.nn.RNN(input_size, hidden_size, num_layers)
self.reg = torch.nn.Linear(hidden_size, out_size)
def forward(self, x):
#seq, bacth_size, hidden
#有train_size个数据(seq)、每一组有look_back个
x, _ = self.rnn(x)
seq, batch_size, hidden_size = x.shape
x = x.reshape(seq * batch_size, hidden_size)
x = self.reg(x)
x.reshape(seq, batch_size, -1)
return x
net = rnn_reg(look_back, 16)最后可以输出一下设置的模型内的一些层数的维度
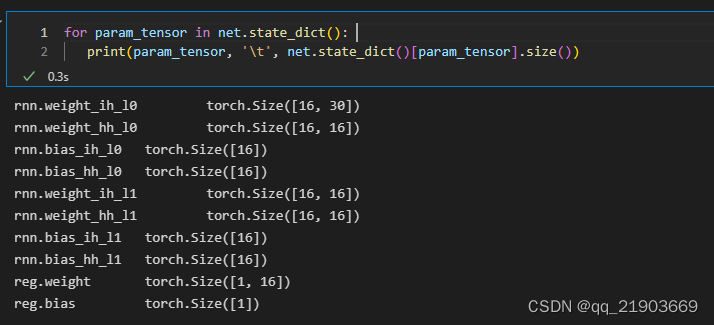
根据官方文档的描述,输入的数据包含sequence length、batch size、input_size三个维度,按个人的理解其中batch size没啥用(官方文档也说了可以不用加)。假设公式前半部分结果为A,后半部分结果是B,那么仅仅从维度的角度考虑输入之后应该是这样的
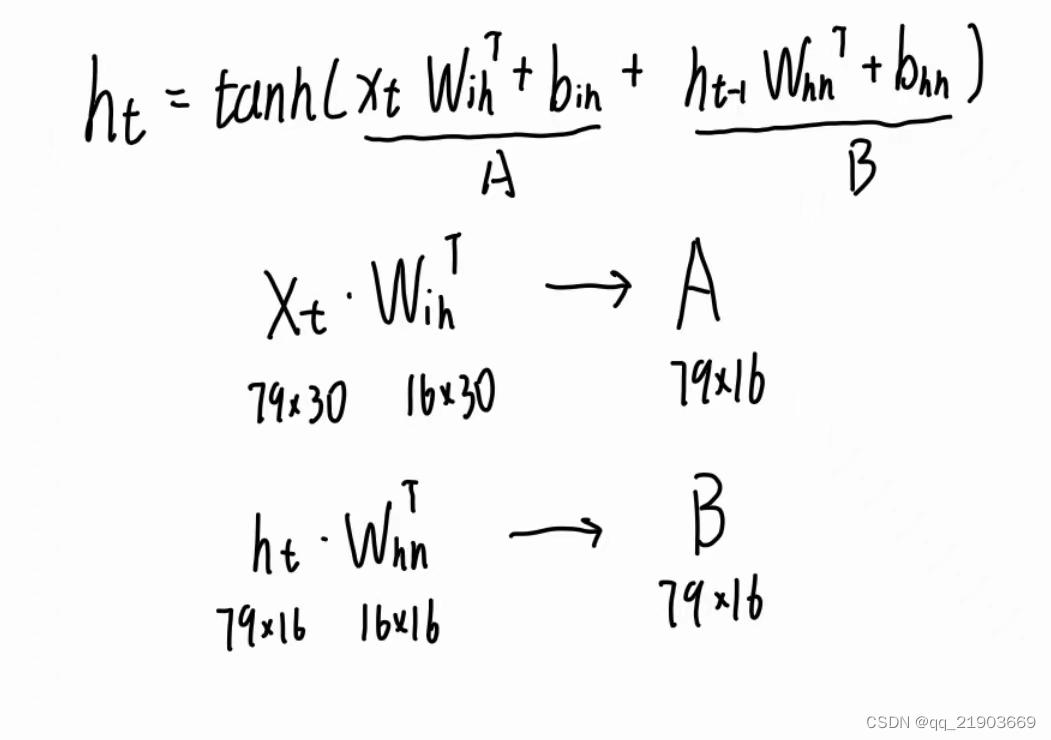
也可以在forward中把输出x的维度进行打印一下,是[79, 1, 16]其中1是batch size
5.构建训练函数以及结果展示
这个相对来说比较简单,设置为训练2000次,每100次输出一次损失,如果可以的话后期会加上输出损失的同时使用测试集进行一次测试,看看在测试集上的损失情况
running_loss = 0.0
for epoch in range(2000):
var_x = Variable(train_x).to(torch.float32)
var_y = Variable(train_y).to(torch.float32).reshape(train_size, -1)
out = net(var_x)
loss = criterion(out, var_y)
running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0: # 每 100 次输出结果
print('Epoch: {}, Loss: {:.5f}'.format(epoch + 1, running_loss / 100))
running_loss = 0.0相关的损失情况和最后输出预测曲线和实际曲线之间的对比
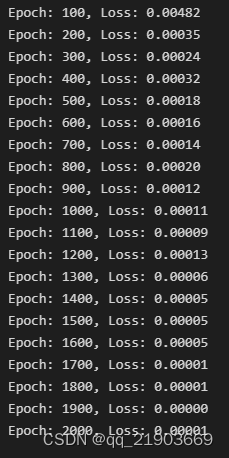
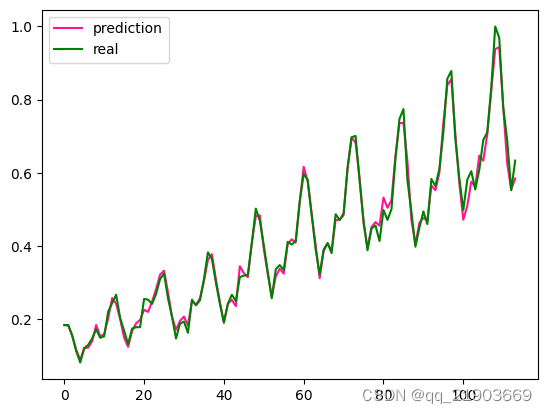
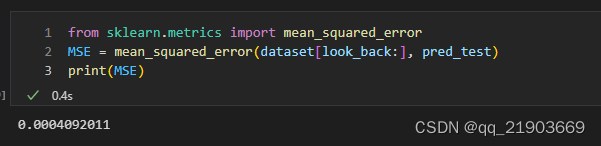
因为前面训练次数太多了,所以导致拟合的过于精准,不是后半部分看不出区别,所以这里是训练1000次的真实/预测曲线对比。而且这里因为用30个预测1个,所以这里测试曲线没有前30个数据。同理,下面计算MSE的也不包括前30个数据,否则没法去计算
最后附上Github的链接
GitHub - ShopkeeperAKASHI/RNN-Series-Forecast: 关于RNN序列预测的一些项目工程

















 4460
4460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









