




 本文深入探讨MySQL的InnoDB存储引擎,分析其关键特性,如插入缓冲、双写缓冲、异步IO和刷新邻接页。详细阐述了SQL执行过程中的事务处理,包括commit和rollback的速度差异,以及如何通过参数调整和优化来提高性能。此外,还讨论了数据库的内存结构、缓存机制、索引工作原理以及如何利用相关指标监控和调整系统状态。
本文深入探讨MySQL的InnoDB存储引擎,分析其关键特性,如插入缓冲、双写缓冲、异步IO和刷新邻接页。详细阐述了SQL执行过程中的事务处理,包括commit和rollback的速度差异,以及如何通过参数调整和优化来提高性能。此外,还讨论了数据库的内存结构、缓存机制、索引工作原理以及如何利用相关指标监控和调整系统状态。
MySQL290题链接:
https://blog.youkuaiyun.com/qq_18312025/article/details/79169903
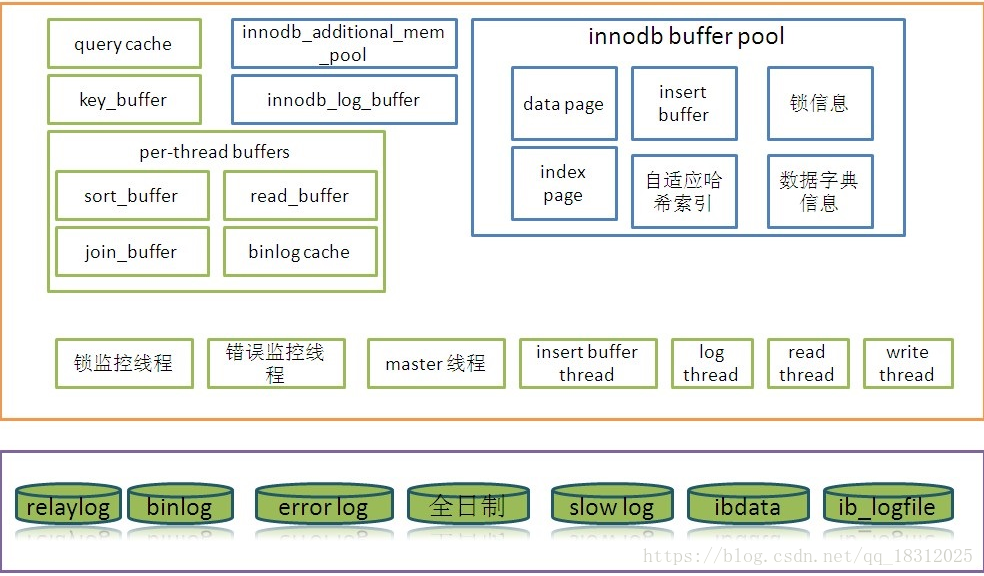
MySQL结构图:
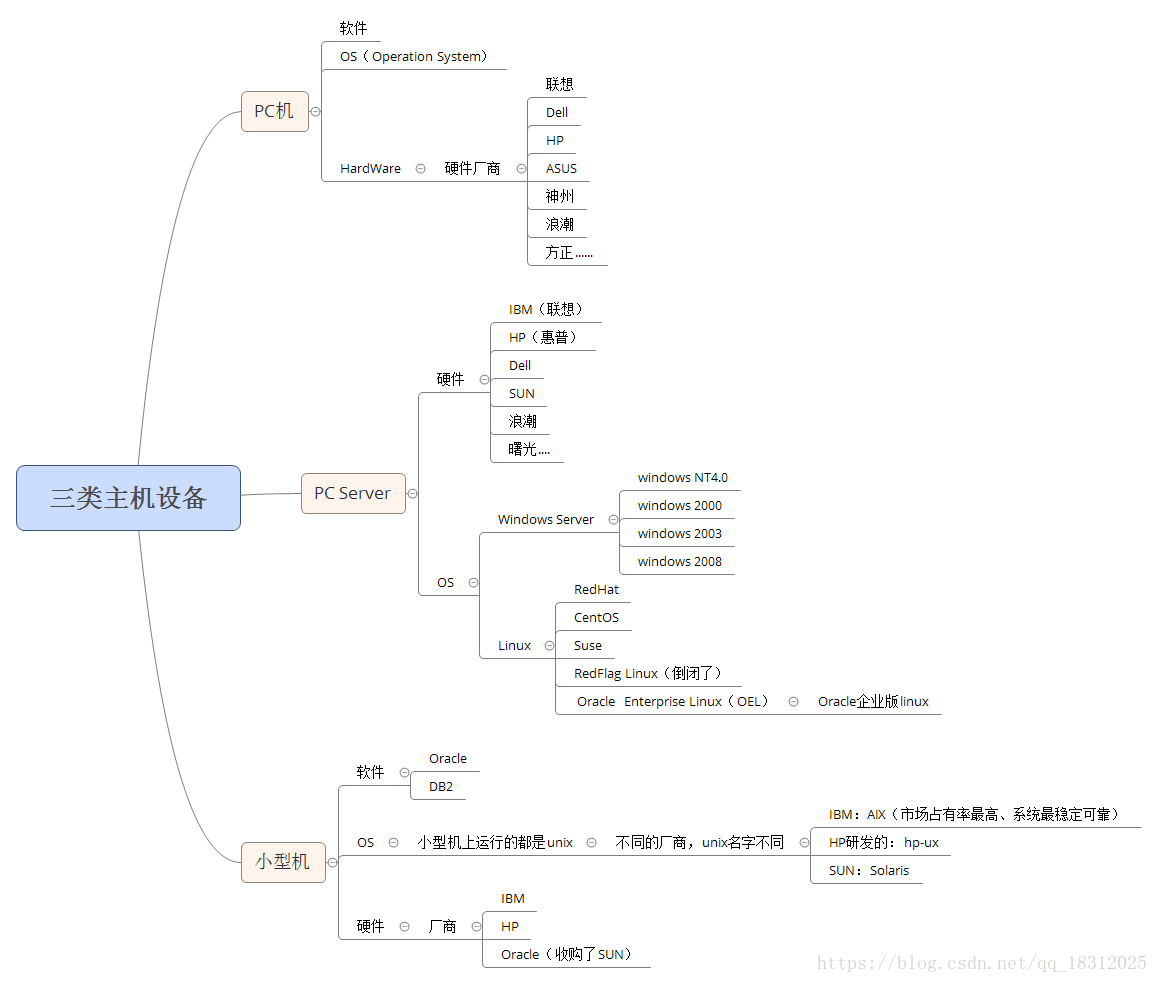
一、IT行业数据库布局分析
答:三类主机设备(图:)
组成DB服务器系统的硬件平台:
