




 本文详细介绍了Spring IoC容器中Bean的生命周期,从实例化、依赖注入到销毁的各个阶段,包括 Aware 接口、BeanPostProcessor、InitializingBean 和 destroy-method 的应用。同时,讨论了Vue项目上线前的准备工作,如配置反向代理、打包和部署。在数据库方面,讲解了Oracle中的数据清理、表分析以及快速删除大量数据的方法。此外,深入探讨了Spring事务管理的隔离级别和传播行为,以及事务失效的常见场景。最后,提到了Java集合的扩容机制和CPU100%问题的排查步骤。
本文详细介绍了Spring IoC容器中Bean的生命周期,从实例化、依赖注入到销毁的各个阶段,包括 Aware 接口、BeanPostProcessor、InitializingBean 和 destroy-method 的应用。同时,讨论了Vue项目上线前的准备工作,如配置反向代理、打包和部署。在数据库方面,讲解了Oracle中的数据清理、表分析以及快速删除大量数据的方法。此外,深入探讨了Spring事务管理的隔离级别和传播行为,以及事务失效的常见场景。最后,提到了Java集合的扩容机制和CPU100%问题的排查步骤。
spring生命周期
对于普通的Java对象,当new的时候创建对象,当它没有任何引用的时候被垃圾回收机制回收。而由Spring IoC容器托管的对象,它们的生命周期完全由容器控制。Spring中每个Bean的生命周期如下:
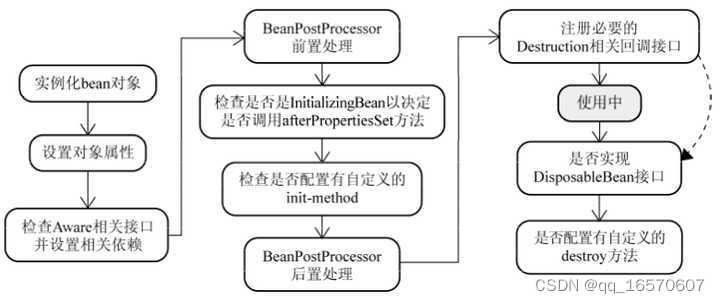
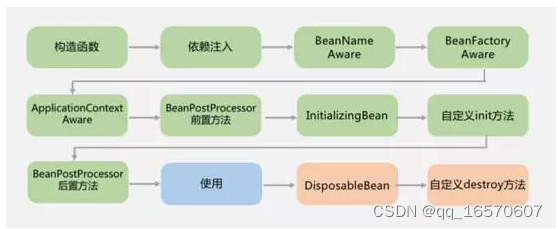
1、实例化Bean
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。
对于ApplicationContext容器,当容器启动结束后,便实例化所有的bean。
容器通过获取BeanDefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。
实例化对象被包装在BeanWrapper对象中,BeanWrapper提供了设置对象属性的接口,从而避免了使用反射机制设置属性。
2、 设置对象属性(依赖注入)
实例化后的对象被封装在BeanWrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。
紧接着,Spring根据BeanDefinition中的信息进行依赖注入。
并且通过BeanWrapper提供的设置属性的接口完成依赖注入。
3、注入Aware接口
紧接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给bean。
4、BeanPostProcessor
当经过上述几个步骤后,bean对象已经被正确构造,但如果你想要对象被使用前再进行一些自定义的处理,就可以通过BeanPostProcessor接口实现。
该接口提供了两个函数:
-
postProcessBeforeInitialzation( Object bean, String beanName )
当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。
这个函数会先于InitialzationBean执行,因此称为前置处理。
所有Aware接口的注入就是在这一步完成的。 -
postProcessAfterInitialzation( Object bean, String beanName )
当前正在初始化的bean对象会被传递进来,我们就可以对这个bean作任何处理。
这个函数会在InitialzationBean完成后执行,因此称为后置处理。
5、InitializingBean与init-method
当BeanPostProcessor的前置处理完成后就会进入本阶段。
InitializingBean接口只有一个函数:
afterPropertiesSet()
这一阶段也可以在bean正式构造完成前增加我们自定义的逻辑,但它与前置处理不同,由于该函数并不会把当前bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。
若要使用它,我们需要让bean实现该接口,并把要增加的逻辑写在该函数中。然后Spring会在前置处理完成后检测当前bean是否实现了该接口,并执行afterPropertiesSet函数。
当然,Spring为了降低对客户代码的侵入性,给bean的配置提供了init-method属性,该属性指定了在这一阶段需要执行的函数名。Spring便会在初始化阶段执行我们设置的函数。init-method本质上仍然使用了InitializingBean接口。
