




 本文介绍如何利用pinyin4j库对汉字进行拼音处理,通过排序和字母分组,实现对数据的高效检索。通过实例展示了如何将实体类数据转化为字符串并应用拼音工具,最终输出按照拼音首字母分组的查询结果。
本文介绍如何利用pinyin4j库对汉字进行拼音处理,通过排序和字母分组,实现对数据的高效检索。通过实例展示了如何将实体类数据转化为字符串并应用拼音工具,最终输出按照拼音首字母分组的查询结果。
最终需要实现的效果图如下:
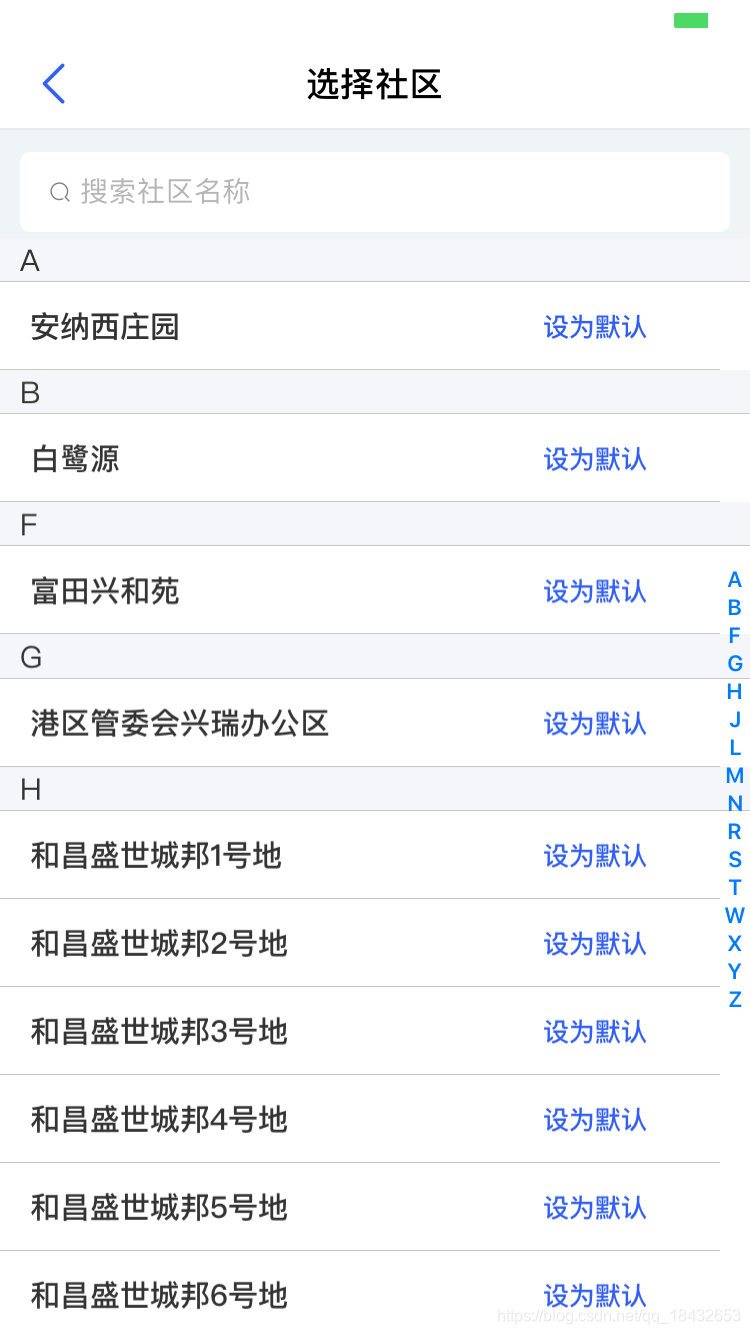
一、实现思路
1、将数据list 进行排序Collections,排序后是按照汉字字母排序的。
2、循环找出26个字母,以字母为key,以list中相同首字母的数据为值(集合)。
二、开发准备
1、这里需要用到pinyin4j-2.5.0.jar这个汉字转拼音的jar包,
大家可点击 pinyin4j-2.5.0.jar 下载我上传到优快云的jar包资源;
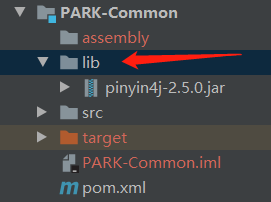
2、将该jar包导入到maven项目中
1)在项目中新建lib文件,将jar包复制粘贴到该文件中
2)在pom文件中进行依赖配置
<dependency>
<groupId>pinyin4j</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.0</version>
<scope>system</scope>
<systemPath>${project.basedir}\lib\pinyin4j-2.5.0.jar</systemPath>
</dependency>三、代码实现
1、这个是汉字转拼音的方法
/**
* 字符串拼音转换工具类
*/
public class PinyinUtil {
/**
* 获取汉字串拼音,英文字符不变
* @param chinese 汉字串
* @return 汉语拼音
*/
public static String getFullSpell(String chinese) {
StringBuffer pybf = new StringBuffer();
char[] arr = chinese.toCharArray();
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.UPPERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < arr.length; i++) {
if (arr[i] > 128) {
try {
pybf.append(PinyinHelper.toHanyuPinyinStringArray(arr[i], defaultFormat)[0]);
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
} else {
pybf.append(arr[i]);
}
}
return pybf.toString();
}
}2、业务代码使用实例