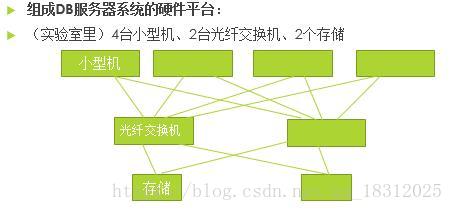
小型机:跑unix、稳定、可靠、贵
小型机可用pc server+linux或pc server+Windows server代替
存储
①EMC:最好的,高端
②HITACHI(日立):日本的,也是高端存储
③IBM
④HP
⑤SUN
⑥DELL
常用数据库:
Oracle:(Oracle)
DB2:(IBM)
SQL SERVER 2014:(Microsoft)
Mysql:(Oracle收购SUN所得)、开源产品,互联网企业大量使用
Postgresql:开源产品、日本人使用的最熟练
Informix:(IBM收购informix所得)
Sybase:(SAP收购Sybase所得)
金融:oracle、db2、informix
运营商:oracle
互联网企业用的数据库:
mysql:很多
oracle:涉及到钱、余额的,一般用oracle;
国内的数据库厂商:
开源封装,informix
华胜天成:中国IT综合服务提供商
南大通用:国内领先的新型数据库产品和解决方案提供商
二、完整的描述sql工作过程中产生的”用户线程建立、工作区分配、内存读、物理读、commit、redo log(日志写)(用户空间)、物理写(为什么说是后台物理写)协同工作。
