



 本文指出Pandas是Numpy的升级版本,核心数据类型有Series和DataFrame,重点介绍了Series类型。阐述了其由data和index构成,介绍了三种创建Series对象的方式,还提及创建时元素顺序问题及解决办法,最后说明了Series元素的三种访问方法。
本文指出Pandas是Numpy的升级版本,核心数据类型有Series和DataFrame,重点介绍了Series类型。阐述了其由data和index构成,介绍了三种创建Series对象的方式,还提及创建时元素顺序问题及解决办法,最后说明了Series元素的三种访问方法。
0.摘要
Pandas相当于是Numpy的升级版本。在numpy中,核心的数据类型为ndarray;而在Pandas中,核心的数据核心Series和DataFrame。本文主要介绍pandas库中的Series类型。
1.Series类型简介
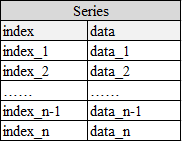
Series类型主要由两部分构成:data和index构成。每个index对应一个data,这种对应方式与字典类似,但Series更加灵活。
2.Series对象的创建
方式一:直接创建
import pandas as pd
s1 = pd.Series([1, 2, 3, 4, 5, 6])
print(s1)

得到的是一个两列的数据。第二列是创建Series对象时,所用的列表。第一列则是pandas默认生成的index。
方式二:指点index
pandas创建的默认index值,为以0为起点的数组。如果不想采用默认的index,也可以在创建的时候指定。
s2 = pd.Series([1, 2, 3, 4, 5, 6], index=['a', 'b', 'c', 'd', 'e', 'f'])
print(s2)
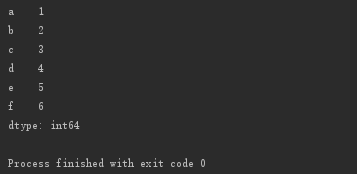
此时,index值变成了指定的索引列表。
方式三:使用字典
dict1 = {'a':1, 'c':3, 'b':2, 'd':4, 'e':5, 'f':6}
s3 = pd.Series(dict1)
print(s3)
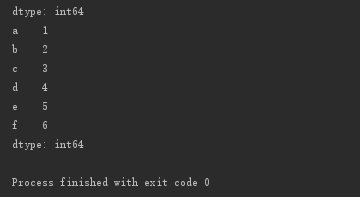
可以看出,pandas自动地将dict.keys作为Series.index,将dict.values作为Series.data。
但是,读者可能会考虑到,字典是无序的。那么pandas是如何处理元素顺序的问题呢?
读者可能也注意到,在例子中,dict1故意将'b':2和‘c’:3的顺序颠倒了一下,但pandas输出的顺序依然不变。
因此,使用字典创建Series方法,要注意元素顺序的问题。较好的解决方法是,额外添加一个index列表。
dict1 = {'a':1, 'c':3, 'b':2, 'd':4, 'e':5, 'f':6}
s3 = pd.Series(dict1, index=['a', 'b', 'c', 'd', 'e', 'f'])
print(s3)
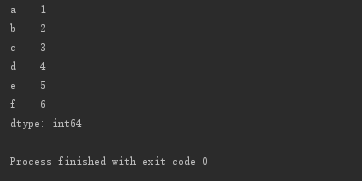
如果,后指定的index与字典中的keys不一致,python并不会报错。python对于index中不存在的项会忽略,对于index中多出来的项会设置为NaN。
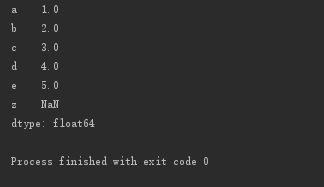
dict1 = {'a':1, 'c':3, 'b':2, 'd':4, 'e':5, 'f':6}
s3 = pd.Series(dict1, index=['a', 'b', 'c', 'd', 'e', 'z'])
print(s3)
3.Series元素的访问
Series对象的访问有三种方法:
方法一:属性访问:
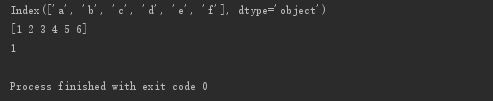
print(s3.index)
print(s3.values)
print(s3.values[0])
方法二:指定索引值
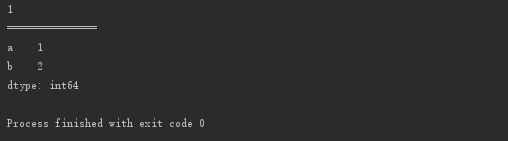
print(s3['a'])
print("===============")
print(s3[['a', 'b']])
方法三:数字索引值、切片索引
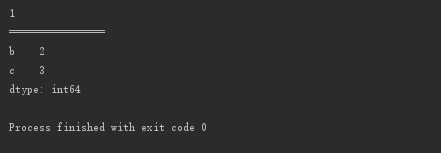
print(s3[0])
print("================")
print(s3[1:3])

















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