6、DisposableBean 和 destroy-method
和init-method一样,通过给destroy-method指定函数,就可以在bean销毁前执行指定的逻辑。
Vue项目部署上线
上线前准备
1、先在vue.config.js文件中配置反向代理解决跨域请求问题
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({
transpileDependencies: true,
devServer: {
proxy: {
"/api": {
target: "后端url地址",
//允许跨域请求
changeOrigin: true
}
}
}
})
2、在vue项目根目录运行 npm run build
打包完成后会在根目录生成dist文件夹,这个dist文件夹需要上传到服务器
3、链接云服务器,在 /usr/local/ 下创建 web文件夹 用来存放dist文件夹
//此时已经连接到云服务器
cd /usr/local/
mkdir web
4、修改nginx配置
cd /usr/local/nginx/conf
vim nginx.conf
执行上面两条命令后进入nginx配置
按i键进入编辑模式
修改配置
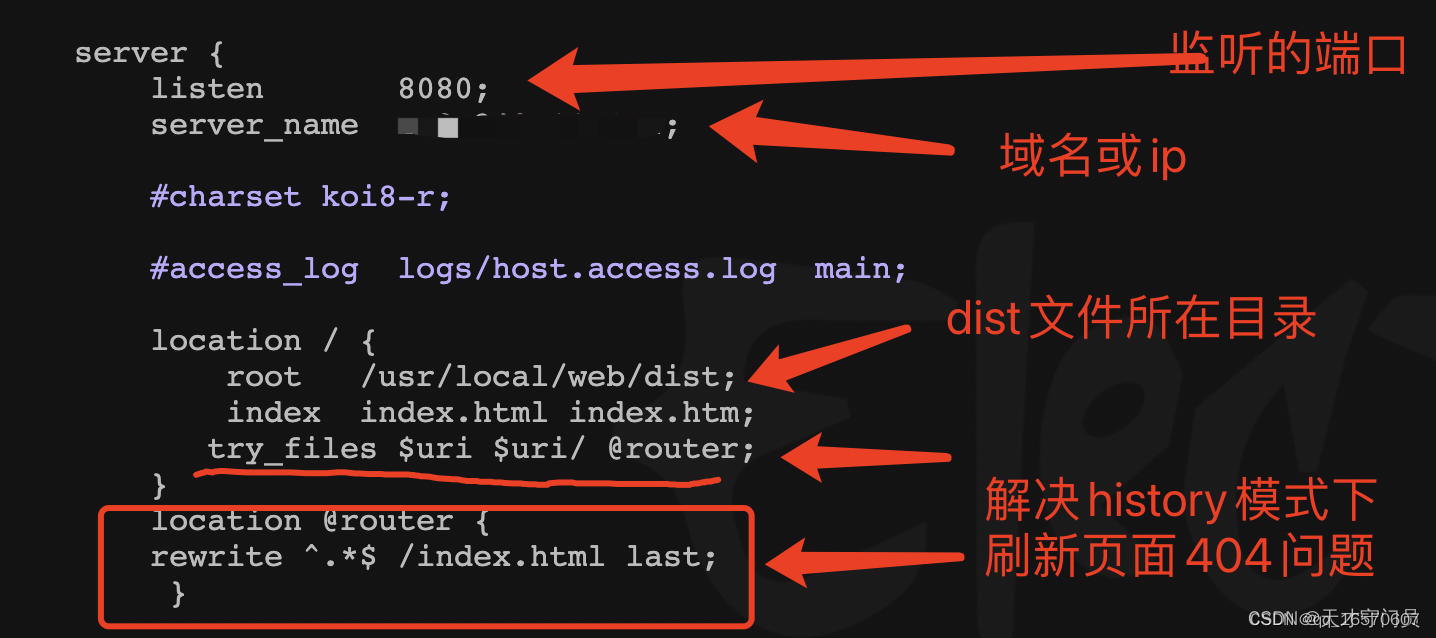
修改完成后以此按 esc键 :wq 保存设置
启动nginx
cd /usr/local/nginx/sbin
./nginx
预览运行效果
@service @repository和@component的本质区别
@component是通用性的注解,@service 和@repository则是在@component的基础上添加了特定的功能。
所以@component可以替换为@service和@repository,但是为了规范,服务层bean用@service,dao层用@repository。就好比代码规范,变量、方法命名一样。还有一点,正如文档描述那样:
@Repository的工作是捕获特定于平台的异常,并将它们作为Spring统一未检查异常的一部分重新抛出。为此,提供了PersistenceExceptionTranslationPostProcessor。
如果在dao层使用@service,就不能达到这样的目的。
Java项目启动时执行指定方法的几种方式
第一种:使用注解 @PostConstruct
作用于方法上面:类加载后执行,不依赖于项目的启动,经常可以看到项目未启动成功该方法就已经执行了
@Component
public class PostConstruct {
@PostConstruct
public void test() {
System.out.println("PostConstruct:开始运行...");
}
}
第二种:实现 CommandLineRunner 接口
在服务启动后执行
@Component
public class Start implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("CommandLineRunner:开始运行...");
}
}
第三种:实现 ApplicationRunner 接口
@Component
public class Start1 implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("ApplicationRunner:开始运行...");
}
}
以上三种方式都是在项目启动的时候加载指定的方法,第一种使用的是 注解的方式,第二种、第三种使用的是实现接口的方式。
它们的执行顺讯为 @PostConstruct—》ApplicationRunner—》CommandLineRunner。
CommandLineRunner 和 ApplicationRunner 的作用都是用于项目启动后进行数据的初始化。如有多个Runner的话,可以使用 @Order(value = 1)指定运行的顺序。 数字越小越早运行。
@PostConstruct:在Spring实例化该Bean之后马上执行此方法,之后才会去实例化其他Bean
orcl 如何快速删除表中百万或千万数据
orcl 数据库表中数据达到上千万时,已经变的特别慢了,所以时不时需要清掉一部分数据。
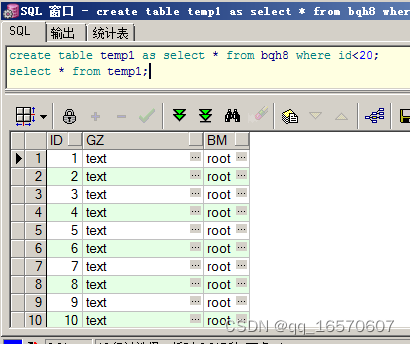
bqh8表中目前有10000000条数据,需要保留19条数据,其余全部清除掉。
1、首先把需要保留的数据备份到temp1临时表中。
create table temp1 as select * from bqh8 where id<20;
select * from temp1;
2、然后再用truncate删除整个表的数据。
