package extthread;
public class MyThread extends Thread {
@Override
public void run() {
long beginTime = System.currentTimeMillis();
int count = 0;
for (int i = 0; i < 50000000; i++) {
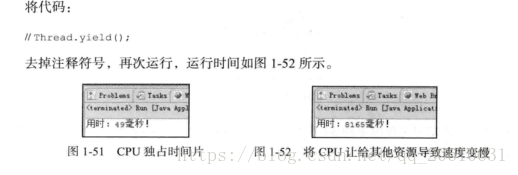
Thread.yield();
count = count + (i + 1);
}
long endTime = System.currentTimeMillis();
System.out.println("用时:" + (endTime - beginTime) + "毫秒!");
}
}
package test;
import extthread.MyThread;
import extthread.MyThread;
public class Run {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}
























 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









