




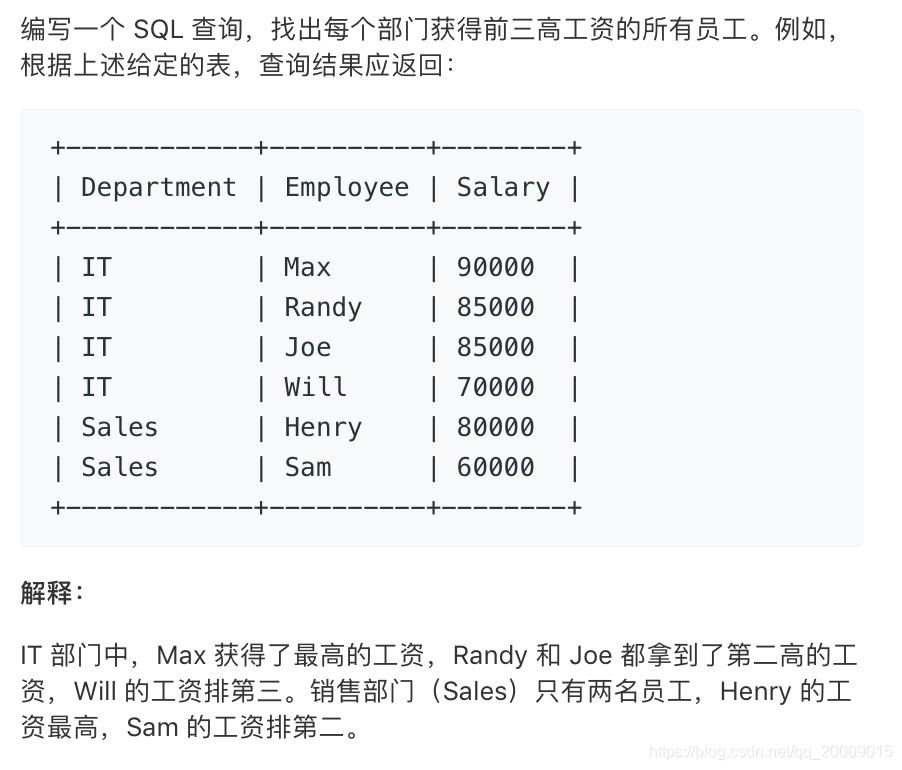
 本文介绍了两种在MySQL中获取每个部门工资前三名员工的方法。第一种是利用分组序号,通过定义自变量进行部门内排序并筛选;第二种是使用子查询,先找出全公司排名前三的工资,再进行部门关联查询。虽然子查询方式更易理解,但效率较低。
本文介绍了两种在MySQL中获取每个部门工资前三名员工的方法。第一种是利用分组序号,通过定义自变量进行部门内排序并筛选;第二种是使用子查询,先找出全公司排名前三的工资,再进行部门关联查询。虽然子查询方式更易理解,但效率较低。
两种解法 子查询和分组序号
1.分组序号,思路:
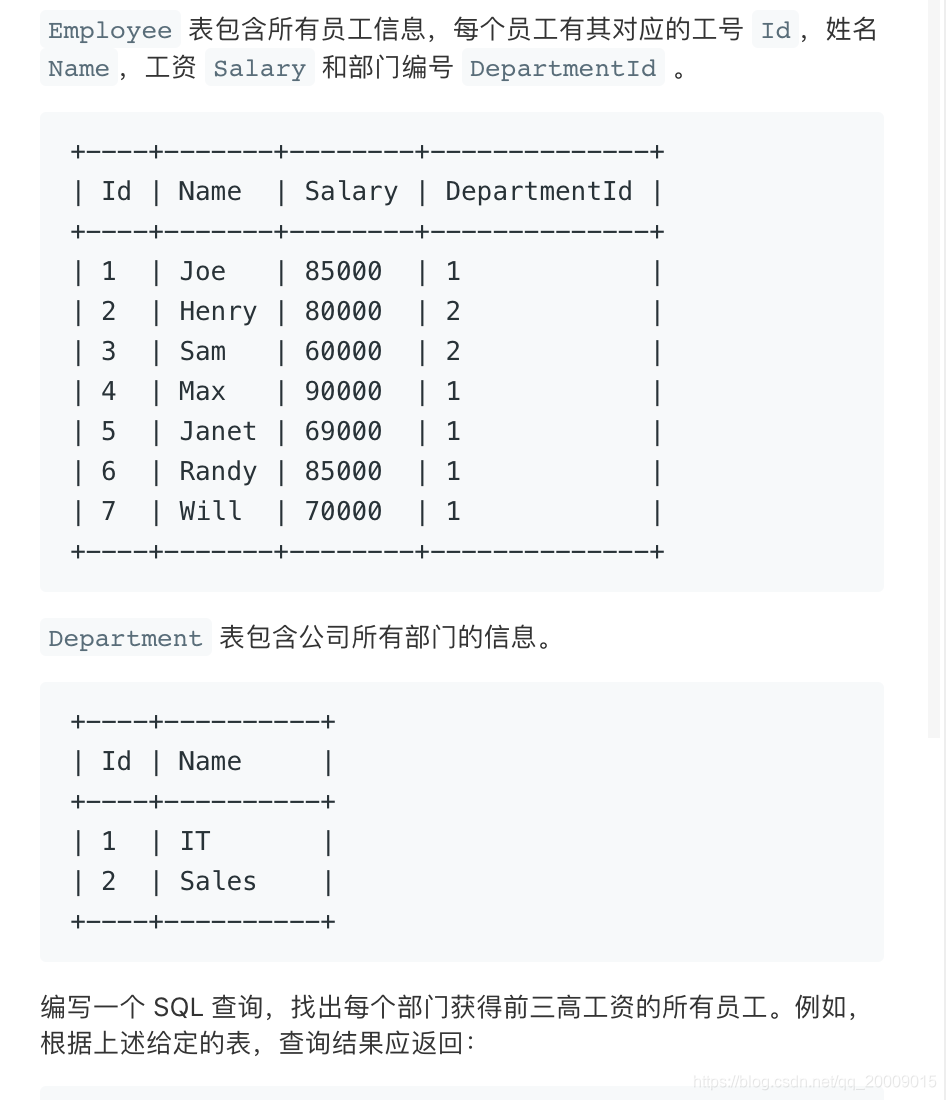
表关联查询,先按部门分组,按工资排序。
select d.name as Department,e.name as Employee,Salary from Employee e
join Department d on e.DepartmentId=d.id
group by DepartmentId,e.id order by DepartmentId,Salary Desc
这个时候我们要将分组排序后的前三个取出来,而且工资相同的排名也要相同,也要取出来。
那么需要定义三个自变量,
一个用于定义顺序
一个用于保存上一行的部门,用于判断部门,如果部门不同就要重置序号为1
一个用于保存上一行的工资,如果工资相同 序号就不增加
最后就可以按nu m筛选取出来nu m<=3的数据了。
select Department,Employee,Salary from
(
select if(@last!=Department,@num:=1,@num:=@num+if(@lastSalary=Salary,0,1)) as num,
Department,Employee,Salary,
@last:=Department as lastDepartment,@lastSalary:=Salary as lastSalary
from
(select d.name as Department,e.name as Employee,Salary from Employee e
join Department d on e.DepartmentId=d.id
group by DepartmentId,e.id order by DepartmentId,Salary Desc ) a,
(select @last:=null,@lastSalary:=null,@num:=0) b group by Department,Employee order by Department,Salary Desc
) tmp where num<=3
2.子查询
先查询 全公司排名前三的工资
查询出来的结果是 e1 工资里面 比e2 工资小不超过三个的数据行, 其实也就是排名前三的工资。
select e1.Name,e1.Salary,e1.DepartmentId from Employee e1 where
(
select count(distinct Salary) from Employee e2 where e1.Salary<e2.Salary