truncate table bqh8;
select * from bqh8;
oracle 表分析实现
DBMS_STATS常用方法(收集oracle信息)
-- 收集表信息
EXEC DBMS_STATS.gather_table_stats(‘SCOTT’, ‘EMPLOYEES’);
-- 收集index信息
EXEC DBMS_STATS.gather_index_stats(‘SCOTT’, ‘EMPLOYEES_PK’);
/**
* 表或索引分析执行者
*
* @param createTime
* 表分析日志创建时间
* @param table
* 表名称
* @param index
* 索引名称
* @param partitionName
* 分区名称
* @param analysisNameString
* 表所属用户
* @return
*/
private static String excuteAnalyze(String createTime, String table, String index, String partitionName,
String analysisNameString) {
// 拼接表分析sql语句
StringBuilder sqlBuilder = new StringBuilder();
String tableorindex = "";
sqlBuilder.append("BEGIN ");
if (StringUtils.isNotBlank(table)) {
sqlBuilder.append("DBMS_STATS.GATHER_TABLE_STATS ( ");
sqlBuilder.append("ownname =>'" + analysisNameString + "', ");
sqlBuilder.append("tabname => '" + table + "', ");
tableorindex = table;
// 判断分区名称是否为空,若不为空则拼接分区
if (StringUtils.isNotBlank(partitionName)) {
sqlBuilder.append("partname => '" + partitionName + "', ");
}
sqlBuilder.append("granularity => 'PARTITION', ");
sqlBuilder.append("cascade => TRUE, ");
} else {
sqlBuilder.append("DBMS_STATS.GATHER_INDEX_STATS ( ");
sqlBuilder.append("ownname =>'" + analysisNameString + "', ");
sqlBuilder.append("indname => '" + index + "', ");
tableorindex = index ;
}
sqlBuilder.append("degree => 4, ");
sqlBuilder.append("estimate_percent => 100, ");
sqlBuilder.append("no_invalidate => FALSE); ");
sqlBuilder.append("END;");
String sql = sqlBuilder.toString();
AppLogger.info(sql);
Connection conn = null;
try {
conn = DBConnProvider.getConnection();
AppLogger.info("开始执行:" + tableorindex + "表分析");
conn.createStatement().execute(sql);
updateAnalyzeLog(tableorindex, createTime, true);
AppLogger.info(tableorindex + "表分析完成");
return "02";
} catch (Exception e) {
updateAnalyzeLog(tableorindex, createTime, false);
AppLogger.info(e.getMessage());
return "03";
}
}
MyBatis中井号与美元符号的区别
-
#{变量名}可以进行预编译、类型匹配等操作,#{变量名}会转化为jdbc的类型。
select * from tablename where id = #{id}假设id的值为12,其中如果数据库字段id为字符型,那么#{id}表示的就是’12’,如果id为整型,那么id就是12,并且MyBatis会将上面SQL语句转化为jdbc的select * from tablename where id=?,把?参数设置为id的值。
