



 本文详细介绍了Redis中的基本数据结构,包括String、Hash、List、Set和Sorted Set,以及高级数据结构如HyperLogLog、GEO、Pub/Sub等。针对每个数据结构,文章列举了具体的应用场景,如使用String实现计数器和分布式锁,Hash用于存储对象和实现购物车功能,List构建排行榜和消息队列,Set用于好友集合,Sorted Set处理有序数据,Geo存储地理位置信息,HyperLogLog做基数统计,Bitmap记录用户签到,以及BloomFilter进行存在性检验。
本文详细介绍了Redis中的基本数据结构,包括String、Hash、List、Set和Sorted Set,以及高级数据结构如HyperLogLog、GEO、Pub/Sub等。针对每个数据结构,文章列举了具体的应用场景,如使用String实现计数器和分布式锁,Hash用于存储对象和实现购物车功能,List构建排行榜和消息队列,Set用于好友集合,Sorted Set处理有序数据,Geo存储地理位置信息,HyperLogLog做基数统计,Bitmap记录用户签到,以及BloomFilter进行存在性检验。
数据结构以及应用场景
-
Redis 有五种基本数据结构,分别是字符串(String)、 哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)。
-
高级数据结构 HyperLogLog 用来做基数统计的算法,GEO 将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作,Pub/Sub 发布订阅的通信模式。另外还可以用 Redis Modules 外部模块进行功能性扩展,像 BloomFilter(布隆过滤器),RediSearch(搜索引擎),Redis-ML(机器学习)……
-
String 存储对象(最大可以存储512M):
- set 计数器:incr,decr
- 分布式锁:setnx,setex,del
-
Hash (键值对个数最多为 2^32-1)
-
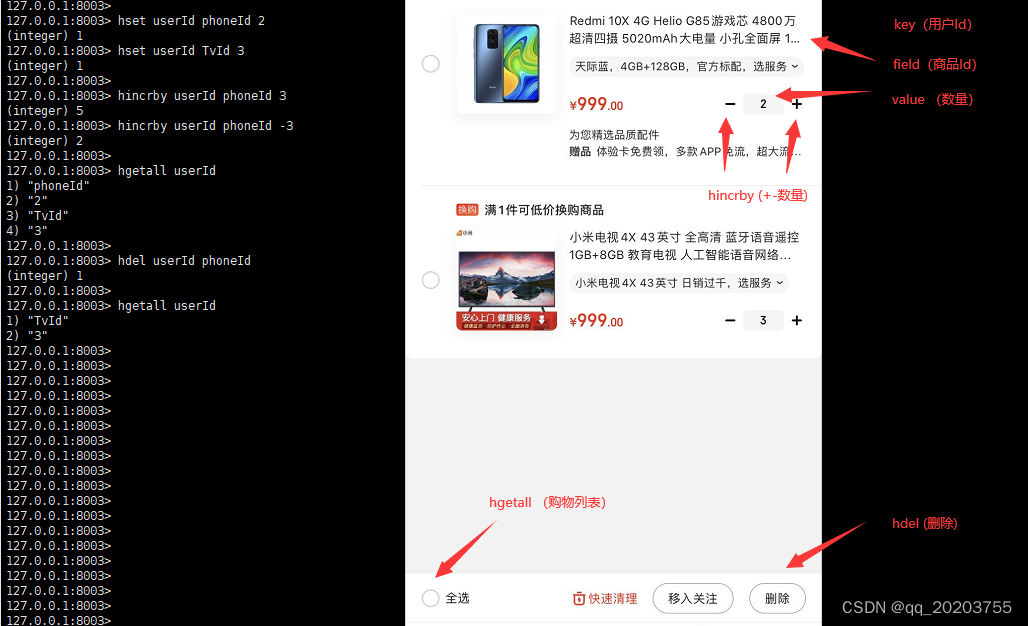
购物车:hset,hdel,hlen,hincrby,hgetall
-
存储对象: 对象里某个字段属性时需要频繁更新时, 适合存储在Hash类型里
-
-
List (元素个数最多为 2^32-1 个)
-
LRange 排行榜,最新列表
-
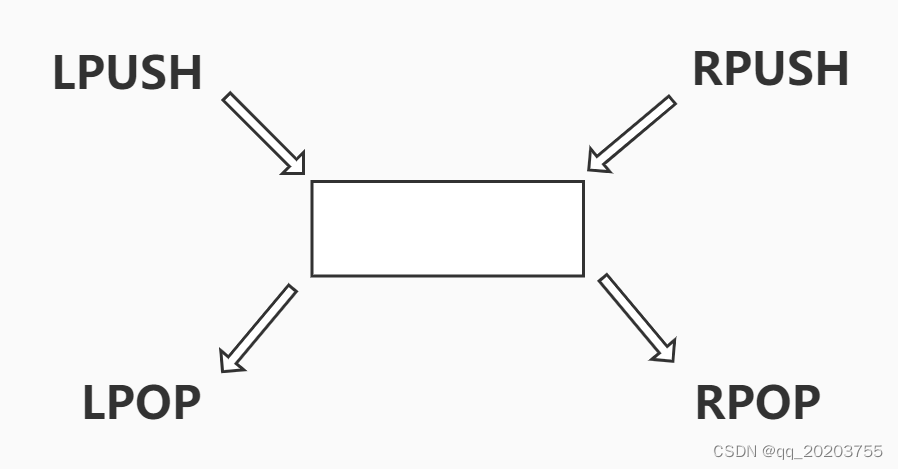
RPush + RPop = Statck (栈) //当然用 LPush + LPop 也是可以的,符合先进先去
-
RPush + RTrim = Capped Collection(有限集合)
-
RPush + LPop = Queue(队列)
-
RPush + BLPop = Message Queue(消息队列)
-
//RPush 生成消息,LPop 消费消息,在没有消息的时候需要 Sleep 一会再重试
-
//BLPop 在没有消息的时候,它会阻塞主直到有消息来
-
-
Set (元素个数最多为 2^32-1 个)
-
不重复的数据,无序,好友/关注/粉丝/感兴趣的人集合 随机展示
-
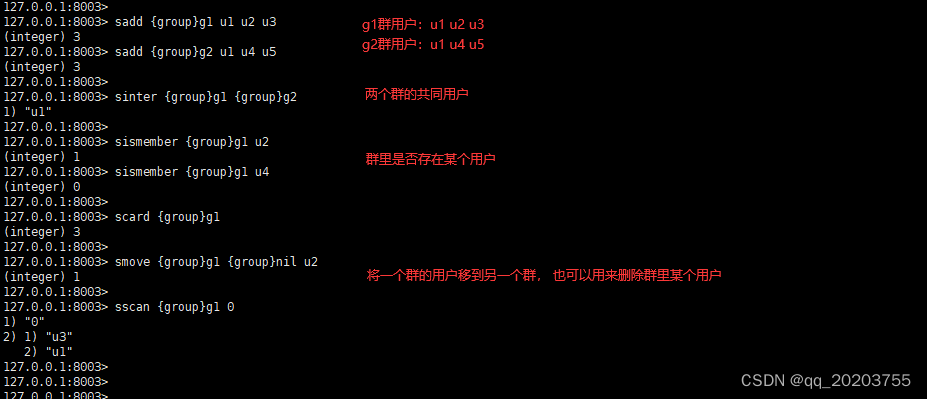
sinter:获得A和B两个用户的共同好友
-
sismember:判断A是否是B的好友
-
scard:获取好友数量
-
smove:将B从A的粉丝集合转移到A的好友集合
-
srandmember:随机获取几个
-
集群模式下对两个集合间的比较需要在同一个solt区间,不然会提示 CROSSSLOT Keys in request don’t hash to the same slot。
-
-
Sort Set (元素个数最多为 2^32-1 个)
-
有序,一个 value 可以对应多个 score,其中 score 可以重复, value 唯一 。 订单列表/延时队列:时间戳作为score,消息内容作为value,调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据进行处理处理,处理完后再获取N+M下一个时间段数据进行处理。