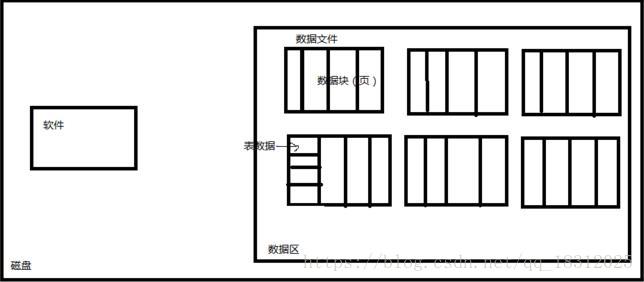
数据区由很多文件组成(如上图:)
数据区的特点:
- 占用空间很大;
- 主要放的是表数据,索引数据
- 数据区由很多数据文件组成
- 数据文件特点:被格式化成一个个的数据块(数据页)(data page),默认16K
- 表数据放在数据页中,以行的形式存放
执行SQL的工作过程(下图:)
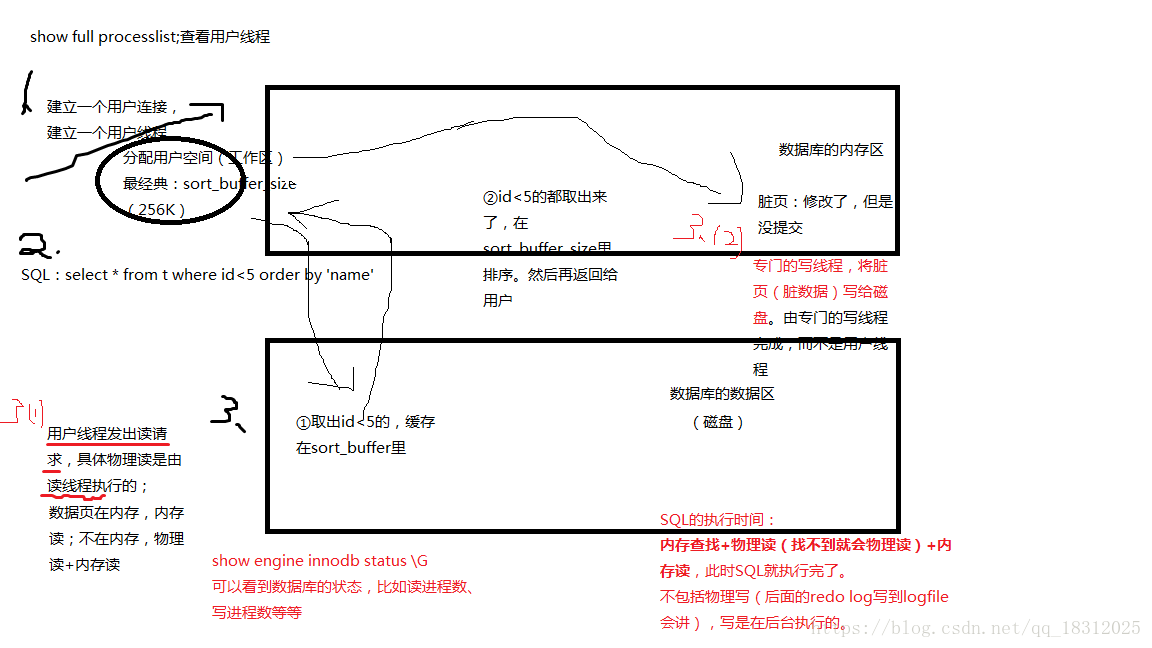
- 建立一个用户连接、建立一个用户线程,分配一个用户空间(每个用户线程都会分配一个sort_buffer)(256K指的是每个线程分配这么大);
- 执行sql,例select、insert、update、delete;
- 访问数据页,select、dml;在内存-》内存读;不在内存–》物理读+内存读。
物理读:
用户线程发出读请求,具体物理读这个动作是由专门的读线程执行的;
用户写线程负责将脏数据(已修改,但未提交的数据)写给磁盘,这个动作是由写线程来完成的,而不是用户线程来完成。
(PS:DML:数据操控语言)