我这边最终返回的是已实体类为主题的数据模型,但是拼音处理工具只能处理字符串,所以我对于这一块进行了转化,采用lambda表达式实现。
public List<a> findParkList(String search){
List<a> b = new ArrayList<>();
//查询所有园区
List<d> list = dMapper.findByCommName(search);
//将园区按照首字母进行分组
if (list != null && list.size() > 0) {
Comparator com = Collator.getInstance(Locale.CHINA);
//按字母排序
Collections.sort(list.stream().map(d::getCommunityName).collect(Collectors.toList()),com);
//输出26个字母
for (int i = 1; i <= 26; i++) {
String word = String.valueOf((char)(96 + i)).toUpperCase();
//循环找出首字母一样的数据
List<d> dList = new ArrayList<>();
for (d e : list) {
String zm = PinyinUtil.getFullSpell(e.getCommunityName()).substring(0,1);
if (word.equals(zm)){
dList.add(e);
}
}
if (dList != null && dList.size() > 0) {
a c = new a();
c.setInitials(word);
c.setFrameParkList(dList);
b.add(c);
}
}
}
return b;
}或参考
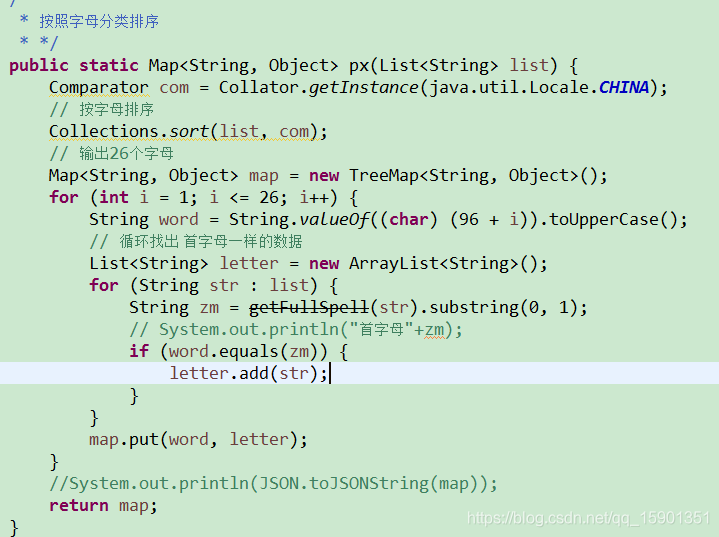
此段代码因涉及到业务代码,部分代码进行了修改处理。
四、测试
调用接口,控制台输出如下
{
"content": [
{
"frameParkList": [
{
"communityName": "安大法官的双方各",
"createName": "",
"datasourceId": "",
"id": "220A2878E078rfvcd1EE899A1E3"
}
],
"initials": "A"
},
{
"frameParkList": [
{
"communityName": "白风风光光",
"createName": "",
"datasourceId": "",
"id": "220A2878E0C14F1EE877A1E3"
}
],
"initials": "B"
}
],
"message": "",
"status": "success"
}#@lehao#
帮助到您请点赞关注收藏谢谢!!


















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











