




 本文详细解析了Java中的String类intern方法以及常量池的工作原理。在JDK1.7之后,intern方法会检查常量池中是否存在相同字符串,若不存在则将引用放入,存在则返回引用。通过实例代码展示了不同情况下intern的行为,包括字面量赋值、new String创建以及"+"拼接字符串等场景,揭示了JDK1.7以前与1.7之后常量池位置的区别及其对对象创建的影响。
本文详细解析了Java中的String类intern方法以及常量池的工作原理。在JDK1.7之后,intern方法会检查常量池中是否存在相同字符串,若不存在则将引用放入,存在则返回引用。通过实例代码展示了不同情况下intern的行为,包括字面量赋值、new String创建以及"+"拼接字符串等场景,揭示了JDK1.7以前与1.7之后常量池位置的区别及其对对象创建的影响。
intern方法的作用: 在jdk1.7版本以后,查看常量池中有没有该字符串的常量,如果没有,就将该字符串的引用放到常量池,如果有,则返回该字符串。
在jdk1.7以前,,查看常量池中有没有该字符串的常量,如果没有,就将该字符串拷贝一份放到常量池,如果有,则返回该常量的引用。
先看以下代码,判断下输出是什么?
String s = new String("1");
String s2 = "1";
System.out.println(s == s2);
System.out.println(s.intern() == s2);
输出分别是
false
true
这里首先要明白一点:在new String(“1”) 的时候,jvm除了会在堆中创建一个字符串对象,还会去查看常量池里面有没有暂存这个对象,如果没有,那么会创建一个对象,并把这个对象的引用放到常量池中。
也就是 String s = new String("1"); 这行代码创建了几个对象? 如果常量池中没有,那么是创建了两个,如果有,那就是一个。
String s2 = "1"; s2 赋值的时候,是从常量池里面取出来的引用。
也就是 在 String s2 = "1"; 这种字面量赋值的时候,是先去看常量池里面有没有这个字符串对象,如果有,那么就从常量池中返回一个引用并赋值,如果没有,那么就创建一个对象,并把引用放到常量池,并返回常量池中的引用。
具体如下
//创建一个字符串对象 ,
//然后发现常量池中没有,
//那么再创建另一个一个对象字符串对象, 并将这个对象的引用放到常量池
String s = new String("1");
//先看常量池中,发现有”1“这个字符串对象,
//那么将常量池中的引用赋予s2
String s2 = "1";
//s和s2分别是指向两个不同的对象,因此地址不同 返回false
System.out.println(s == s2);
//s.intern() 手动尝试将s放到常量池,
//结果发现常量池中已经有这个字符串常量的引用,
// 那么返回这个引用 ,s2也是常量池中对象的引用 ,
//是同一个地址,因此返回true
System.out.println(s.intern() == s2);
那么换一段代码
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
这段代码 返回false 。
如果理解了刚刚说的那个过程,就会明白,因为在new的时候,就已经在常量池中放了一个新的对象,这个时候调用 s.intern(); 试图将s放到常量池中,会发现常量池中已经有一个对象了,所有不会将s的引用放到常量池中,会直接返回当前该常量池中暂存的这个字符串对象。
那么看这段代码
String s3 = new String("1") + new String("1");
String s4 = "11";
System.out.println(s3 == s4);
返回结果是false, 因为s3 只是创建了“11”对象,并没有放到常量池。注意,这里和直接new String(“11”) 不一样。
那么如果是
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
返回结果是true