-
${变量名}不进行数据类型匹配,直接替换。
select * from tablename where id = ${id}如果字段id为整型,sql语句就不会出错,但是如果字段id为字符型, 那么sql语句应该写成select * from table where id = ‘${id}’。
-
#方式能够很大程度防止sql注入。
-
$方式无法防止sql注入。
-
$方式一般用于传入数据库对象,例如传入表名。
-
尽量多用#方式,少用$方式。
spring事务的隔离级别
隔离级别是指若干个并发的事务之间的隔离程度,与我们开发时候主要相关的场景包括:脏读取、重复读、幻读。
- DEFAULT :这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是: READ_COMMITTED 。
- READ_UNCOMMITTED :该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。
- READ_COMMITTED :该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
- REPEATABLE_READ :该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。
- SERIALIZABLE :所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
@Transactional(isolation = Isolation.DEFAULT)
spring的事务传播行为意义何在?
例如事务之间的交互,比如A事务失败了,会不会影响B事务,A事务捕获B事务的异常,这时候应该怎么办,要不要回滚,还有一些其他情况,这些都需要spring事务传播行为的支持。
说得通俗一点就是多个具有事务控制的service的相互调用时所形成的复杂的事务边界控制。
- REQUIRED :如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。(如果被调用端发生异常,那么调用端和被调用端事务都将回滚)
- SUPPORTS :如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- MANDATORY :如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW :创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- NOT_SUPPORTED :以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- NEVER :以非事务方式运行,如果当前存在事务,则抛出异常。
- NESTED :如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED 。
@Transactional(propagation = Propagation.REQUIRED)
Spring中常用的事务传播行为
两个常用的有:
Propagation.REQUIRED(增删改):使用原来的事务,有事务的方法中,出现异常,数据进行回滚,整体的数据都查不到。一荣俱荣一损俱损。
Propagation.REQUIRES_NEW: 有事务的方法中,如果子方法事务方式为REQUIRES_NEW,将原来的事务挂起,开启一个新的事务,两个隔离开,一个事务成功,另一个事务出现异常,成功的会查出,异常的将回滚。
springboot中使用事务
首先在启动类中添加注解,开启事务管理器
@EnableTransactionManagement
然后在service的实现方法上添加注解
@Transactional(rollbackFor = CustomException.class)
spring事务失效的场景
常见的事务失效场景有:自调用,异常被吃,异常抛出类型不对。
自身调用
来看两个示例:
@Service
public class OrderServiceImpl implements OrderService {
public void update(Order order) {
updateOrder(order);
}
@Transactional
public void updateOrder(Order order) {
// update order;
}
}
update方法上面没有加 @Transactional 注解,调用有 @Transactional 注解的 updateOrder 方法,updateOrder 方法上的事务管用吗?
