




 博客围绕JVM垃圾回收展开,介绍了RSet和卡表这两种空间换时间的数据结构。RSet记录对象代际引用关系,加速垃圾回收。G1以region为维度管理RSet,还介绍了记录引用关系的方法、G1的收集算法,分析了RSet需记录的引用关系及优化方式,以及RSet与卡表的关系和管理引用的方式。
博客围绕JVM垃圾回收展开,介绍了RSet和卡表这两种空间换时间的数据结构。RSet记录对象代际引用关系,加速垃圾回收。G1以region为维度管理RSet,还介绍了记录引用关系的方法、G1的收集算法,分析了RSet需记录的引用关系及优化方式,以及RSet与卡表的关系和管理引用的方式。
试想一下,当在ygc时,我们需要扫描整个新生代。当新生代的对象被老年代引用,则此对象就不能回收。那么怎么判断这点呢,总不能扫描老年代吧。所以这里需要使用空间换时间的数据结构:RSet和卡表。
卡表:一种points-out结构,每个card记载有没有引用别的heap分区,它是全局表,对于一些热点card,会放入Hot card cache,它也是全局表;
RSet:一种points-in结构,在卡表基础上实现,每个Heap一个,用来记录别的Heap指向自己的指针,并标记这些指针在卡表哪些范围内。
记忆集RSet是一种抽象概念,记录对象在不同代际之间的引用关系,目的是为了加速垃圾回收的速度。JVM使用根对象引用的收集算法,即从根集合出发,标记所有存活的对象,然后遍历对象的每一个字段继续标记,直到所有的对象标记完毕。在分代GC中,我们知道新生代和老生代处于不同的收集阶段,如果还是按照这样的标记方法,既不合理也没必要。假设我们只收集新生代,我们把老生代全部标记,但是并没有收集老生代,浪费了时间。同理,在收集老生代时有同样的问题。当且仅当,我们要进行Full GC才需要做全部标记。所以算法设计者做了这样的设计,用一个RSet记录从非收集部分指向收集部分的指针的集合,而这个集合描述对象的引用关系。
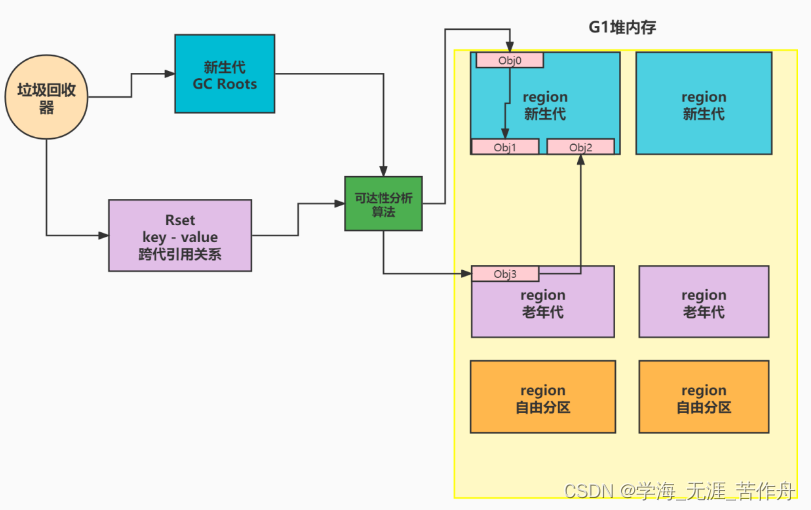
记忆集的维度应该是什么?针对新生代和老年代各搞一个?还是针对region,每个region都搞一个?