) <3
如果要取部门前三的,则关联条件中再加上 部门id
select e1.Name,e1.Salary,e1.DepartmentId from Employee e1 where
(
select count(distinct Salary) from Employee e2
where e1.Salary<e2.Salary and e1.DepartmentId= e2.DepartmentId
) <3
然后
然后关联部门,按部门排序即可
select d.Name as Department, Employee,Salary from
(select e1.Name as Employee ,e1.Salary,e1.DepartmentId from Employee e1 where
(
select count(distinct Salary) from Employee e2 where e1.Salary<e2.Salary and e1.DepartmentId= e2.DepartmentId
) <3 ) a
join Department d
on(a.DepartmentId=d.id) order by DepartmentId
这个写起来简单 但是比较难理解,而且效率低于分组按序号筛选的方式。
理解过程如下:
DISTINCT 字段名 过滤字段中的重复记录
我们先找出公司里前 3 高的薪水,意思是不超过三个值比这些值大
SELECT e1.Salary
FROM Employee AS e1
WHERE
(SELECT count(DISTINCT e2.Salary)
FROM Employee AS e2
WHERE e1.Salary < e2.Salary AND e1.DepartmentId = e2.DepartmentId) <3
举个栗子:
当 e1 = e2 = [4,5,6,7,8]
e1.Salary = 4,e2.Salary 可以取值 [5,6,7,8],count(DISTINCT e2.Salary) = 4
e1.Salary = 5,e2.Salary 可以取值 [6,7,8],count(DISTINCT e2.Salary) = 3
e1.Salary = 6,e2.Salary 可以取值 [7,8],count(DISTINCT e2.Salary) = 2
e1.Salary = 7,e2.Salary 可以取值 [8],count(DISTINCT e2.Salary) = 1
e1.Salary = 8,e2.Salary 可以取值 [],count(DISTINCT e2.Salary) = 0
最后 3 > count(DISTINCT e2.Salary),所以 e1.Salary 可取值为 [6,7,8],即集合前 3 高的薪水
再把表 Department 和表 Employee 连接,获得各个部门工资前三高的员工。

















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