再来看下面这个例子:
@Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void update(Order order) {
updateOrder(order);
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void updateOrder(Order order) {
// update order;
}
}
这次在 update 方法上加了 @Transactional,updateOrder 加了 REQUIRES_NEW 新开启一个事务,那么新开的事务管用么?
这两个例子的答案是:不管用!
因为它们发生了自身调用,就调该类自己的方法,而没有经过 Spring 的代理类,默认只有在外部调用事务才会生效,这也是老生常谈的经典问题了。
这个的解决方案之一就是在的类中注入自己,用注入的对象再调用另外一个方法。
异常被吃
@Service
public class OrderServiceImpl implements OrderService {
@Transactional
public void updateOrder(Order order) {
try {
// update order;
}catch (Exception e){
//do something;
}
}
}
把异常吃了,然后又不抛出来,事务就不生效了。
MAT使用教程
生成内存文件:
- 加 jvm启动参数,当发生OutOfMemoryError时,机器会自动dump内存快照
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=$LOG_DIR/java.hprof"
- 手动生成,通过执行jdk自带命令
jmap -dump:format=b,file=heap.bin <pid>
接下就可以用 MAT打开转换后的 hprof文件
打开后的首页,里面是一些堆的基本概要信息,比如空间大小、类的数量、对象实例数量、类加载器等等。
Atcion里面提供了多种分析维度:
- Histogram可以列出内存中的对象,对象的个数以及大小。
- Dominator Tree可以列出那个线程,以及线程下面的那些对象占用的空间。
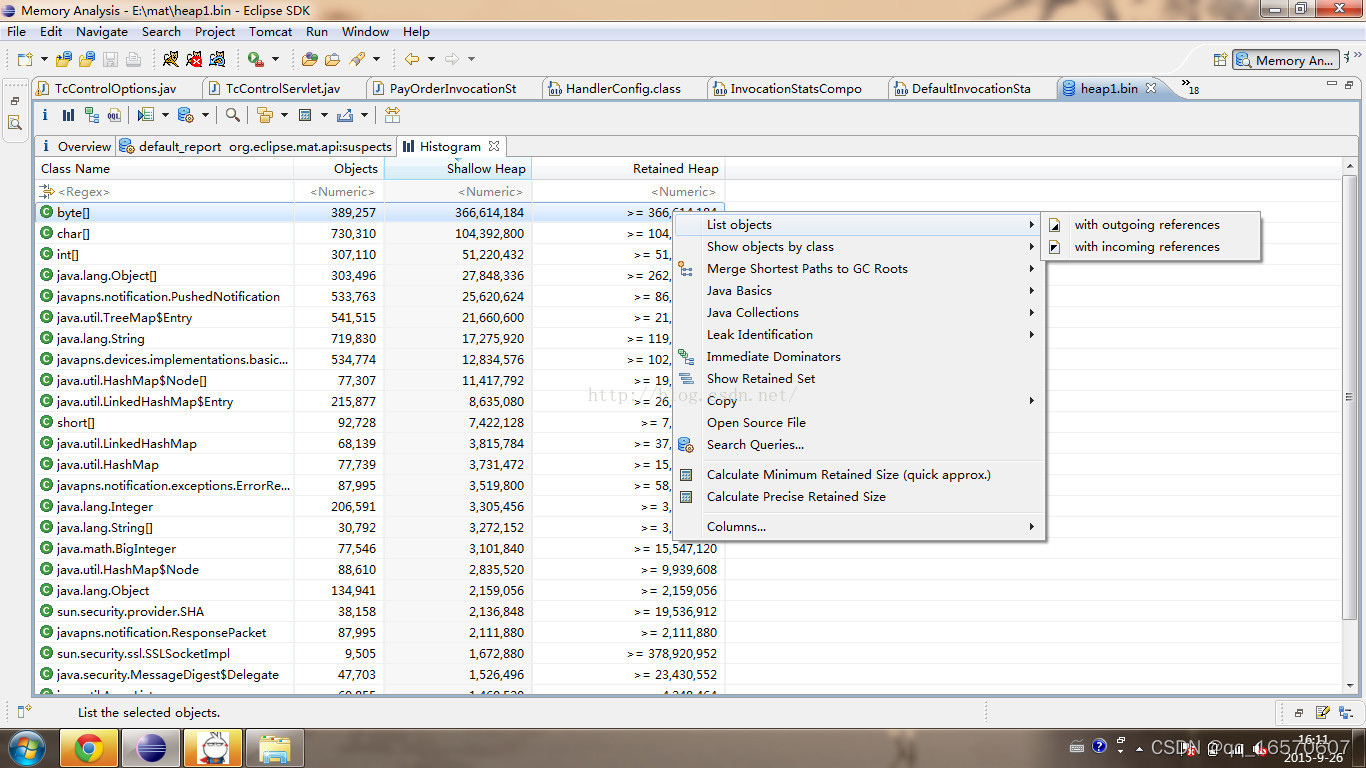
Histogram
它按类名将所有的实例对象列出来,点击表头(Class Name)可以排序,第一行输入正则表达式可以过滤筛选 ;
Shallow Heap :一个对象内存的消耗大小,不包含对其他对象的引用;
Retained Heap :是shallow Heap的总和,也就是该对象被GC之后所能回收的内存大小;
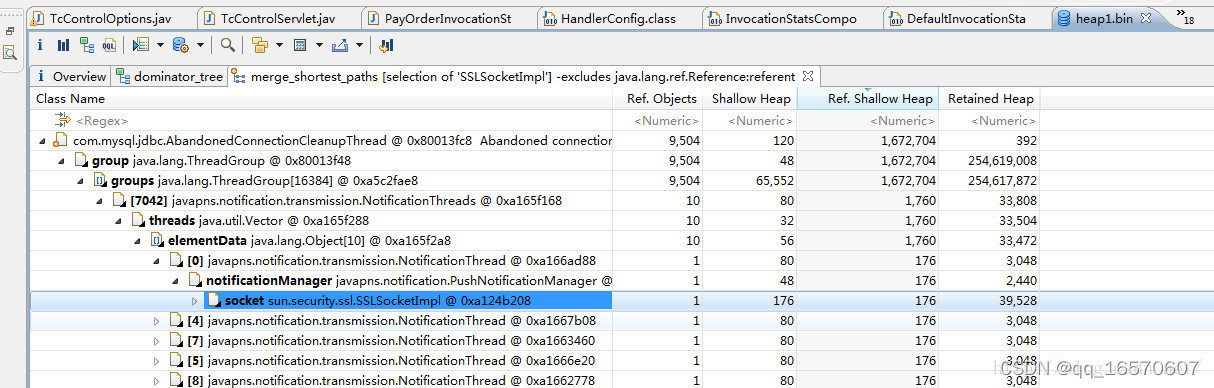
Dominator Tree
可以列出内存中存活的大对象列表,优点是有Percentage字段,可以看各种情况的百分比。

快速找出某个实例没被释放的原因,可以右健 Path to GC Roots–>exclude all phantom/weak/soft etc. references
,它展示了对象间的引用关系。

步骤总结

生产出现OOM,如何排查
-
使用dmesg命令查看系统日志
dmesg |grep -E ‘kill|oom|out of memory’,可以查看操作系统启动后的系统日志,这里就是查看跟内存溢出相关联的系统日志。