对于G1来说,它是以region为最小内存管理维度的,它的RSet记忆集的维度是对每一个region,都搞一块儿内存,存储region里面所有的对象被引用的引用关系。
针对region这个维度,是因为,每次回收之后,老年代,新生代,大对象区域的region可能都会变化,所以,如果说,对每个分代都搞一份儿的话,不太合理,因为region不断的在变化,同时也会有并发问题,效率问题。
同时,除了新生代的回收是需要选择所有新生代的region,老年代的回收,是需要找性价比高的region来回收的,也就是选择一部分去回收,那么选择一部分回收的时候,还要去整个分代对应的这么一大块儿引用关系数据,去做遍历,筛选,才能拿到需要的数据。
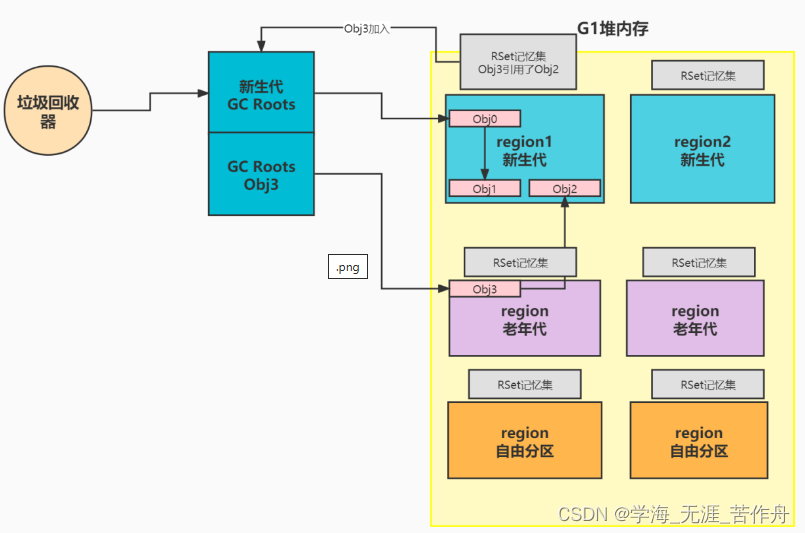
通常有两种方法记录引用关系,第一成为Point Out,第二是Point in。如ObjA.Field=ObjB,对于Point out来说在ObjA的RSet中记录ObjB的地址,对于Point in来说在ObjB的RSet中记录ObjA的地方,这相当于一种反向引用。这两者的区别在于处理有所不同,Point Out记录操作简单,但是需要对RSet做全部扫描;Point In记录操作复杂,但是在标记扫描时直接可以找到有用和无用的对象,不需要额外的扫描,因为RSet里面的对象可以认为就是根对象。
在G1中提供了3种收集算法。新生代回收、混合回收和Full GC。新生代回收总是收集所有新生代分区,混合回收会收集所有的新生代分区以及部分老生代分区,而Full GC则是对所有的分区处理。根据这个思路,我们首先分析一些不同分区之间的RSet应该如何设计。分区之间的引用关系可以归纳为:
- 分区内部有引用关系。
- 新生代分区到新生代分区之间有引用关系。
- 新生代分区到老生代分区之间有引用关系。
- 老生代分区到新生代分区之间有引用关系。
- 老生代分区到老生代分区之间有引用关系。
这里的引用关系指的是分区里面有一个对象存在一个指针指向另一个分区的对象。针对这5种情况,最简单的方式就是在RSet中记录所有的引用关系,但这并不是最优的设计方案。因为使用RSet进行回收实际上有两个重大的缺点:
- 需要额外内存空间;这一部分通常是JVM最大的额外开销,一般在1%~20%之间。
- 可能导致浮动垃圾;由于根据RSet回收,而RSet里面的对象可能已经死亡,这个时候被引用对象会被认为是活跃对象,实质上它是浮动垃圾。
所以有必要对RSet进行优化,根据垃圾回收的原理,我们来逐一分析哪些引用关系是需要记录在RSet中:
- 分区内部有引用关系,无论是新生代分区还是老生代分区内部的引用,都无需记录引用关系,因为回收的时候是针对一个分区而言,即这个分区要么被回收要么不回收,回收的时候会遍历整个分区,所以无需记录这种额外的引用关系。
- 新生代分区到新生代分区之间有引用关系,这个无需记录,原因在于G1的这3中回收算法都会全量处理新生代分区,所以它们都会被遍历,所以无需记录新生代到新生代之间的引用。
- 新生代分区到老生代分区之间有引用关系,这个无需记录,对于G1中YGC针对的新生代分区,无需这个引用关系,混合GC发生的时候,G1会使用新生代分区作为根,那么遍历新生代分区的时候自然能找到老生代分区,所以也无需这个引用,对于FGC来说更无需这个引用关系,所有的分区都会被处理。
