






 本文探讨了如何将大规模数据转化为小块数据并构建高效索引,通过使用BerkeleyDB实现快速查询,旨在解决2.2亿条博文数据的索引与检索问题。
本文探讨了如何将大规模数据转化为小块数据并构建高效索引,通过使用BerkeleyDB实现快速查询,旨在解决2.2亿条博文数据的索引与检索问题。
思路分析图(海量数据索引构建、分发布署、查询过程)
总体思路:大数据转化成小块数据,根据小块建立索引,在搜索时候直接定位到小块数据后进行快速查询。
具体思路:
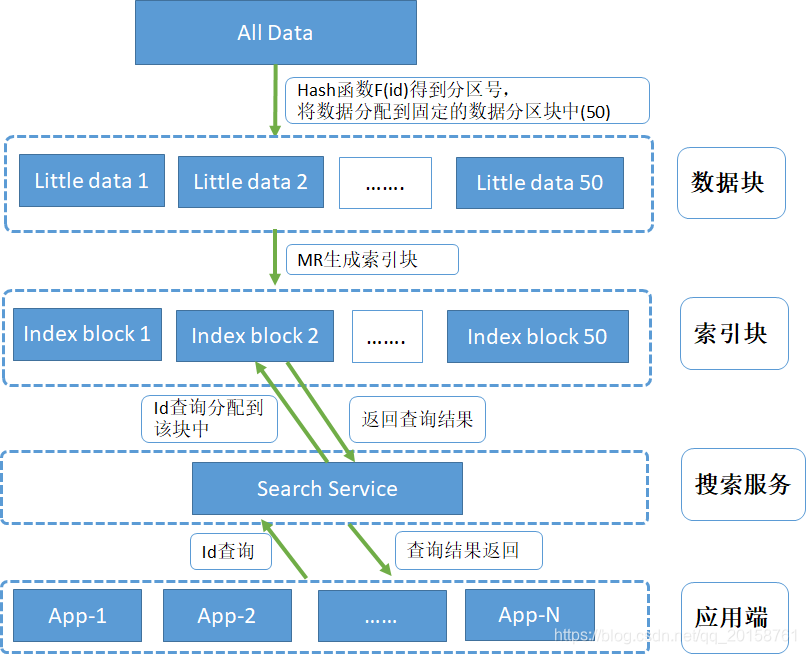
2.基于2.2亿条博文数据,构建满足条件的索引结构与查询引擎
2.1索引结构与查询引擎其实是一回事,索引定了,查询引擎主要是用已定的索引结构去查询。