DDL:数据定义语言data Definition language(create、drop、alter)
DML:数据操控语言data Manipulation language(insert、update、delete)
DCL:数据控制语言 data Control language(grant、deny、revoke)
DQL:数据查询语言 data Query language(select)
Redo log:日志本身
Log buffer:日志缓存
Log file:日志文件本身(物理存在–》文件系统–》磁盘)
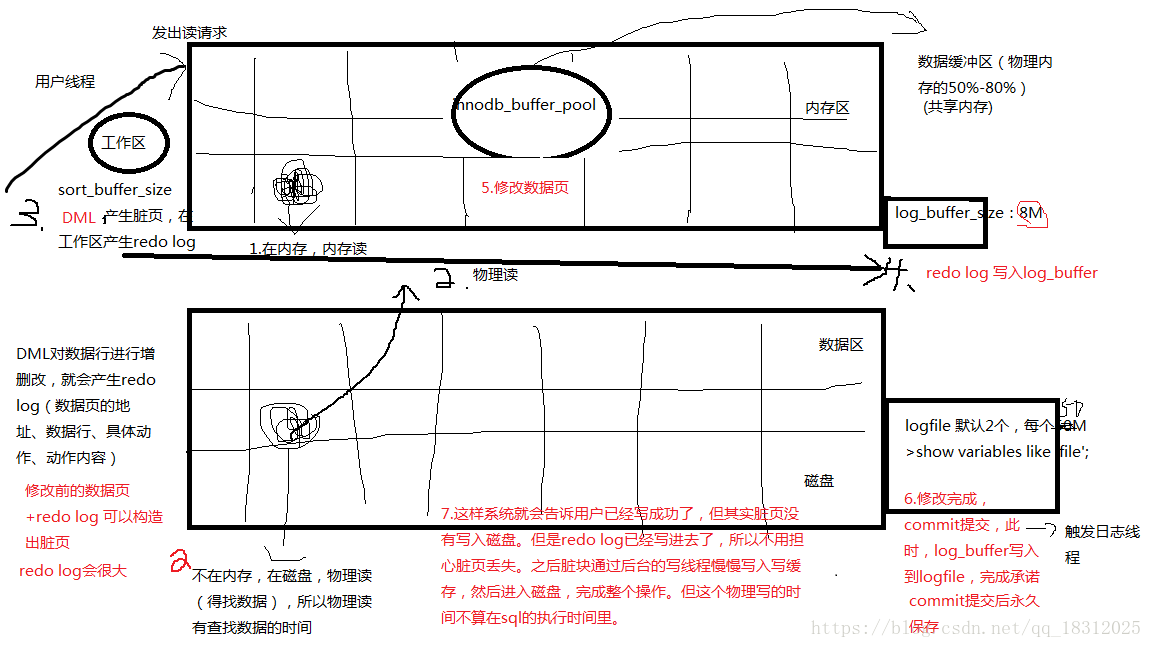
进行DML操作,就会产生redo log(数据页的地址、数据行、具体动作、动作内容),redo log 就会往log buffer写,就算没提交,也会每隔一段时间不断的写,然后log buffer再写到磁盘的logfile里。
redo log会给人感觉修改了N多数据后,提交的时候,非常快!原因:其实只是把redo log写到了磁盘的logfile里,而大量的脏数据其实还没有写到磁盘里,而是在后台慢慢写,但我们并不用担心,因为redo log已经写到logfile里了!!!