-
这时候,需要启动项目,使用ps命令查看进程
ps -aux|grep java命令查看一下你的java进程,就可以找到你的java进程的进程id。
-
接着使用top命令
top命令显示的结果列表中,会看到%MEM这一列,这里可以看到你的进程可能对内存的使用率特别高。以查看正在运行的进程和系统负载信息,包括cpu负载、内存使用、各个进程所占系统资源等。
-
使用jstat命令
用jstat -gcutil 20886 1000 10命令,就是用jstat工具,对指定java进程(20886就是进程id,通过ps -aux | grep java命令就能找到),按照指定间隔,看一下统计信息,这里会每隔一段时间显示一下,包括新生代的两个S0、s1区、Eden区,以及老年代的内存使用率,还有young gc以及full gc的次数。
使用 jstat -gcutil 8968 500 5 表示每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印5次。
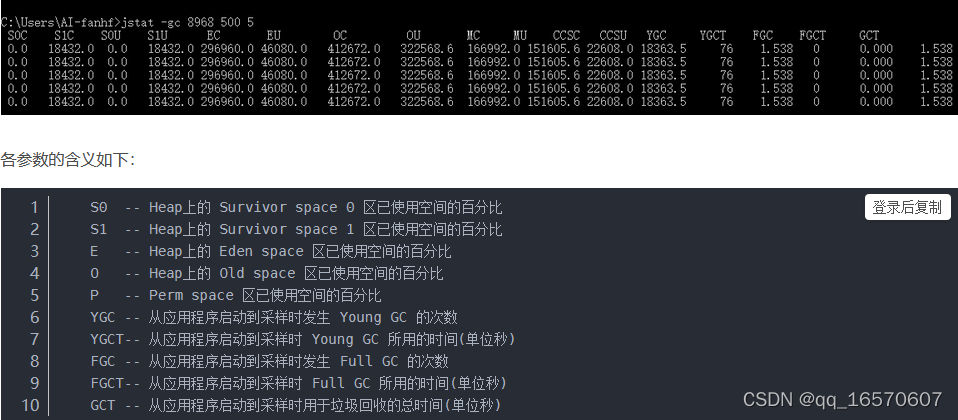
一般来说大量的对象涌入内存,结果始终不能回收,会出现的情况就是,快速撑满年轻代,然后young gc几次,根本回收不了什么对象,导致survivor区根本放不下,然后大量对象涌入老年代。老年代很快也满了,然后就频繁full gc,但是也回收不掉。然后对象持续增加不就oom了,内存放不下了,就爆了。
所以jstat先看一下基本情况,马上就能看出来,其实就是大量对象没法回收,一直在内存里占据着,然后就差不多内存快爆了。
线程池ThreadPoolExecutor的核心线程数,最大线程数,队列长度的关系?
关于线程池的几个参数,很多人不是很清楚如何配置,他们之间是什么关系,我用代码来证明一下。
public class ThreadPool {
public static void main(String[] args) {
// 创建线程池 , 参数含义 :(核心线程数,最大线程数,加开线程的存活时间,时间单位,任务队列长度)
ThreadPoolExecutor pool = new ThreadPoolExecutor(5, 8,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(2));
//设置a的值范围在:a = (corePoolSize-1) ~ (max+queue+1) ,分析:任务数 与 活跃线程数,核心线程数,队列长度,最大线程数的关系。
int a = 7;
for (int i = 1; i <= a; i++) {
int j = i;
pool.submit(new Runnable() {
@Override
public void run() {
//获取线程名称
Thread thread = Thread.currentThread();
String name = thread.getName();
//输出
int activeCount = pool.getActiveCount();
System.out.println("任务:"+j+"-----,线程名称:"+name+"-----活跃线程数:"+activeCount);
}
});
}
//关闭线程池
pool.shutdown();