-
-
Geo
-
将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作(没有删除元素指令)

-
-
HyperLogLog
-
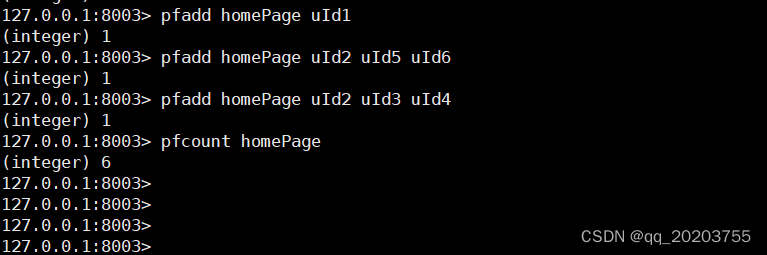
统计UV(同一个用户一天之内的多次访问请求只能计数一次),并发高时有精度误差(少于1%)
-
-
BitMap(位图)
- 用户一年的签到
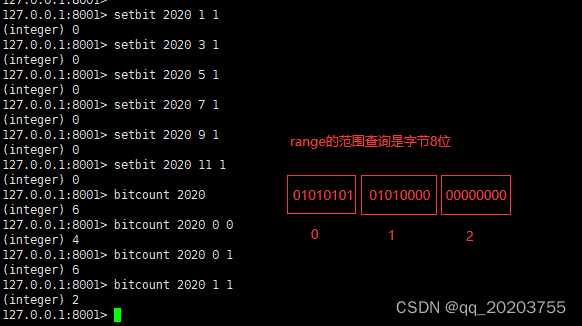
- 用户一年的签到
-
布隆过滤器
-
检验某个值是否存在(有一点的误差,需要安装,某个值存在时,这个值可能不存在。当它说不存在时,那就肯定不存,空间上节省90%,可通过布隆计算器调整配置去调整精度误差)
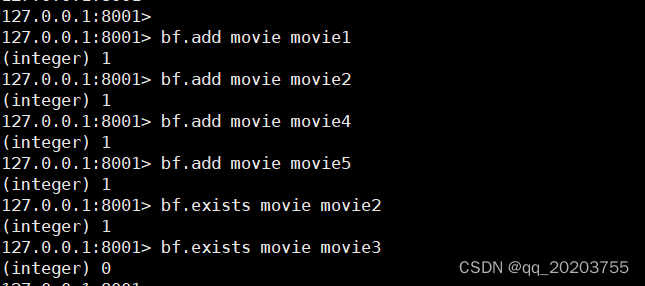
-


















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