(讲解图redo log_logfile:)
三、存储中的缓存和闪存工作机制
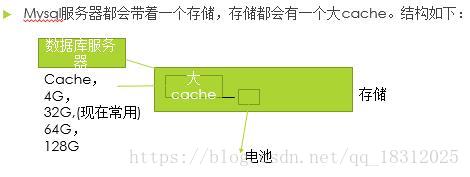
1.mysql服务器基本结构:
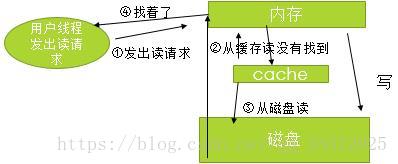
读缓存:从磁盘先读到cache,再从cache读到内存。最后给用户。
读缓存:对读操作原理上是有性能的提升,但是对于数据库系统来说,性能提升不是很明显,特别是系统稳定以后;对于写操作没有性能的提升(写的时候还是直接写到存储中…)
读缓存结构:
写缓存:对写性能有显著提升;对读性能基本上和读缓存差不多。
写缓存结构:
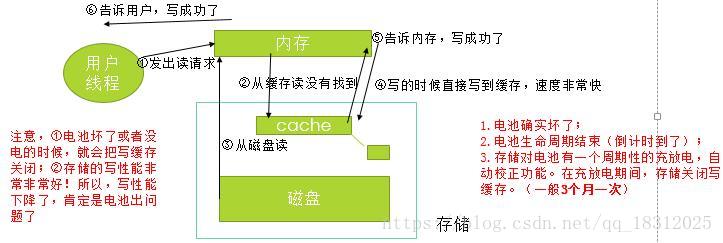
存储的写功能是很强大的,如果写缓存失效,则是因为电池导致写cache被关闭:
1.电池确实坏了;
2.电池生命周期结束(倒计时到了);
3.存储对电池有一个周期性的充放电,自动校正功能。
在充放电期间,存储关闭写缓存。(一般3个月一次)
为什么要充放电?因为cache要知道电池能给自己充多长时间的电啊~
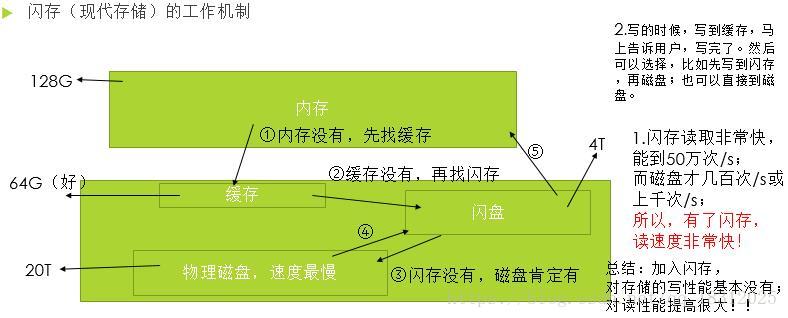
2.闪存(现代存储)工作机制:
四、mysql存储引擎简单描述
引擎/存储引擎 mysql的特色之一
存储引擎:
1.在建立表的时候,会选择存储引擎engine
2.mysql支持多种存储引擎,每一种存储引擎有自己的独立的特色,面向不同的使用场景。