2.2输入博文id,拿到博文的详情信息,显然是数据库查询问题
2.3数据库选型分析
承载数据量大、扩展性要好
分布式、轻量级、易布署、易运维
内存与硬盘结合做资源使用
关系型/非关系型
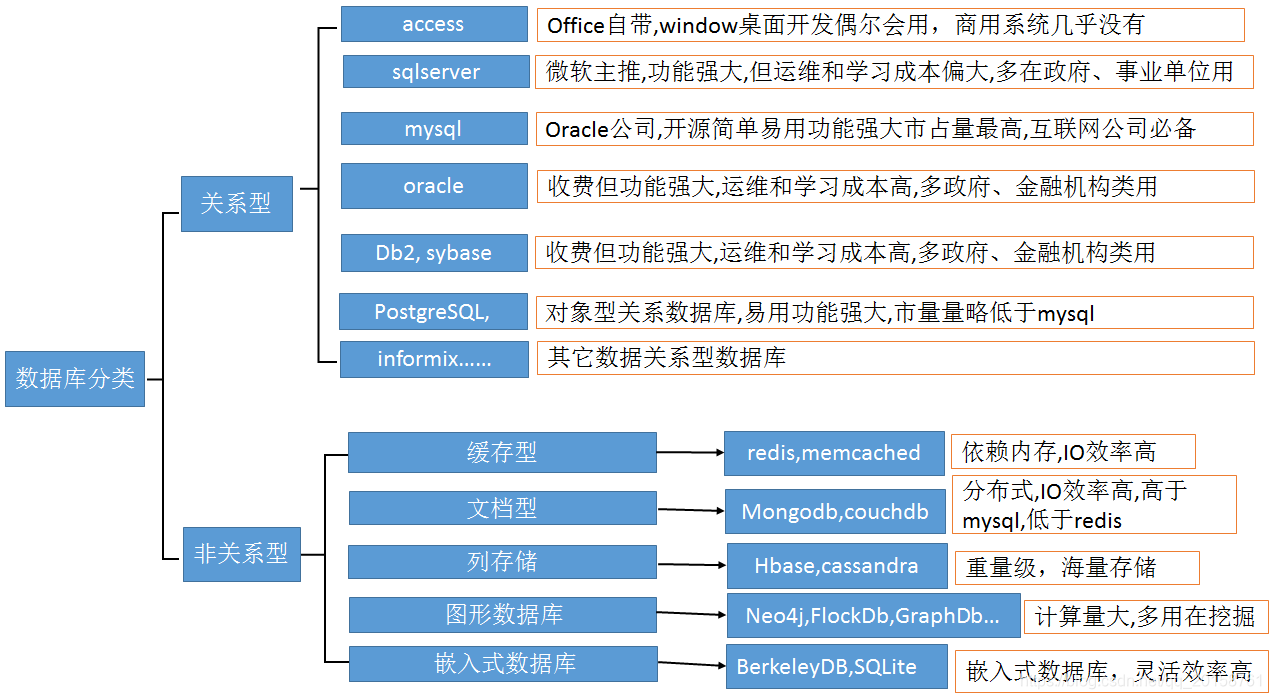
2.4数据库选择确定
BerkeleyDB(BDB)
优点:
嵌入式数据库
KV型数据库
文件型数据库
历史悠久、成熟、稳定、易布署、易运维、高性能
跨语言支持全面
缺点:
不支持直接网络访问
数据共享不方便
不支持SQL(现在已支持,但应用的不多)
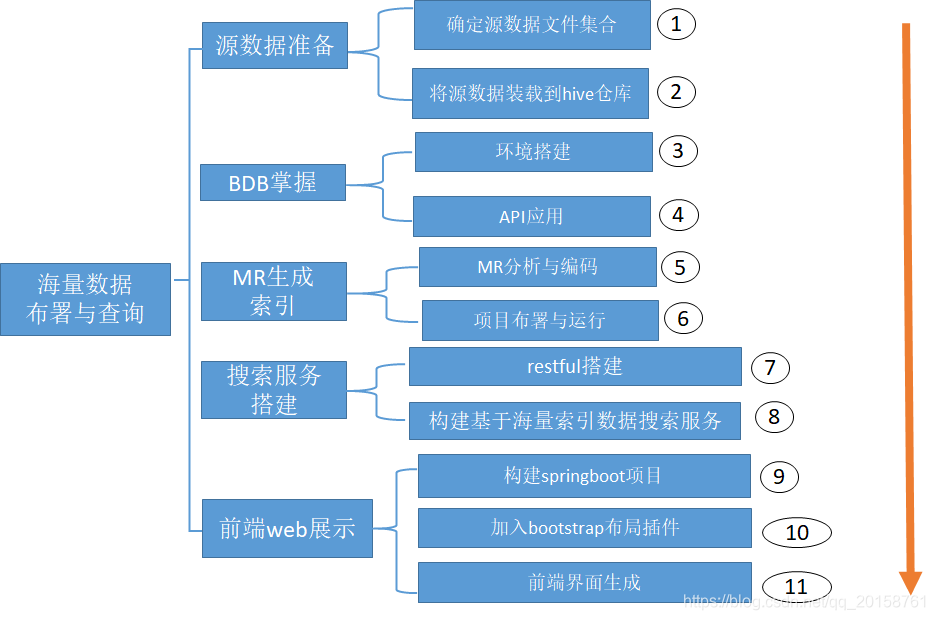
3.需求分析产出

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