加了 s3.intern(); 之后, 按intern()的效果,如果常量池中没有,那么就将字符串对象的引用放到常量池,因此 s4="11"的时候 取到的是常量池中引用,也就是s3对象的地址, 因此是true。
但是如果是在jdk1.7以前,因为调用intern是拷贝了一份到常量池,因此这个s4的对象 也是另一个的对象,返回是false。
原因是:jdk1.7以前,常量池是在永久代,放入常量池是将对象拷贝了一份到永久代, 而1.7以后常量池是在堆中,放入常量池只是将对象的引用放了一份到常量池里面。
那么问题来了,为什么用+ 拼接的时候,和new 不一样呢? new 的时候就已经将字符串对象尝试放入常量池了。
如果是
String s4 = "11";
String s3 ="1"+"1";
System.out.println(s3 == s4);
编译的时候就会优化成
String s4 = "11";
String s3 ="11";
System.out.println(s3 == s4);
因此就是相同的
如果是
StringBuilder sb = new StringBuilder();
sb.append(new String("1")).append(new String("1"));
String a3 = sb.toString();
a3.intern();
String s4 = "11";
System.out.println(a3 == s4);
这个是等同于
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
看字节码
“+”的实际上就是创建了stringbuild对象,然后调用append的方法连接,然后调用toString方法转为string对象。
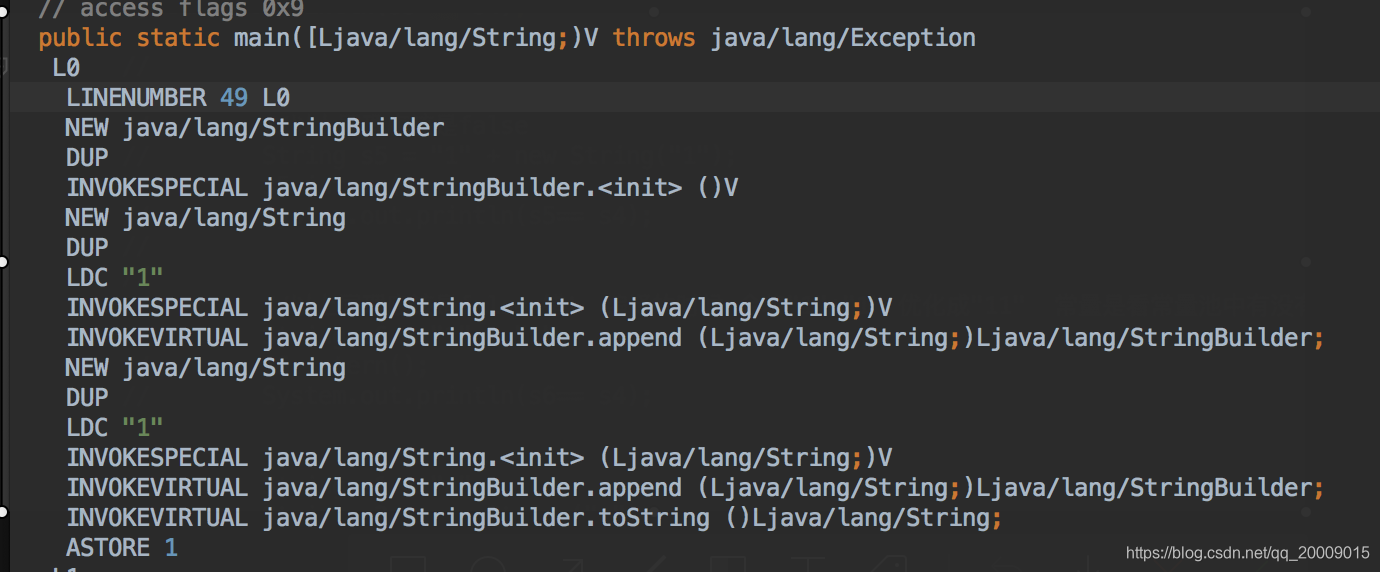
但是toString不会主动放到常量池里面,直接new 则会。
其内部实现
@Override
public String toString() {
return new String(value, 0, count);
}
toString里面 其实是对该String对象的value进行了copy操作
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
正常的new String
例如 new String(“1”), 其在入参的时候 就已经触发了字面量存入常量池的操作,等同于 String xx=“1”, new String(xx);
String s1 = new String(new char[]{'1','1'});
String s4 = "11";
System.out.println(s1 == s4);
输出false
String s1 = new String(new char[]{'1','1'});
s1.intern();
String s4 = "11";
System.out.println(s1 == s4);
输出true
toString里面的new 就等同于以上,创建String对象时候是不会触发去常量池里面的查的。
要想触发去常量池里面查和替换,必须要出现字面量,也就是常量,不管是作为赋值还是作为new String(“字面量”)的参数。
调整下顺序:
String s4 = "11";
String s3 =new String("1") + new String("1");
s3.intern();
System.out.println(s3 == s4);
这样子,返回的就是false了,因为String s4 = "11"; 在执行的时候,是先看下常量池里面有没有,发现没有,就创建了一个对象,并将该对象的引用放到了常量池里面,而调用 s3.intern()的时候,发现常量池里面已经有了常量对象,就是前一步调用String s4 = "11";的时候放入的。 这个时候s3和s4就已经是两个对象了。

















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