}
}
输出结果,观察关系:
//任务数 a = 4 , 活跃线程数4 , 任务数 < 核心线程数。
//任务数 a = 5 , 活跃线程数5 , 任务数 = 核心线程数。
//任务数 a = 6 , 活跃线程数5 , 任务数 < 核心线程数5 + 队列长度2 。
//任务数 a = 7 , 活跃线程数5 , 任务数 = 核心线程数5 + 队列长度2 。
//任务数 a = 8 , 活跃线程数6 , 任务数 < 最大线程数8 + 队列长度2 . 活跃线程数是在核心线程数5的基础上.加1个活跃线程。
//任务数 a = 9 , 活跃线程数7 , 任务数 < 最大线程数8 + 队列长度2. 活跃线程数是在核心线程数5的基础上.加2个活跃线程。
//任务数 a = 10 , 活跃线程数8 , 任务数 = 最大线程数8 + 队列长度2. 活跃线程数是在核心线程数5的基础上.加3个活跃线程。
//任务数 a = 11 , 活跃线程数8 , 任务数 > 最大线程数8 + 队列长度2 。抛出异常RejectedExecutionException
总结:
-
随着任务数量的增加,会增加活跃的线程数。
-
当活跃的线程数 = 核心线程数,此时不再增加活跃线程数,而是往任务队列里堆积。
-
当任务队列堆满了,随着任务数量的增加,会在核心线程数的基础上加开线程。
-
直到活跃线程数 = 最大线程数,就不能增加线程了。
-
如果此时任务还在增加,则: 任务数11 > 最大线程数8 + 队列长度2 ,抛出异常RejectedExecutionException,拒绝任务。
SQL执行计划重点参数查看
type
优化sql的重要字段,也是我们判断sql性能和优化程度的重要指标。
他的取值类型范围:
- const:通过索引一次命中,匹配一行数据
- system:表中只有一行记录,相当于系统表
- eq_ref: 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配
- ref:非唯一性索引扫描,返回匹配某个值的所有
- range:只检索给定范围的行,使用一个索引来选择行,一般用between、<、>;
- index: 只遍历索引树
- ALL: 表示全表扫描,这个类型的查询是性能最差的查询之一。那么基本就是随着表的数量增多,执行效率越慢。
执行效率:
ALL < index < range < ref < eq_ref < const < system。最好是避免ALL和index。
extra
- using filesort: 表示mysql对结果集进行外部排序,不能通过索引排序达到排序效果。一般有using filesort都建议优化去掉,因为这样查询cpu资源消耗大,延时大。
- using index: 覆盖索引扫描,表示查询在索引树中就可查找所需数据,不用扫描表数据文件,往往说明性能不错。
- using temporary: 查询有使用临时表,一般出现于排序,分组和多表join的情况,查询效率不高,建议优化。
- using where: sql使用了where过滤,效率较高。
dubbo和spring cloud的区别?
- spring cloud是http restful,返回是json数据,经常出现别的部门服务提供方修改了返回的DTO对象字段,造成服务使用方调用后无数据,也不报错。因为json字段对不上不会报错,也没数据。