(现在大部分场景在用InnoDB引擎)
show engines;#显示所有引擎,会看到默认的是InnoDB(从mysql5.5)
InnoDB引擎的特点:
1.支持行锁(各干各的活,互补影响)、并发性能好;
2.支持MVCC(多版本并发控制Multi-Version Concurrency Control)(避免使用锁);
3.支持外键;
4.提供一致性非锁定读,并发性能更强;
5.能够使用大内存和充分利用cpu资源。
五、单台服务器上安装两套mysql实例库(可选择相同端口、不同端口)
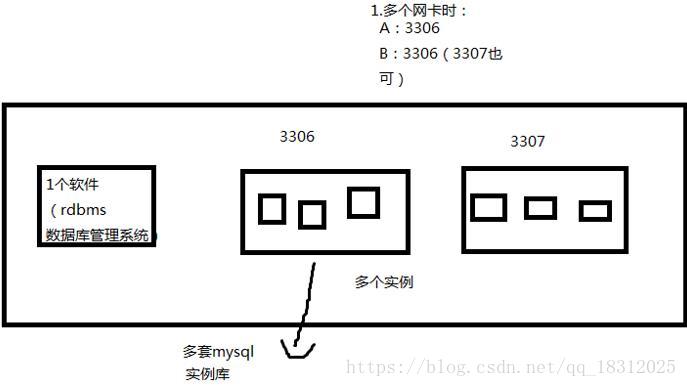
发现这台服务器的资源占用率大约在20%左右(不忙)(正常80%左右最好)。此时,需要加入10个新服务,需要10台服务器:
【在一台mysql服务器上安装2个mysql实例库,可选择相同端口或不同端口】
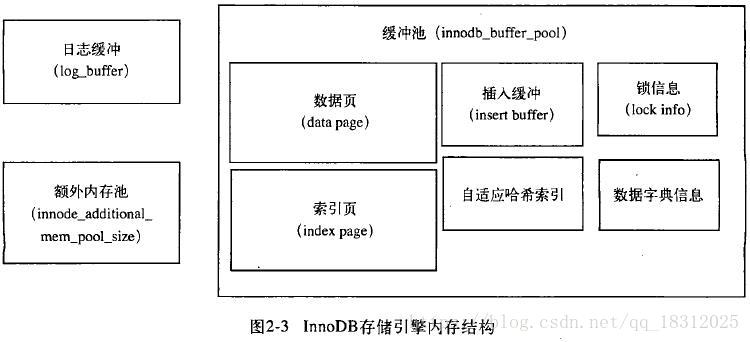
六、绘制innodb引擎的结构图,进行讲解
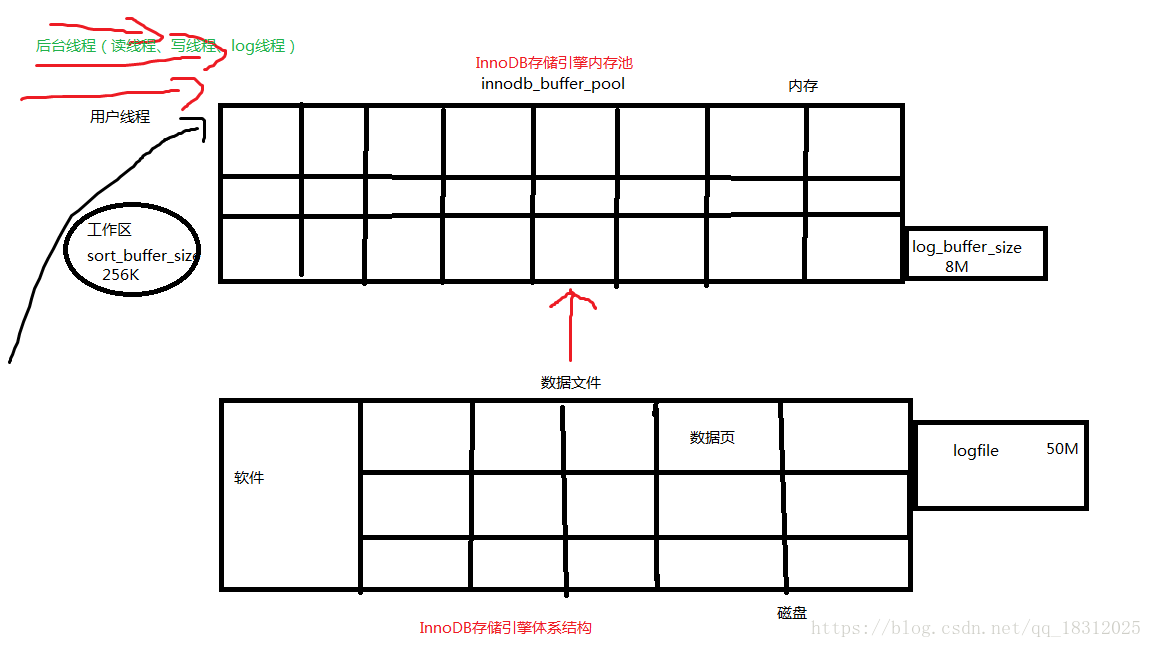
InnoDB存储引擎体系结构讲到了:
- 用户线程
- 后台线程
- 读线程、写线程、log线程
- innodb buffer pool(数据缓存池)
- log buffer
- logfile
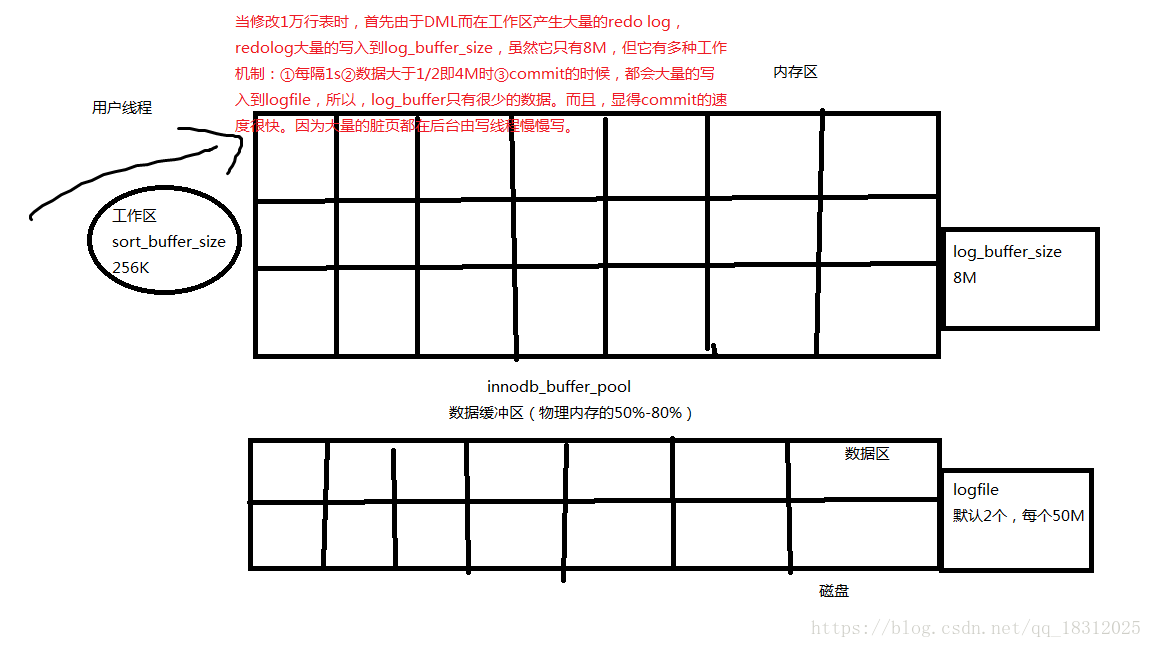
七、详细描述一下commit的过程和rollback的过程,为什么commit速度总是那么快,rollback很多时候执行的很慢,可能非常慢。
根据SQL的完整执行过程来分析:
1.commit的过程很快,为啥?
commit过程很快,当用户要修改一万行表时,首先在工作区sort_buffer_size(256K)产生大量的redo log,redo log大量的写入到log_buffer_size中,但logbuffer很小(8M),存不下大量的redolog,但是logbuffer有很多的工作机制,比如①数据大于4M(1/2)时会写到logfile,②每秒会写入logfile,③commit时也会写入到logfile,但产生的大量脏块是在后台慢慢写入到磁盘的,所以commit时,会感觉速度很快。因为logbuffer中并没有太多的东西。
2.Rollback很多时候执行的很慢,为啥?
答:rollback时,首先要通过命令start TRANSACTION开启一个事务,在这个事务中执行的sql不会commit。所以可以rollback,在rollback时,首先要读取大量的undo,之后在执行sql,这个sql是之前sql相反的操作,之后产生大量的redo,在敲下rollback按下回车时(也就是事物结束之时)会自动回滚并且自动co
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