- 老生代分区到新生代分区之间有引用关系,这个需要记录,在YGC的时候有两种根,一个就是栈空间/全局空间变量的引用,另外一个就是老生代分区到新生代分区的引用。
- 老生代分区到老生代分区之间有引用关系,这个需要记录,在混合GC的时候可能只有部分分区被回收,所以必须记录引用关系,快速找到哪些对象是活跃的。
前面已经介绍过卡表和位图,那么RSet与卡表、位图又是什么关系?我们已经知道RSet记录引用者的地址。我们可以使用RSet直接记录对象的地址,带来的问题就是RSet会急剧膨胀,一个位可以表示512个字节区域到被引用区的关系。RSet用分区的起始地址和位图表示一个分区所有的引用信息。这里结合RSet从一个具体的例子来看看他们是如何工作。假定有两个新生代分区YHR,两个老生代分区OHR。为了方便,定义:obj1_YHR1.Field1=Obj2_HYR1,表示对象obj1在新生代分区YHR1,它有一个字段Field1指向对象obj2在新生代分区YHR2。
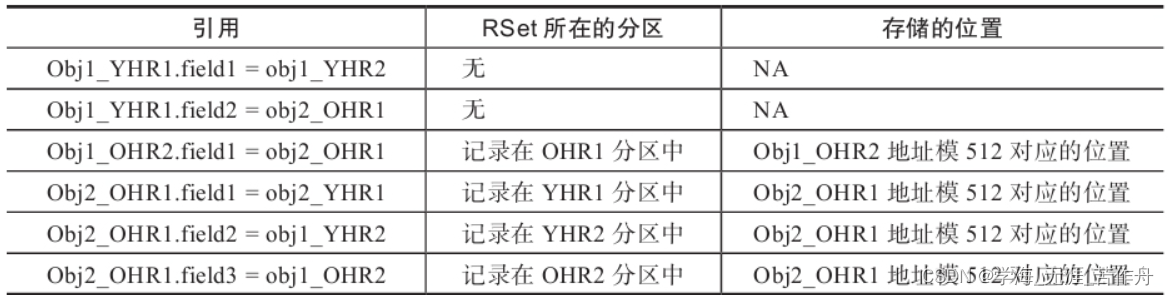
下图是G1中关于RSet和卡表的整体概述:
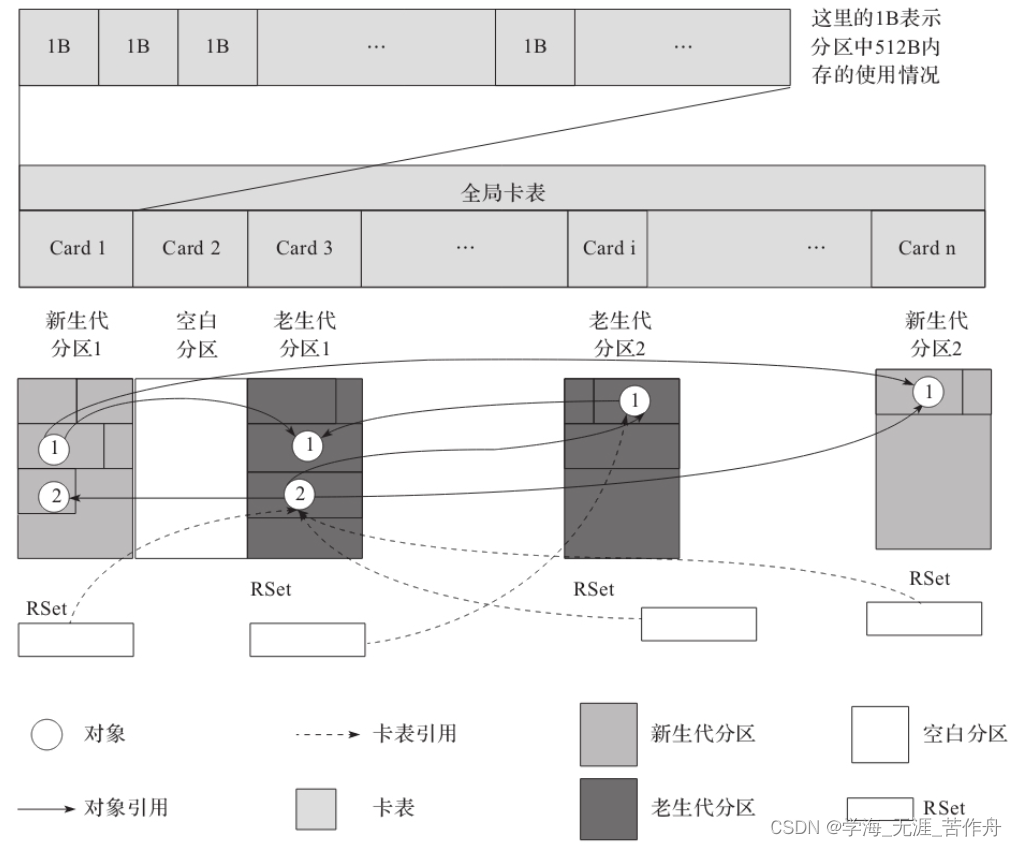
在这里需要注意一点。卡表是一个全局表,这个卡表的作用并不是记录引用关系,而是记录该区域中对象垃圾回收过程中的状态信息,且能描述对象所处的内存区域块,它能快速描述内存的使用情况,卡表在后文中还会有涉及。RSet里面有足够的信息定位到引用对象所在分区的块中,下面将详细介绍RSet。在G1回收器里面,使用了Point In的方法。算法可以简化为找到需要收集的分区HeapRegion集合,所以YGC扫描Root Set和RSet就可以了。
在G1回收器里面,使用了Point In的方法。算法可以简化为找到需要收集的分区HeapRegion集合,所以YGC扫描Root Set和RSet就可以了。在线程运行过程中,如果对象的引用发生了变化(通常就是赋值操作),就必须要通知RSet,更改其中的记录,但对于一个分区来说,里面的对象有可能被很多分区所引用,这就要求这个分区记录所有引用者的信息。为此G1回收器使用了一种新的数据结构PRT(Per region Table)来记录这种变化。每个HeapRegion都包含了一个PRT,它是通过HeapRegion里面的一个结构HeapRegionRemSet获得,而HeapRegionRemSet包含了一个OtherRegionsTable,也就是我们所说的PRT,代码如下所示:
src\share\vm\gc_implementation\g1\heapRegion.hpp
class HeapRegion: public G1OffsetTableContigSpace {
friend class VMStructs;
private:
// The remembered set for this region.
// (Might want to make this "inline" later, to avoid some alloc fa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8417
8417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