- dubbo的服务提供方返回对象DTO要上传maven,并在服务使用方进行依赖,这样服务使用方在使用时只需引入maven依赖包。如果服务方升级dto字段,使用方没升级就会直接抛异常,这样就知道原因了。
- 最大的区别:Dubbo底层是使用Netty这样的NIO框架,是基于TCP协议传输的,配合以Hession序列化完成RPC通信。而SpringCloud是基于Http协议+rest接口调用远程过程的通信。
dubbo的好处:
- 数据传输方式:多数RPC框架选择TCP作为传输协议,性能比较好。
- 数据传输内容:请求方需要告知需要调用的函数的名称、参数、等信息。
- 序列化方式:客户端和服务端交互时将参数或结果转化为字节流在网络中传输,那么数据转化为字节流的或者将字节流转换成能读取的固定格式时就需要进行序列化和反序列化。
- dubbo由于是二进制的传输,占用带宽会更少。
为什么TCP的性能比http快?
- tcp比http快,是因为发送同样的有效数据,http比tcp多封装一次,也就是硬件实际要发送的数据量更大,那么自然耗时更多。
- tcp是传输层协议OSI第四层。http是应用层协议OSI第七层。

java集合扩容机制
HashTable
- 初始size为11,扩容:newsize = olesize*2+1;
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length。
HashMap
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂;
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入;
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀;
- 计算index方法:index = hash & (tab.length – 1)。
HashMap的初始值还要考虑加载因子:
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
cpu 100%问题排查步骤
用到的命令有ps、top、printf、jstack、grep。
-
第一步先找出Java进程ID,我部署在服务器上的Java应用名称为mrf-center:
root@ubuntu: ps -ef | grep mrf-center | grep -v grep root 21711 1 1 14:47 pts/3 00:02:10 java -jar mrf-center.jar -
第二步 top -Hp pid,找出该进程内最耗费CPU的线程
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为21742的线程,用:printf "%x\n" 21742得到21742的十六进制值为54ee。
-
第三步用 jstack 来输出进程21711的堆栈信息,然后根据线程ID的十六进制值grep:
root@ubuntu: jstack 21711 | grep 54ee "PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]

















 1987
1987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









